计算机视觉项目实战(三)、基于词袋模型的场景识别 Scene Recognition with Bag of Words
基于词袋模型的场景识别 Scene Recognition with Bag of Words
- 项目要求
- 项目原理
- 1. 图像分类算法
- 2. 基于词袋模型的图像分类技术
- 3. 梯度方向直方图HOG特征提取算法
- 4. 词袋构建:K-means聚类算法
- 4.1. 大数据的聚类算法 Mini Batch K-Means
- 5. 分类器的构建:KNN分类算法
- 6. 分类器的构建:线性SVM多分类算法
- 主要内容
- 0. 具体操作流程->主函数
- 1. 图像特征表示
- 1.1. 图像的tiny特征表示
- 函数:get_tiny_images()
- 效果
- 1.2 图像的词袋模型构建
- 1.2.1 图像特征提取,以及词袋构建
- 函数:build_vocabulary(image_paths, vocab_size):
- 1.2.2 统计词频,构建图像直方图
- 函数get_bags_of_words(image_paths)
- 2. 分类器的构建
- 2.1. 使用KNN分类器进行特征分类
- 函数:nearest_neighbor_classify()
- 2.2. 使用SVM分类器进行特征分类
- 函数:svm_classify(train_image_feats, train_labels, test_image_feats)
- 结果展示
- 参考资料
项目要求
- 通过HOG特征提取和K-means实现图像的词袋化特征表示
- 训练SVM分类器和KNN分类器
- 实现基于词袋模型的场景识别

项目原理
1. 图像分类算法
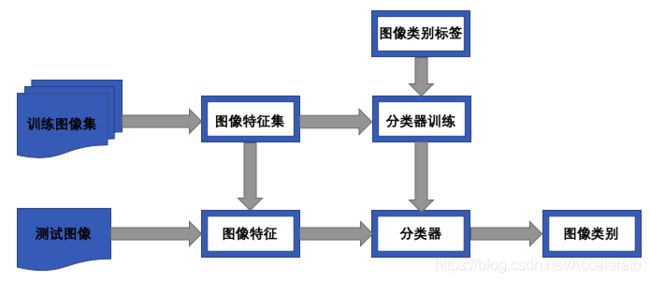
图像分类是机器视觉中一个重要的问题,其基本概念是:通过算法自动把图像划分到特定的概念类别中。图像分类问题可以描述为:给定若干个学习好的图像类别,对输入的新图像序列进行处理,并对其做出一个决策,判断一个已知的类别是否出现在数据中。图像分类算法分为训练和测试两个阶段,其基本流程如下图所示:
2. 基于词袋模型的图像分类技术
词袋模型最初用于文本分类中,然后逐步引入到了图像分类任务中。在文本分类中,文本被视为一些不考虑先后顺序的单词集合。而在图像分类中,图像被视为是一些与位置无关的局部区域的集合,因此这些图像中的局部区域就等同于文本中的单词了。在不同的图像中,局部区域的分布是不同的。因此,可以利用提取的局部区域的分布对图像进行识别。图像分类和文本分类的不同点在于,在文本分类的词袋模型算法中,字典是已存在的,不需要通过学习获得;而在图像分类中,词袋模型算法需要通过监督或非监督的学习来获得视觉词典。
基于词袋模型的图像分类算法一般分为四步:
- 对图像进行局部特征向量的提取。为了取得很好的分类效果,提取的特征向量需要具备不同程度的不变性,如旋转,缩放,平移等不变性(SIFT或HOG)
- 利用上一步得到的特征向量集,抽取其中有代表性的向量,作为单词,形成视觉词典;
- 对图像进行视觉单词的统计,一般判断图像的局部区域和某一单词的相似性是否超过某一阈值。这样即可将图像表示成单词的分布,即完成了图像的表示。
- 设计并训练分类器,利用图像中单词的分布进行图像分类。
3. 梯度方向直方图HOG特征提取算法
