Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network(SRGAN)
1.1、相关工作
1.1.1、图像超像素
为了重构真实纹理细节同时避免边缘伪影,Tai等人[52]将基于梯度剖面先验[50]的边缘导向的SR算法与基于学习的细节综合的好处组合。Zhang等人[70]等人提出一个多尺度字典来捕获不同尺度相似图像patches之间的冗余。为了恢复地标图像,Yue等人[67]从网页中检索和相似内容的相关HR图像,提出一个结构感知的匹配标准来对齐。(2013年之前的方法)
邻近嵌入方法扩大LR图像patch,是通过在低维流形中寻找相似LR训练patches,然后为重构将它们对应的HRpatches组合[54, 55]。在Kim和Kwon[35]中,作者强调了邻近方法倾向于过拟合,用内核岭回归来形成了样本对更一般的map。回归问题也可以用高斯过程回归、树或Random Forests来解决。在Dai等人的[6]中,学习了很多特定pach的回归器,在测试过程中选择最合适的回归器。
近些年,基于卷积神经网络(CNN)的SR算法已经展现了出色的效果。在Wang等人的[59]中,作者编码一个系数表达先验知识到他们的基于学习迭代收缩和阈值算法(LISTA)的前向网络结构。Dongle等人[9, 10]采用bicubic插值来扩大输入图像,端对端训练一个三层深度全卷积网络并且获得最好的SR效果。后来,直接让网络学习扩大滤波器可以进一步在精度和速度上增加效果[11, 48, 57]。有了他们的深度循环卷积网络(DRCN),Kim等人[34]提出一个高性能结构,它允许长期像素依赖且保持模型参数量很小。与我们论文特别相关的是Johnson等人【33】和Bruna等人【5】的工作,他们依赖于很类似于感知相似性的loss函数来恢复视觉上更具说服力的HR图像。
1.1.2、卷积神经网络的设计
Krizhevsky等人的工作获得成功后,很多计算机视觉问题中优秀的方法都是依赖于设计特定的CNN结构。
更深的网络可能很难训练,但是有潜力后续增加网络的精度,由于它们允许非常高复杂度的模型映射[49, 51]。为了有效的训练这些更深的网络结构,通常使用BN来消除中间的协变量偏移。更深的网络结构也展现了可以提升SISR的性能,如Kim等人[34]设计的循环CNN表现出最好的结果。另外一个很强大的简化深度CNNs的训练的设计选择是最近提出来的残差块和跳跃连接的内容。跳跃连接缓解了模型等价映射的网络结构,它本质是微不足道的,但是,隐含着对表达卷积核是巨大的。
在SISR的背景下,学习扩大滤波器在精度和速度都是很好的[11, 48, 57]。这是在Dong等人[10]之上的改进,在输入到CNN之间,用bicubic插值将LR图像扩大。
(网络加深、加BN层、残差网路、skip-connection、用网络扩大)
1.1.3、loss函数
像素级别的loss函数如MSE努力处理固有的不确定性,恢复丢失的高频细节如纹理:最小化MSE鼓励找到似是而非的解的像素级别均值,这通常是过于平滑的且缺乏感知上质量[42, 33, 13, 5]。感知质量上的变化在图2中用对应的PSNR证实。我们在图3中说明最小化MSE的问题,将有高纹理细节的多个潜在解平均来得到一个平滑的重构。
在Mathieu et al. [42] 和Denton et al. [7]中,针对图像生成的应用,作者采用了生成对抗网络(GANs)来处理这个问题。Yu和Porikli【66】增加对抗loss到像素级MSE loss来训练网路,用大扩大因子(8x)来恢复人脸图像。在Radford等人[44]中,GANs也用于无监督表达学习。用GANs学习一个流形到另一个的映射这样的想法是在Li和Wand的形式转换【38】和Yeh等人的图像修补中描述的。Bruna等人【5】最小化VGG19和分散网络中的特征空间的平方差。
