SVM——(四)目标函数求解
在之前的两篇文章中[1][2]分别用两种方法介绍了如何求得目标优化函数,这篇文章就来介绍如何用拉格朗日对偶(Lagrange duality)问题以及SMO算法求解这一目标函数,最终得到参数。
本文主要分为如下部分:
1.构造广义拉格朗日函数 L ( w , b , α ) \mathcal{L}(w,b,\alpha) L(w,b,α)
2.关于参数 w , b w,b w,b,求 L \mathcal{L} L的极小值 W ( α ) W(\alpha) W(α)
3.使用SMO算法求 W ( α ) W(\alpha) W(α)的极大值
4.求解参数 w , b w,b w,b
其中2,3,4也是求解对偶问题的一般步骤。
1.构造广义拉格朗日函数 L ( w , b , α ) \mathcal{L}(w,b,\alpha) L(w,b,α)
由上文可知SVM最终的优化目标为:
min ω , b 1 2 ∣ ∣ ω ∣ ∣ 2 s. t. y i ( ω T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m (1.1) \begin{array}{l} \min_{\boldsymbol{\omega},b}\frac{1}{2}||\boldsymbol{\omega}||^2\\ ~\\ \textrm{s. t.}~ ~y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b)\geq 1,~~i = 1,2,...,m \end{array} \tag{1.1} minω,b21∣∣ω∣∣2 s. t. yi(ωTxi+b)≥1, i=1,2,...,m(1.1)
由此我们可以得到广义的拉格朗日函数为:
G e n e r a l i z e d L a g r a n g i a n \bf{Generalized\;Lagrangian} GeneralizedLagrangian
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 m α i [ y ( i ) ( w T x ( i ) + b ) − 1 ] s . t . g i ( w ) = − y ( i ) ( w T x ( i ) + b ) + 1 ≤ 0 (1.2) \begin{aligned} &\mathcal{L}(w,b,\alpha)=\frac{1}{2}||w||^2-\sum_{i=1}^m\alpha_i\large[y^{(i)}(w^Tx^{(i)}+b)-1]\\[2ex] &s.t.\;g_i(w)=-y^{(i)}(w^Tx^{(i)}+b)+1\leq0\tag{1.2} \end{aligned} L(w,b,α)=21∣∣w∣∣2−i=1∑mαi[y(i)(wTx(i)+b)−1]s.t.gi(w)=−y(i)(wTx(i)+b)+1≤0(1.2)
注:此处有两个参数 w , b w,b w,b,一个拉格朗日乘子向量 α \alpha α,且 α i ≥ 0 \alpha_i\geq0 αi≥0,因为只有这样才能满足 1 2 ∣ ∣ w ∣ ∣ 2 = max L \frac{1}{2}||w||^2=\max\mathcal{L} 21∣∣w∣∣2=maxL;(详见此处)
由对偶性:
d ∗ = max α , α i ≥ 0 min w , b L ( w , b , α ) = min w , b max α , α i ≥ 0 L ( ω , α , β ) = p ∗ (1.3) d^*=\max_{\alpha,\alpha_i\geq0}\min_{w,b}\mathcal{L}(w,b,\alpha)=\min_{w,b}\max_{\alpha,\alpha_i\geq0}\mathcal{L}(\omega,\alpha,\beta)=p^*\tag {1.3} d∗=α,αi≥0maxw,bminL(w,b,α)=w,bminα,αi≥0maxL(ω,α,β)=p∗(1.3)
可知,对偶问题 d ∗ d^* d∗与原始问题 p ∗ p^* p∗同解,但上述过程需满足KKT条件:
{ α i ≥ 0 ; g i ( w , b ) ≤ 0 ; α i g i ( w , b ) = 0 (1.4) \begin{aligned} \begin{cases} \alpha_i\geq0;\\[2ex]g_i(w,b)\leq0;\\[2ex]\alpha_ig_i(w,b)=0\tag{1.4}\end{cases} \end{aligned} ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧αi≥0;gi(w,b)≤0;αigi(w,b)=0(1.4)
于是,对于任意训练样本 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)),总有 α i = 0 \alpha_i=0 αi=0或者 α i g i ( w , b ) = 0 \alpha_ig_i(w,b)=0 αigi(w,b)=0。若 α i = 0 \alpha_i=0 αi=0,由下面 ( 2.1 ) (2.1) (2.1)可知,超平面为 0 x + b = 0 0x+b=0 0x+b=0,这就意味着与决策面与该样本点无关;若 α i > 0 \alpha_i>0 αi>0,则必有 y ( i ) ( w T x ( i ) + b ) = 1 y^{(i)}(w^Tx^{(i)}+b)=1 y(i)(wTx(i)+b)=1,也就是说该样本点是一个支持向量。这显示出一个重要性质:超平面仅仅与支持向量有关。