Histogram of Oriented Gridients,缩写为HOG,是目前计算机视觉、模式识别领域很常用的一种描述图像局部纹理的特征。
-
分隔图像。因为HOG是一个局部特征,所有需要把图像分割成很多块,然后对每一块计算HOG特征,分割方法有重叠切分(overlap)和不重叠切分(non-overlap)两种,这两种策略各有各的好处。
overlap可以防止对一些局部特征的切割,比如对于一张人脸图片,如果分割的时候正好把眼睛从中间切割并且分到了两个patch中,提取完HOG特征之后,这会影响接下来的分类效果,但是如果两个patch之间overlap,那么至少在一个patch会有完整的眼睛。overlap的缺点是计算量大,因为重叠区域的像素需要重复计算。
再说non-overlap,缺点就是上面提到的,有时会将一个连续的物体切割开,得到不太好的HOG特征,优点是计算量小,尤其是与Pyramid(金字塔)结合时,这个优点更为明显。
-
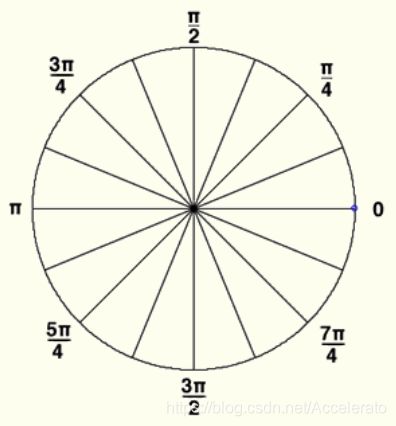
计算每个区块的方向梯度直方图。利用任意一种梯度算子,例如:sobel,laplacian等,对每个patch进行卷积,计算得到每个像素点处的梯度方向和幅值。再将360度(2*PI)根据需要分割成若干个分,例如:分割成12分,每分包含30度,整个直方图包含12维。然后根据每个像素点的梯度方向,利用双线性内插法将其幅值累加到直方图中。
4. 词袋构建:K-means聚类算法
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。算法接受一个未标记的数据集,是一种无监督学习。
假设要把数据通过k-means算法分成K个类,可以分为以下4个步骤:
- 随机选取k个点,作为聚类中心;
- 计算每个点分别到k个聚类中心的距离,然后将该点分到最近的聚类中心,这样就行成了k个簇;
- 再重新计算每个簇的质心(均值);
- 重复以上2~4步,直到质心的位置不再发生变化或者达到设定的迭代次数。
4.1. 大数据的聚类算法 Mini Batch K-Means
在项目中,因为训练样本大,特征数目较多,采用传统的K-means进行聚类会导致计算时间过长,所以考虑使用Mini Batch KMeans。Mini Batch KMeans是一种能尽量保持聚类准确性下但能大幅度降低计算时间的聚类模型。
与K均值算法相比,数据的更新是在每一个小的样本集上。对于每一个小批量,通过计算平均值得到更新质心,并把小批量里的数据分配给该质心,随着迭代次数的增加,这些质心的变化是逐渐减小的,直到质心稳定或者达到指定的迭代次数,停止计算。由于计算样本量少,所以会相应的减少运行时间,而且准确度下降的并不明显,所以在处理大样本时常常采用该方法进行聚类。
5. 分类器的构建:KNN分类算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。KNN属于懒惰学习,没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。
思路是:如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
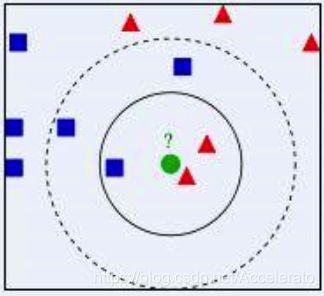
KNN分类算法一般具有以下4个步骤:
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类.
