Accurate Image Super-Resolution Using Very Deep Convolutional Networks论文分析
Accurate Image Super-Resolution Using Very Deep Convolutional Networks
- 论文地址
- 简介
- 模型图
- 补充说明
- 模型框架
- 训练的策略:
- 残差学习Residual-Learning
- Pytorch代码实现
- model.py
论文地址
简介
我们提出一个高精确度的单张图像超分辨率重建方法。我们的方法由VGG-net启发。
网络的深度对于超分精确度有着十分重要的的影响,最终网络模型为20层。通过许多小尺寸的卷积层相连,有效的利用了图像中的上下文信息,面对深度网络难以训练的问题,我们使用学习residuals,使用大的学习率、梯度剪裁来解决这个问题。最后,实验证明我们提出的方法十分有效。
指出SRCNN的不足指出:
1.It relies on the context of small image regions;
2.Second, training converges too slowly;
3.Third, the network only works for a single scale。
解决方法:
1.增加了感受野,在处理大图像上有优势,由SRCNN的(1313)变为(4141)。
2.采用残差图像进行训练,增大学习率,收敛速度变快,因为残差图像更加稀疏,更加容易收敛(换种理解就是LR携带低频信息,这些信息依然被训练到HR图像,然而HR图像和LR图像的低频信息相近,这部分花费了大量时间进行训练),相当于只对LR和HR的差值进行modelling。
3.考虑多个尺度,一个卷积网络可以处理多尺度问题。
模型图

补充说明
1.该论文利用残差网络,加深网络结构(20层),在图像的超分辨率上取得了较好的效果,感受野大小(2D+1)X(2D+1)
2.作者采取了残差学习,提高学习率来为梯度传输排除障碍,节省时间
3.输入图片的大小不一致,使得网络可以针对不同倍数的超分辨率操作,
4.卷积后补0使得图像大小保持一致.
卷积可以提高较大的感受野,感受野就是视野的意思,图片预测,如果利用一个像素点去推断一个像素点,那么是做不好的,所以就要用卷积,卷积使得可以根据NXN个像素去推断目标像素值,图像处理中大家普遍认为像素之间是有相关性的,所以根据更多的像素数据去推断目标像素,也是认为是一个提高效果的操作
一个5X5的图片利用3X3的卷积核,卷积2次,输出为1个1X1的像素,则这个输出结果考虑到了5X5的像素信息,也就是感受野为5X5。
但是传统的卷积操作会使图片通过逐步卷积,图像大小也越来越小,一个很小的图,首先不适合一个很深的网络(这会要求输入图片的size很大),
其次,如果采取传统的卷积操作,边界像素会因考虑的区域少,感受野小而导致结果较差,于是传统的做法是对卷积结果做一个裁剪,剪去边界区域,随之产生一个新的问题,裁剪后的图像(卷积后本来就很小了)变的更小,用论文原话来说就是:After cropping,the final image is too small to be visually pleasing.
于是对于边界问题,作者提出一个新的策略,就是每次卷积后,图像的size变小,但是,在下一次卷积前,对图像进行补0操作,恢复到原来大小,这样不仅解决了网络深度的问题,同时,实验证明对边界像素的预测结果也得到了提升。
模型框架
训练的策略:
1.采用残差的方式进行训练,避免训练过长的时间。
2.使用大的学习进行训练。
3.自适应梯度裁剪,将梯度限制在某一个范围,本文采用自适应梯度方法,将梯度限制在![]() ,其中γ是学习率。
,其中γ是学习率。
4.多尺度,多种尺度样本一起训练可以提高大尺度的准确率。

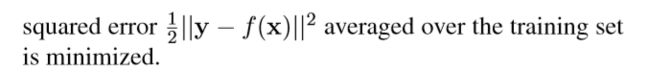
残差学习Residual-Learning
1.残差图像定义为HR图像减去LR图像
2.损失函数定义为残差图像与预测值的均方误差
3.损失层接受的输入为残差估计,网络输入LR和真值HR
4.损失通过计算重构图像和真值图像的欧氏距离得到
5.采用小批量梯度下降法来进行训练

Pytorch代码实现
model.py
import torch
import torch.nn as nn
from math import sqrt
class Conv_ReLU_Block(nn.Module):
def __init__(self):
super(Conv_ReLU_Block, self).__init__()
self.conv = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.conv(x))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18) # 一共20层,除了第一层和最后一层,中间的18层
self.input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d): # 如果是卷积层
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n)) # 权重初始化
def make_layer(self, block, num_of_layer):
layers = [] # 定义一个空列表,存放创建的每一层结构
for _ in range(num_of_layer):
layers.append(block()) # 从Net第三行可以看出,传入block对应的参数是Conv_ReLU_Block(),即一个拼接的Conv2d层和一个ReLU层
return nn.Sequential(*layers) # layers前面的*代表将列表通过非关键字参数的形式传入
def forward(self, x):
residual = x
out = self.relu(self.input(x)) # 首先通过第一层input layer
out = self.residual_layer(out) # 再通过18层相同的卷积层
out = self.output(out) # 最后通过最后一层output layer
out = torch.add(out, residual)
return out
11
1