【Python网络爬虫整理记录 D:01】——JS混淆加密
内容为学习小帅b的Python教学整理而来
帅B老仙,法力无边ღ( ´・ᴗ・` )比心
简介
学会爬取静态页面的数据后,下面当然是学习爬取动态页面的数据。
-
什么是动态页面呢?
有时候我们再用requests抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但在使用requests得到的结果中却没有。这是因为requests获取的都是原始的HTML文档,而浏览器中的页面则是经过JavaScript处理数据后生成的结果,这些数据的来源有多种,可能是通过Ajax加载的,可能是包含在HTML文档中的,也可能是经过JavaScript和特定算法计算后生成的。
本篇整理记录爬取其中通过JavaScript混淆加密来渲染的页面
案例网站 有道翻译:http://fanyi.youdao.com/
发现问题
- 按照通常构建爬虫的方法
-
打开chrome开发者工具,刷新页面,分析页面

输入‘萌新’点击翻译后,右边的XHR栏中,出现一条类型为xhr的数据请求,点击查看后。
POST请求地址为:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
再看一下请求带过去的参数是哪些?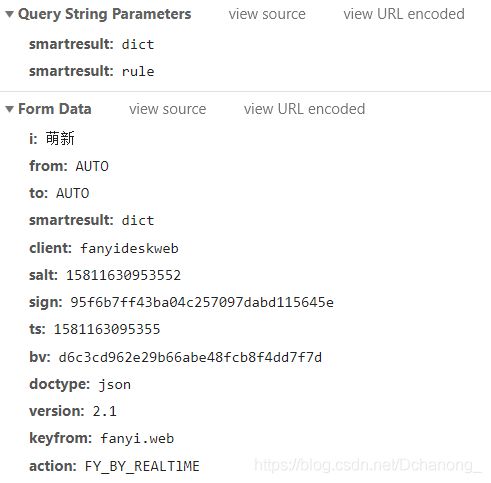
OK!!!其中 i 这个参数就是我们需要翻译的内容。那么直接复制请求头以及所需参数来构建requests请求。
-
构建requests请求
headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9", "Cookie": "[email protected]; JSESSIONID=" "aaaBxpJhsD9bZgfYbsJax; OUTFOX_SEARCH_USER_ID_NCOO=2138649720.2208343;" " ___rl__test__cookies=1581141334922", "Referer": "http://fanyi.youdao.com/", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 " "(KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" } url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule" form_data = { "i": '萌新', "from": "AUTO", "to": "AUTO", "smartresult": "dict", "client": "fanyideskweb", "salt": '15811630953552', "sign": '95f6b7ff43ba04c257097dabd115645e', "ts": '1581163095355', "bv": 'd6c3cd962e29b66abe48fcb8f4dd7f7d', "doctype": "json", "version": "2.1", "keyfrom": "fanyi.web", "action": "FY_BY_CLICKBUTTION" } response = requests.post(url=url, headers=headers, data=form_data) print(response.text)运行后结果:

程序返回了一个错误码!
分析问题
-
当我们尝试翻译不同的内容后,我们发现参数 salt 、sign、ts、bv是会变化的。那么就该思考变化的参数是怎么来的呢?
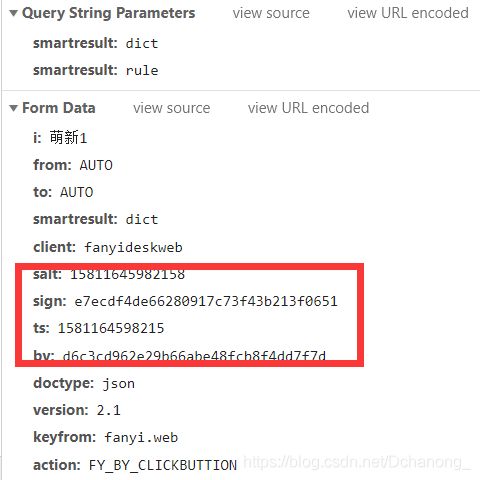
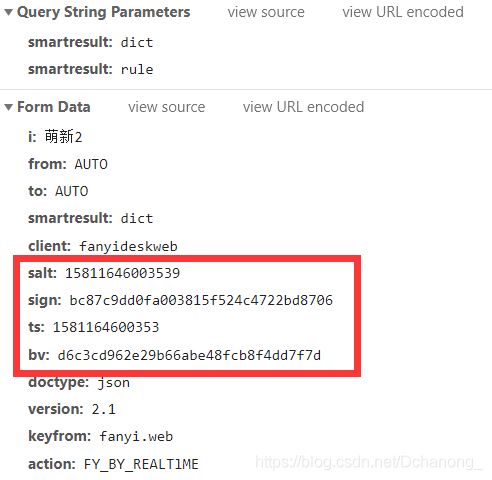
-
发现js文件
此时发现这个数据请求它指向 fanyi.min.js:1 这个js文件,我们点击这个js文件

