前言
一、Series
二、Dataframe
1. 数据结构
2. 基本操作
(1)改变索引名
(2)增加一列
(3)排序
(4)删除一列
统计师的Python日记【第4天:欢迎光临Pandas】
前言
第3天我发了一个愿,学Python我的计划是:
Numpy → Pandas → 掌握一些数据清洗、规整、合并等功能 → 掌握类似与SQL的聚合等数据管理功能 → 能够用Python进行统计建模、假设检验等分析技能 → 能用Python打印出100元钱 → 能用Python帮我洗衣服、做饭 → 能用Python给我生小猴子......
我不是一名程序员,不写网站(以后可能会爬一爬网站的数据)、不搞支付系统、不处理多媒体、也不想当黑客,学Python主要目的就是玩数据、做分析,c成为一名进阶的统计师,以后可能的话搞一搞大数据。

在这样的角色设定之下,Pandas就一定要学好!Pandas被称为“Python Data Analysis Li”,它:
-
是基于Numpy的一种工具库;
-
提供了大量能使我们快速便捷处理数据的函数和方法;
-
最初被作为金融数据分析根据被开发出来;
-
集成了时间序列功能;
-
对缺失值的灵活处理能力;
-
......
Pandas有两种主要的数据结构:Series和Dataframe,前者是一维的,后者是多维的(表格型)。
一、Series
Series由一组数据和对应的索引组成,看个例子:
>>> a=pd.Series([7,6,5,4])
>>> a
0 7
1 6
2 5
3 4
dtype: int64
我们也可以用index=来指定索引:
>>> a=pd.Series([7,6,5], index=['shu','shuo','jun'])
>>> a
shu 7
shuo 6
jun 5
dtype: int64
“艾玛,这不有点像第1天学的字典吗?”我心想。

打开第一天的日记复习一下吧→【第1天:谁来给我讲讲Python?】
在操作上也像字典,对比一下a(字典)和b(Series):
>>> a=dict(name='jiayounet', age='27')
>>> a
{'age': '27', 'name': 'jiayounet'}
>>> a['age']
'27'
>>> 'age' in a
True
>>> 'haha' in a
False
>>> b=pd.Series([7,6,5], index=['shu','shuo','jun'])
>>> b
shu 7
shuo 6
jun 5
dtype: int64
>>> b['shu']
7
>>> 'shu' in b
True
>>> 'haha' in b
False
实际上,字典也确实可以直接变身成为Series!比如下面的字典a,储存了每个地区的平均工资,将其变为Series:
>>> a=dic{'Beijing':7000, 'Shanghai':8000, 'Shenzhen':7700, 'Nanjing':4700}
>>> a
{'Beijing': 7000, 'Shanghai': 8000, 'Nanjing': 4700, 'Shenzhen': 7700}
>>> pd.Series(a)
Beijing 7000
Nanjing 4700
Shanghai 8000
Shenzhen 7700
dtype: int64
也可以指定索引:
>>> pd.Series(a, index=['Beijing', 'Shanghai'])
Beijing 7000
Shanghai 8000
dtype: int64
二、DataFrame
1. 数据结构
DataFrame是一个表格型的数据结构。
下面的这组数据,储存了2015年中国人口前十的城市,以及它们拥有的人口
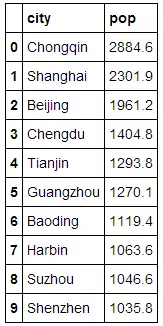
非常清爽的一张表,它~就~是~DataFrame!
上面是在ipython notebook中(一个嵌入在浏览器中的shell!)显示的,如果在Python自带的shell中,显示出来是这样的:

也不差啊!
那么怎么才能生成这样一张表呢?最常用的方法,是用字典生成:
>>> pop={'city':['Chongqin', 'Shanghai', 'Beijing', 'Chengdu', 'Tianjin', 'Guangzhou', 'Baoding', 'Harbin', 'Suzhou', 'Shenzhen'],
'pop':[2884.6, 2301.9, 1961.2, 1404.8, 1293.8, 1270.1, 1119.4, 1063.6, 1046.6, 1035.8]}
>>> pop
{'city': ['Chongqin', 'Shanghai', 'Beijing', 'Chengdu', 'Tianjin', 'Guangzhou', 'Baoding', 'Harbin', 'Suzhou', 'Shenzhen'], 'pop': [2884.6, 2301.9, 1961.2, 1404.8, 1293.8, 1270.1, 1119.4, 1063.6, 1046.6, 1035.8]}
>>> pop_DF=pd.DataFrame(pop)
>>> pop_DF
city pop
0 Chongqin 2884.6
1 Shanghai 2301.9
2 Beijing 1961.2
3 Chengdu 1404.8
4 Tianjin 1293.8
5 Guangzhou 1270.1
6 Baoding 1119.4
7 Harbin 1063.6
8 Suzhou 1046.6
9 Shenzhen 1035.8
也可以用columns=[]来指定某列:
>>> pop_DF=pd.DataFrame(pop, columns=['city'])
>>> pop_DF
city
0 Chongqin
1 Shanghai
2 Beijing
3 Chengdu
4 Tianjin
5 Guangzhou
6 Baoding
7 Harbin
8 Suzhou
9 Shenzhen
2. 基本操作
认识几个基本操作,加深一下印象。
(1)改变索引名
刚刚的城市人口数据,我们有10个城市,索引是0~9,我们不想用这么单调的数字来做索引,想用每个城市的简称来表示,和Series一样,可以用index=来指定索引:
(因为Python自带的shell中,结果的显示没有ipython notebook美观,所以下面的例子我用ipython notebook的结果来展示)