2.关于参数 w , b w,b w,b,求 L \mathcal{L} L的极小值 W ( α ) W(\alpha) W(α)
这一步同拉格朗日乘数法求极值一样,分别对 w , b w,b w,b求偏导,并令其为0:
∂ L ∂ w = w − ∑ i = 1 m α i y ( i ) x ( i ) = 0 w = ∑ i = 1 m α i y ( i ) x ( i ) (2.1) \begin{aligned} \frac{\partial \mathcal{L}}{\partial w}&=w-\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}=0\\[1ex] w&=\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}\tag{2.1} \end{aligned} ∂w∂Lw=w−i=1∑mαiy(i)x(i)=0=i=1∑mαiy(i)x(i)(2.1)
∂ L ∂ b = ∑ i = 1 m α i y ( i ) = 0 (2.2) \begin{aligned} \frac{\partial \mathcal{L}}{\partial b}&=\sum_{i=1}^m\alpha_iy^{(i)}=0\tag{2.2} \end{aligned} ∂b∂L=i=1∑mαiy(i)=0(2.2)
常用范数求导法则
将 ( 2.1 ) , ( 2.2 ) (2.1),(2.2) (2.1),(2.2)代入 ( 1.2 ) (1.2) (1.2)可知:
W ( α ) = min w , b L ( w , b , α ) = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m y ( i ) y ( j ) α i α j ( x ( i ) ) T x ( j ) (2.3) \begin{aligned} W(\alpha)=\min_{w,b}\mathcal{L}(w,b,\alpha)=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^my^{(i)}y^{(j)}\alpha_i\alpha_j(x^{(i)})^Tx^{(j)}\tag{2.3} \end{aligned} W(α)=w,bminL(w,b,α)=i=1∑mαi−21i,j=1∑my(i)y(j)αiαj(x(i))Tx(j)(2.3)
详细步骤:
L = 1 2 w T w − ∑ i = 1 m α i [ y ( i ) ( w T x ( i ) + b ) − 1 ] = 1 2 w T w − ∑ i = 1 m α i y ( i ) w T x ( i ) − ∑ i = 1 m α i y ( i ) b + ∑ i = 1 m α i = 1 2 w T w − w T ∑ i = 1 m α i y ( i ) x ( i ) − b ∑ i = 1 m α i y ( i ) + ∑ i = 1 m α i 代入(2.1)(2.2) 得 W ( α ) = 1 2 w T w − w T w + ∑ i = 1 m α i = ∑ i = 1 m α i − 1 2 w T w = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m α i α j y ( i ) y ( j ) ( x ( i ) ) T x ( j ) 其中: w T w = ∑ i = 1 m α i y ( i ) x ( i ) ⋅ ∑ j = 1 m α j y ( j ) x ( j ) = ∑ i , j = 1 m α i α j y ( i ) y ( j ) ( x ( i ) ) T x ( j ) = ∑ i = 1 m ∑ j = 1 m α i α j y ( i ) y ( j ) ( x ( i ) ) T x ( j ) \begin{aligned} \mathcal{L}&=\frac{1}{2}w^Tw-\sum_{i=1}^m\alpha_i\large[y^{(i)}(w^Tx^{(i)}+b)-1]\\[1ex] &=\frac{1}{2}w^Tw-\sum_{i=1}^m\alpha_iy^{(i)}w^Tx^{(i)}-\sum_{i=1}^m\alpha_iy^{(i)}b+\sum_{i=1}^m\alpha_i\\[1ex] &=\frac{1}{2}w^Tw-w^T\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}-b\sum_{i=1}^m\alpha_iy^{(i)}+\sum_{i=1}^m\alpha_i\\[1ex] &\text{代入(2.1)(2.2)}得\\[1ex] W(\alpha)&=\frac{1}{2}w^Tw-w^Tw+\sum_{i=1}^m\alpha_i\\[1ex] &=\sum_{i=1}^m\alpha_i-\frac{1}{2}w^Tw\\[1ex] &=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy^{(i)}y^{(j)}(x^{(i)})^Tx^{(j)}\\[1ex] \text{其中:} w^Tw&=\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}\cdot\sum_{j=1}^m\alpha_jy^{(j)}x^{(j)}\\[1ex] &=\sum_{i,j=1}^m\alpha_i\alpha_jy^{(i)