6. 分类器的构建:线性SVM多分类算法
支持向量机分类器(Support Vector Classifier)最开始用于解决二分类问题,基本思想是是根据训练样本的分布,将样本一分为二,即它只回答属于正类还是负类的问题。决定分类边界位置的样本并不是所有训练数据,是其中的两个类别空间的间隔最小的两个不同类别的数据点,即“支持向量”。
在面对多分类问题,我们设想的是用多个超平面把空间划分为多个区域,每个区域对应一个类别,这一看测试样本落在哪个区域就知道他的分类。但是这种一次性求解的方法计算量太大,无法实践,于是便退而求其次,想到采用“一类对其余”的方法,这样每次仍然解决一个二分类问题,一个类别训练一个分类器。这种方法好处是每个优化问题规模较小,分类速度快,但是缺点是容易出现分类重叠和不可分类现象:多个分类器都说属于自己的类别或每个分类器都说不属于自己的类别。
于是将负类变成一次只选一个类,这样便成了最原始的一对一分类问题,但这样分类器的数目会平方级增多,当有k个类别时,分类器应该有k*(k-1)/2个。而且这种方法仍然存在分类重叠现象。
于是想方法改变分类策略,我们采用DAG SVM来组织分类器。具体策略如下图所示。
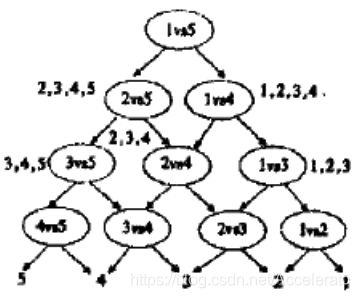
先问分类器"1还是5?",如果是5,再问分类器“2还是5?”这种方法的优点是分类速度快,没有分类重叠和不可分类现象。
主要内容
0. 具体操作流程->主函数
def projSceneRecBoW():
'''
Step 0: 初始化操作(选择特征提取器,分类器和数据文件路径,并设置类别名称和训练参数)
'''
#FEATURE = 'tiny image'
#FEATURE = 'bag of words'
FEATURE = 'tiny image'
#CLASSIFIER = 'nearest neighbor'
#CLASSIFIER = 'support vector machine'
CLASSIFIER = 'nearest neighbor'
data_path = '../data/'
categories = ['Kitchen', 'Store', 'Bedroom', 'LivingRoom', 'Office',
'Industrial', 'Suburb', 'InsideCity', 'TallBuilding', 'Street',
'Highway', 'OpenCountry', 'Coast', 'Mountain', 'Forest']
abbr_categories = ['Kit', 'Sto', 'Bed', 'Liv', 'Off', 'Ind', 'Sub',
'Cty', 'Bld', 'St', 'HW', 'OC', 'Cst', 'Mnt', 'For']
#每个类别的训练集和测试集的大小
num_train_per_cat = 100
# 得到4个1500个元素的列表,分别存储了训练集每张图片的相对地址,测试集每张图片的相对地址,训练集每张图片的类别标签,测试集每张图片的类别标签
print('Getting paths and labels for all train and test data.')
train_image_paths, test_image_paths, train_labels, test_labels = \
get_image_paths(data_path, categories, num_train_per_cat)
'''
Step 1: 得到每张图像的特征
'''
print('Using %s representation for images.' % FEATURE)
if FEATURE.lower() == 'tiny image':
# 若使用微图像特征提取方法,每张图像会返回一个256*1的特征列表,所以训练集和测试集各得到一个1500*256的特征矩阵。
train_image_feats = get_tiny_images(train_image_paths)
test_image_feats = get_tiny_images(test_image_paths)
elif FEATURE.lower() == 'bag of words':
if not os.path.isfile('vocab.npy'):
#词袋数据文件,由build_vocabulary()函数生成,需要耗费大量时间,所以以生成则直接调用。
print('No existing visual word vocabulary found. Computing one from training images.')
vocab_size = 200 #词袋大小
#构建词袋
vocab = build_vocabulary(train_image_paths, vocab_size)
np.save('vocab.npy', vocab)
#训练集和测试集图片的词袋直方图表示
train_image_feats = get_bags_of_words(train_image_paths)
test_image_feats = get_bags_of_words(test_image_paths)
elif FEATURE.lower() == 'placeholder':
train_image_feats = []
test_image_feats = []
else:
raise ValueError('Unknown feature type!')