出现这个界面,一堆的JavaScript代码,看也看不懂,我们点击左下角的{}让它展开。
-
使用chrome的打断点功能
在方框处添加之前数据请求的POST地址:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
然后,重新点击翻译按钮,断点成功屏幕会变为一半为灰色。 发现,行号重新定位在了7570行,展开右边 Call Stack,点击其中的
t.translate发现有我们需要的参数。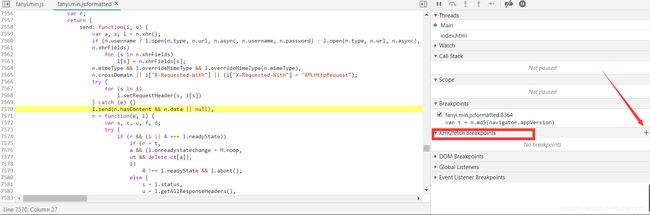

-
继续深入
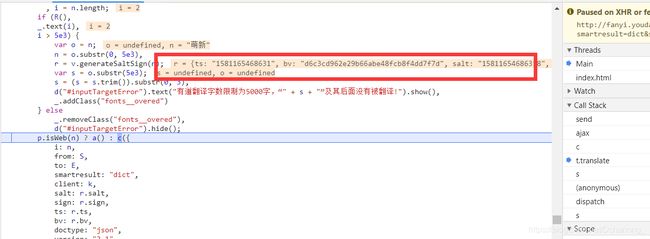
将鼠标放入generateSaltSign上面,出现了如图所示的链接,点击跳转至8363行。

-
此时我们就找到了需要的参数salt、sign、ts、bv的源头。
将鼠标点击8363行,出现蓝色的标记即为打上一个断点。然后点击上方图中所示按钮。再点击一下翻译按钮。
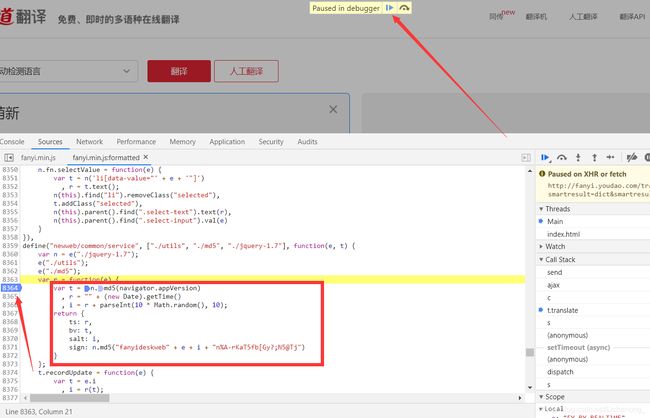

通过上面的操作,我们找出了4个参数的源头,正是通过上图中的JavaScript代码来计算出来的。下面就用python来构造这4个参数
解决问题
- 参数:ts(JavaScript代码中是这样的:r = “” + (new Date).getTime())
def get_ts():
ts = str(time.time() * 1000)
return ts
- 参数:bv(JavaScript代码中是这样的:t = n.md5(navigator.appVersion))
def get_bv():
appVersion = "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
m = hashlib.md5()
m.update(appVersion.encode("utf-8"))
bv = m.hexdigest()
return bv
- 参数:salt(JavaScript代码中是这样的:i = r + parseInt(10 * Math.random(), 10))
def get_salt():
salt = str(time.time() * 1000) + str(random.random() * 10)
return salt
- 参数:sign(JavaScript代码中是这样的:n.md5(“fanyideskweb” + e + i + “n%A-rKaT5fb[Gy?;N5@Tj”))
def get_sign(myinput):
a = "fanyideskweb"
b = myinput
c = get_salt()
d = "n%A-rKaT5fb[Gy?;N5@Tj"
str_data = a + b + c + d
m = hashlib.md5()
m.update(str_data.encode("utf-8"))
sign = m.hexdigest()
return sign
- 完整代码:
import requests
import time
import json
import hashlib
import random
def get_ts():
ts = str(time.time() * 1000)
return ts
def get_bv():
appVersion = "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
m = hashlib.md5()
m.update(appVersion.encode("utf-8"))
bv = m.hexdigest()
return bv
def get_salt():
salt = str(time.time() * 1000) + str(random.random() * 10)
return salt
def get_sign():
a = "fanyideskweb"
b = "萌新"
c = get_salt()
d = "n%A-rKaT5fb[Gy?;N5@Tj"
str_data = a + b + c + d
m = hashlib.md5()
m.update(str_data.encode("utf-8"))
sign = m.hexdigest()
return sign
def get_request():
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "[email protected]; JSESSIONID="
"aaaBxpJhsD9bZgfYbsJax; OUTFOX_SEARCH_USER_ID_NCOO=2138649720.2208343;"
" ___rl__test__cookies=1581141334922",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
form_data = {
"i": '萌新',
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": get_salt(),
"sign": get_sign(),
"ts": get_ts(),
"bv": get_bv(),
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_CLICKBUTTION"
}
response = requests.post(url=url, headers=headers, data=form_data)
print("翻译结果是:" + str(json.loads(response.text)['translateResult'][0][0]['tgt']))
if __name__ == '__main__':
get_request()
扩展
既然,我们能找到这些参数的规律,我们可以打包成 .exe 可执行文件做成翻译软件,分享给身边的小伙伴学习交流使用!!!
参考:Python中将.py文件打包成.exe可执行文件的简单方法