}y^{(j)}(x^{(i)})^Tx^{(j)}\\[1ex] &=\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy^{(i)}y^{(j)}(x^{(i)})^Tx^{(j)} \end{aligned} LW(α)其中:wTw=21wTw−i=1∑mαi[y(i)(wTx(i)+b)−1]=21wTw−i=1∑mαiy(i)wTx(i)−i=1∑mαiy(i)b+i=1∑mαi=21wTw−wTi=1∑mαiy(i)x(i)−bi=1∑mαiy(i)+i=1∑mαi代入(2.1)(2.2)得=21wTw−wTw+i=1∑mαi=i=1∑mαi−21wTw=i=1∑mαi−21i,j=1∑mαiαjy(i)y(j)(x(i))Tx(j)=i=1∑mαiy(i)x(i)⋅j=1∑mαjy(j)x(j)=i,j=1∑mαiαjy(i)y(j)(x(i))Tx(j)=i=1∑mj=1∑mαiαjy(i)y(j)(x(i))Tx(j)
3.使用SMO算法求 W ( α ) W(\alpha) W(α)的极大值
由(2.3)我们可以得出如下优化问题:
max α W ( α ) = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m y ( i ) y ( j ) α i α j ( x ( i ) ) T x ( j ) s . t . α i ≥ 0 , i = 1 , . . . , m ∑ i = 1 m α i y ( i ) = 0 (3.1) \begin{aligned} \max_{\alpha} &W(\alpha)=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^my^{(i)}y^{(j)}\alpha_i\alpha_j(x^{(i)})^Tx^{(j)}\tag{3.1}\\[1ex] s.t. &\alpha_i\geq0,i=1,...,m\\[1ex] &\sum_{i=1}^m\alpha_iy^{(i)}=0 \end{aligned} αmaxs.t.W(α)=i=1∑mαi−21i,j=1∑my(i)y(j)αiαj(x(i))Tx(j)αi≥0,i=1,...,mi=1∑mαiy(i)=0(3.1)
之所以 ( 2.2 ) (2.2) (2.2)也会成为约束条件,是因为 W ( α ) W(\alpha) W(α)就是通过 ( 2.2 ) (2.2) (2.2)求解的出来的,是 W ( α ) W(\alpha) W(α)存在的前提。
现在我们的优化问题变成了如上的形式。对于这个问题,我们有更高效的优化算法,即序列最小优化(SMO)算法。我们通过这个优化算法能得到α,再根据α,我们就可以求解出w和b,进而求得我们最初的目的:找到超平面,即”决策平面”。
至于具体求解步骤,不急咱们先放着,到后面再来解决。
总结一句话:我们为啥使出吃奶的劲儿进行推导?因为我们要将最初的原始问题,转换到可以使用SMO算法求解的问题,这是一种最流行的求解方法。为啥用这种求解方法?因为它牛逼啊!
4. 求解 w , b w,b w,b
经过3.2求解出 α \alpha α之后,代入 ( 18 ) (18) (18)即可求解出 w w w;而b的求解公式为:
b = − 1 2 ( max i : y ( i ) = − 1 w T x ( i ) + min i : y ( i ) = + 1 w T x ( i ) ) b=-\frac{1}{2}\large(\max_{i:y^{(i)}=-1}w^Tx^{(i)}+\min_{i:y^{(i)}=+1}w^Tx^{(i)}) b=−21(i:y(i)=−1maxwTx(i)+i:y(i)=+1minwTx(i))
例如:
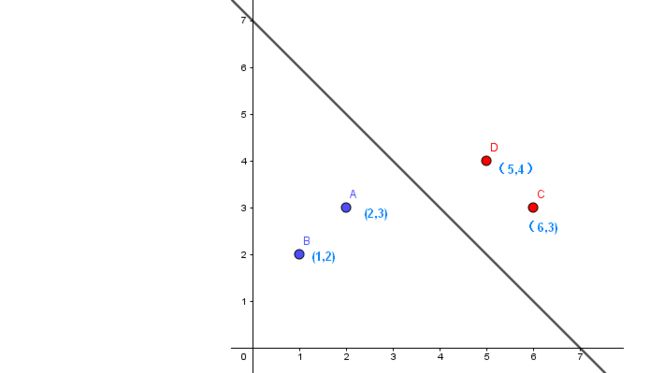
如图,红色为正样本( y = + 1 y=+1 y=+1),紫色为负样本( y = − 1 y=-1 y=−1),直线为 x 1 + x 2 − b = 0 x_1+x_2-b =0 x1+x2−b=0,则有:
max i : y ( i ) = − 1 w T x ( i ) = max ( 1 ∗ 2 + 1 ∗ 3 , 1 ∗ 1 + 1 ∗ 2 ) = 5 min i : y ( i ) = + 1 w T x ( i ) = min ( 1 ∗ 5 + 1 ∗ 4 , 1 ∗ 6 + 1 ∗ 3 ) = 9 b = − 1 2 ( 5 + 9 ) = − 7 \begin{aligned} &\max_{i:y^{(i)}=-1}w^Tx^{(i)}=\max(1*2+1*3,1*1+1*2)=5\\[1ex] &\min_{i:y^{(i)}=+1}w^Tx^{(i)}=\min(1*5+1*4,1*6+1*3)=9\\[1ex] &b=-\frac{1}{2}(5+9)=-7 \end{aligned} i:y(i)=−1maxwTx(i)=max(1∗2+1∗3,1∗1+1∗2)=5i:y(i)=+1minwTx(i)=min(1∗5+1∗4,1∗6+1∗3)=9b=−21(5+9)=−7
SVM——(七)SMO(序列最小最优算法)
SVM——(六)软间隔目标函数求解
SVM——(五)线性不可分之核函数
SVM——(四)目标函数求解
SVM——(三)对偶性和KKT条件(Lagrange duality and KKT condition)
SVM——(二)线性可分之目标函数推导方法2
SVM——(一)线性可分之目标函数推导方法1
参考:
- Python3《机器学习实战》学习笔记(八):支持向量机原理篇之手撕线性SVM
- 《机器学习》周志华