'''
Step 2: 通过分类器训练测试集图像并进行分类,返回一个N*1的列表,其中N是测试集大小,存储了与之前定义的categories对应的类别。
'''
print('Using %s classifier to predict test set categories.' % CLASSIFIER)
if CLASSIFIER.lower() == 'nearest neighbor':
predicted_categories = nearest_neighbor_classify(train_image_feats, train_labels, test_image_feats)
elif CLASSIFIER.lower() == 'support vector machine':
predicted_categories = svm_classify(train_image_feats, train_labels, test_image_feats)
elif CLASSIFIER.lower() == 'placeholder':
#为每张图片随机分类
random_permutation = np.random.permutation(len(test_labels))
predicted_categories = [test_labels[i] for i in random_permutation]
else:
raise ValueError('Unknown classifier type')
'''
## Step 3:结果可视化,该函数项目本身已经提供。
'''
create_results_webpage2( train_image_paths, \
test_image_paths, \
train_labels, \
test_labels, \
categories, \
abbr_categories, \
predicted_categories, \
FEATURE, \
CLASSIFIER)
1. 图像特征表示
我们通过两种相互独立的手段获取图像的特征,第一种手段是直接获得图像的tiny特征,优点是速度快,缺点是精度差,最后的分类准确率大于在20%左右,用来对比衬托出词袋模型的高准确率。第二种手段就是通过构建词袋模型,具体过程在下面会结合相关函数介绍,分类准确率在60%左右,相比于tiny特征有很大提升,缺点是训练时间较长。
1.1. 图像的tiny特征表示
微型图像表征具有理解容易,实现简单等优点。Torralba等人的微图像特征表示技术可以在最小的尺度空间内表示原始图像的特征。一个简单的做法是把原图像缩小到固定像素(这里我设置成16*16像素)并进行归一化操作,最后进行一维输出。
函数:get_tiny_images()
def get_tiny_images(image_paths):
N = len(image_paths)
size = 16
tiny_images = []
for each in image_paths:
image = Image.open(each)
image = image.resize((size, size))
image = (image - np.mean(image))/np.std(image)
image = image.flatten()
tiny_images.append(image)
tiny_images = np.asarray(tiny_images)
return tiny_images
效果
原始图像,微小化图像,归一化图像依次如下图所示。



1.2 图像的词袋模型构建
具体操作过程中主要有以下几步:
- 利用SIFT或者HOG算法,从训练集的每张图像中提取局部特征(一个图像大约有几十个),每一类图片、每一张图片所有的局部特征都聚集在一起。
- 利用K-means对训练集的局部特征进行聚类,聚成k(项目中为200)类,合并相近的特征,构成一个视觉词汇(就是每一类的中心),至此,我们就得到了一个包含K个词汇的单词表。
- 利用单词表中的词汇表示图像,具体过程见1.2.2
1.2.1 图像特征提取,以及词袋构建
函数:build_vocabulary(image_paths, vocab_size):
功能:训练集图片的HOG特征提取,使用K-means对提取特征进行聚类后返回特征中心。
def build_vocabulary(image_paths, vocab_size):
image_list = [imread(file) for file in image_paths]
cells_per_block = (2, 2)
z = cells_per_block[0]
pixels_per_cell = (4, 4)
feature_vectors_images = []
for image in image_list:
feature_vectors = hog(image, feature_vector=True, pixels_per_cell=pixels_per_cell,cells_per_block=cells_per_block, visualize=False)
feature_vectors = feature_vectors.reshape(-1, z*z*9)
feature_vectors_images.append(feature_vectors)
all_feature_vectors = np.vstack(feature_vectors_images)
kmeans = MiniBatchKMeans(n_clusters=vocab_size, max_iter=500).fit(all_feature_vectors) # change max_iter for lower compute time
vocabulary = np.vstack(kmeans.cluster_centers_)
return vocabulary
具体步骤:
-
基于scikit-image的HOG特征提取
相关参数:
-> image: input image, 输入图像
-> feature_vector: 将输出转换为一维向量.
-> pixels_per_cell : 每个cell的像素数, 是一个tuple类型数据,本项目中为(4,4)
-> cell_per_block : 每个BLOCK内有多少个cell, tuple类型, 本项目中为(2,2), 意思是将block均匀划分为2x2的块
-> visualise: 是否输出梯度图输入图像和梯度效果图如下所示:

-
基于scikit-image的mini batch K-means特征聚类
相关参数:
-> n_clusters:整形,缺省值=8 ,生成的聚类数,即产生的质心(centroids)数。
-> max_iter:整形,缺省值=300 ,执行一次k-means算法所进行的最大迭代数。
方法:
-> fit(X[,y]): 计算k-means聚类。
1.2.2 统计词频,构建图像直方图
在上一步构建完词典后,下面通过该特征词典,分别统计训练集和测试集中每幅图像的词频。
具体做法: 我们把之前每一个图像分割成很多的patch,现在统计每一个patch和前面聚类得到的每一个中心的距离。离哪个质心近,直方图中相对应的bin就加1,计算完这幅图像所有的patch后对直方图进行归一化(/L2),之后图像就可以用这个直方图进行表示了(images_histograms[i] = histogram)
在所有图像计算完成之后,就可以进行分类了。
函数get_bags_of_words(image_paths)
def get_bags_of_words(image_paths):
vocab = np.load('vocab.npy')
print('Loaded vocab from file.')