Dosovitskiy和Brox用基于欧式距离的loss函数,它是在组合了对抗训练的神经网络的特征空间计算的。提出的loss允许视觉上更好的图像生成以及可以用于解决解码非线性特征表达的病态逆转问题。类似于这个工作,Johnson等人和Bruna等人提出使用从预训练VGG网络提取的特征代替低级别像素误差度量。特别地,作者用基于从VGG19网络提取的特征maps之间的欧式距离来表示loss函数。对于SR和艺术形式转化,都得到了视觉上具有说服力的结果。最近,Li和Wand也调研了在像素或VGG特征空间中比较和混合patch的效果。
1.2、贡献
GANs为生成高感知质量的视觉可接受的自然图像,提供一个强大的框架。GAN流程
在本文中,我们描述了第一个非常深的ResNet结构。我们的主要贡献是:
我们创造了高放大因子(4x)的图像SR领域的新的高度,用16个blocks深度Resnet(SRResNet)用MSE优化,PSNR和SSIM作为评测指标。
我们提出了SRGAN,它是一个基于GAN的网络,哦那个新的感知loss优化。这里我们将基于MSE的内容loss替换为在VGG网络的特征maps上计算的loss,它对像素空间的变化更具有不变性。
我们用来自三个公共基准数据集的图像的广泛平均意见分数测试确认了,对于高扩大因子(4x)的逼真SR图像的评估SRGAN明显是最好的方法。
我们在第二部分中具体介绍网络结构和感知loss。在第三部分中是在公共基准数据集上的定量评估和视觉插图。在第四部分论文进行了讨论,在第五部分包括附注。
2、方法
在SISR中,旨在用一个低分辨率的输入图像![]() 估计一个高分辨率、超分解图像
估计一个高分辨率、超分解图像![]() 。这里
。这里![]() 是高分辨率
是高分辨率![]() 的低分辨率版本。高分辨率图像仅仅在训练过程中用。在训练时,
的低分辨率版本。高分辨率图像仅仅在训练过程中用。在训练时,![]() 通过在
通过在![]() 上用高斯滤波器,然后进行下采样因为为r的下采样操作。对于C颜色通道的图像,我们用一个真值tensor来描述,
上用高斯滤波器,然后进行下采样因为为r的下采样操作。对于C颜色通道的图像,我们用一个真值tensor来描述,![]() 大小为
大小为![]() ,
,![]() 是
是![]() 。
。
我们的终极目标是训练一个生成函数G,它可以估计一个给定的LR输入图像的对应的HR副本。为了达到这个目的,我们训练一个生成器网络为参数是![]() 的前馈CNN
的前馈CNN![]() 。这里
。这里![]()
![]() 表示L层深度网络的权值和偏差,通过优化一个SR特定的loss函数
表示L层深度网络的权值和偏差,通过优化一个SR特定的loss函数![]() 来获得。对于训练图像
来获得。对于训练图像![]() ,对应
,对应![]() ,我们解为:
,我们解为:
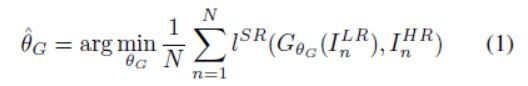
在本工作中我们将特别的设计一个感知loss![]() 作为作为几个loss部分的加权组合,模型来区分恢复SR图像所期望的特征。这个独特的loss函数在2.2中更详细的介绍。
作为作为几个loss部分的加权组合,模型来区分恢复SR图像所期望的特征。这个独特的loss函数在2.2中更详细的介绍。
2.1、对抗网络结构
根据Goodfellow等人[22]的研究,我们进一步定义了一个判断网络![]() ,我们以一种和
,我们以一种和![]() 交互的方式来优化它,从而解决对抗最小-最大问题:
交互的方式来优化它,从而解决对抗最小-最大问题:
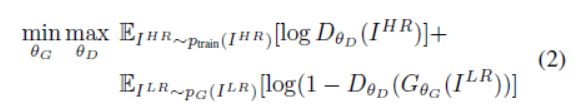
这个公式背后的大概思想是,它允许训练一个生成模型G,目的是来迷惑一个可微的训练来区分SR图像和真实图像的鉴别器D。带着这个目的,我们的生成器可以学习创造解决方案,可以和真实图像很相似,因此用D很难区分。
2.2、感知loss函数
2.2.1、内容loss
2.2.2、对抗loss
3、实验
3.1、数据和相似性度量
3.2、训练细节和参数
3.3、Mean opinion score (MOS) testing平均意见得分测试
3.4、内容loss的研究