vocab_length = vocab.shape[0]
image_list = [imread(file) for file in image_paths]
# Instantiate empty array
images_histograms = np.zeros((len(image_list), vocab_length))
cells_per_block = (2, 2) # Change for lower compute time
z = cells_per_block[0]
pixels_per_cell = (4, 4) # Change for lower compute time
feature_vectors_images = []
for i, image in enumerate(image_list):
feature_vectors = hog(image, feature_vector=True, pixels_per_cell=pixels_per_cell,cells_per_block=cells_per_block, visualize=False)
feature_vectors = feature_vectors.reshape(-1, z*z*9)
histogram = np.zeros(vocab_length)
distances = cdist(feature_vectors, vocab)
closest_vocab = np.argsort(distances, axis=1)[:,0]
indices, counts = np.unique(closest_vocab, return_counts=True)
histogram[indices] += counts
histogram = histogram / norm(histogram)
images_histograms[i] = histogram
return images_histograms
2. 分类器的构建
2.1. 使用KNN分类器进行特征分类
我们通过查找训练集图像的相应最似特征来预测测试图像的类别。对于任意给定的KNN参数K给出相对于测试集图像最近的K个邻居,并通过投票法返回最临近邻居的分类。
输入参数:
- 训练图像特征:一个n*d的numpy数组,n是训练集大小,d是特征向量维度。
- 训练图像标签:一个n*1的列表,记录了训练数据的真实分类标签。
- 测试图像特征:一个m*d的numpy数组,m是测试集大小,d是特征向量维度。
返回:
一个m*1的numpy数组,表示测试集中每个图片的预测类别。
函数内容:
- 获取每个测试图像特征与每个训练图像特征之间的距离,这里使用了欧式距离,输入两个d* n的矩阵(d是每个图片特征数,n是图片数)返回n* n的矩阵,表示测试集每个图片和训练集每个图片之间的距离。
- 找出与每个测试图像距离最短的k个训练集图片。
- 确定这k个训练集图片的类别标签。
- 用投票法选出最常见的标签,作为该测试图片的预测类别。
函数:nearest_neighbor_classify()
def nearest_neighbor_classify(train_image_feats, train_labels, test_image_feats):
k = 5;
distances = cdist(test_image_feats, train_image_feats, 'euclidean')
sorted_indices = np.argsort(distances, axis=1)
knns = sorted_indices[:,0:k]
labels = np.zeros_like(knns)
get_labels = lambda t: train_labels[t]
vlabels = np.vectorize(get_labels)
labels = vlabels(knns)
labels = mode(labels,axis=1)[0]
return labels
2.2. 使用SVM分类器进行特征分类
函数:svm_classify(train_image_feats, train_labels, test_image_feats)
输入参数:
- 训练图像特征:一个n*d的numpy数组,n是训练集大小,d是特征向量维度。
- 训练图像标签:一个n*1的列表,记录了训练数据的真实分类标签。
- 测试图像特征:一个m*d的numpy数组,m是测试集大小,d是特征向量维度。
返回:
一个m*1的numpy数组,表示测试集中每个图片的预测类别。
sklearn svm.LinearSVC参数说明:
-> random_state : 在随机数据混洗时使用的伪随机数生成器的种子。 如果是int,则random_state是随机数生成器使用的种子。
->tol : float, 公差停止标准。
def svm_classify(train_image_feats, train_labels, test_image_feats):
clf = LinearSVC(random_state=0, tol=1e-5)
clf.fit(train_image_feats, train_labels)
test_predictions = clf.predict(test_image_feats)
return test_predictions
结果展示
特征提取器:NULL
分类器:NULL
准确率:6.9%(纯随机)
特征提取器:Tiny
分类器:KNN
准确率:18.9%
特征提取器:Tiny
分类器:SVM
准确率:22.3%
特征提取器:BOW(HOG+K-means)
分类器:KNN
准确率:58.1%
特征提取器:BOW(HOG+K-means)
分类器:SVM
准确率:68.9%
参考资料
Introduction to Computer Vision
Scene Recognition with Bag of Words
基于词袋模型的图像分类算法
Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories
Histograms of oriented gradients for human detection
Learn OpenCV-Histogram of Oriented Gradients
SVM入门(十)将SVM用于多类分类