注:语句为
pop_DF=DataFrame(pop, index=['Yu', 'Hu', 'Jing', 'Rong', 'Jin', 'Sui', 'Bao', 'Ha', 'Su', 'Shen'])
(2)增加一列
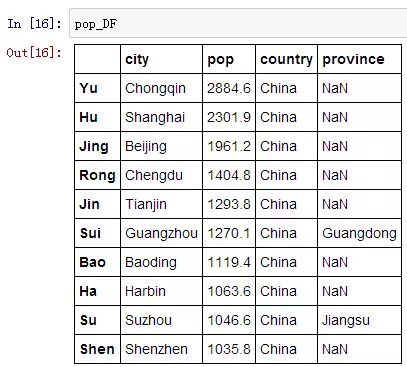
如何给DataFrame增加一列?还是以刚刚城市人口的数据pop_DF为例,我们来增加一列,给每个城市打上“China”的标记:
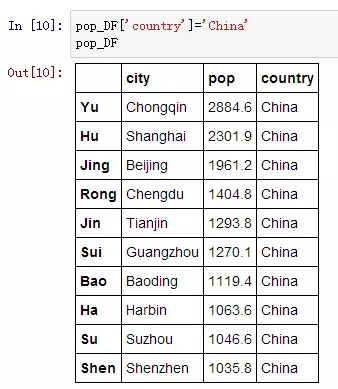
有时候增加的这一列不一定全,可能有缺失,比如再给每个城市增加一列归属省份,但是本人地理差,只知道广州属于广东,苏州属于江苏,那么我可以这么加:

这里我get了两点:
1. 可以用Series来按照索引的匹配来增加一列;
2. 缺失的地方会用NaN来表示。
(3)排序
作为统计师,排序是常见的,我想到的以后可能用到的至少有这几种:
人为给定顺序;
按照索引来自动排序:升序、降序;
按照某一变量来自动排序;
好吧,一个一个来学:
-
人为给定顺序:
用reindex函数,可以人为的给定顺序,想让谁在前面谁就在前面。
比如,我们按照首字母来人为给定如下顺序

注:语句为
pop_DF2=pop_DF.reindex(['Bao', 'Ha', 'Hu', 'Jin', 'Jing', 'Rong', 'Shen', 'Su', 'Sui', 'Yu'])
这时我有一个问题了:要是reindex中出现了不存在的索引怎么办?

比如上例中pop_DF2的“Chu”,结果全面变量都是缺失的。
-
按照索引自动排序:
可以用 .sort_index() 来让数据按照索引自动排序。
在上例中,我们多了一个索引为“Chu”的空数据,并且在Bao的前面,我们再用sort_index()让它按照字母顺序自动重排一下。
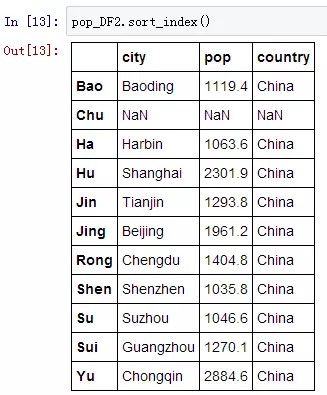
这是默认的升序排列,也可以降序,只要指定ascending=False就可以:
pop_DF2.sort_index(ascending=False)
-
按照变量自动排序:
我们可以用 .sort_values( by = '' ) 来指定某一个变量来排序:
我们回到pop_DF这个数据:
让它按照pop来排序:

(4)删除一列
前面学的是改变索引名、增加一列、各种排序,好像少掉了什么——如何删掉一列和一行...
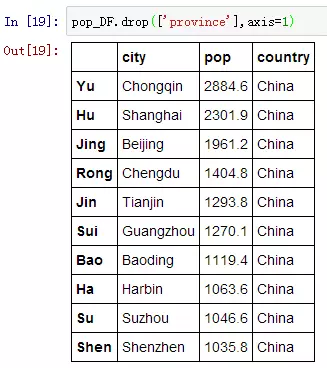
用 .drop() 就可以删掉指定的索引行,比如我们想删掉pop_DF中,人口大于2000(万)的城市,也就是重庆和上海,对于的索引(也就是简称)为:Yu和Hu

那么删掉一列呢?
也是用 .drop() ,指定一下要删的列变量,并且加一句 axis=1 。
今天的学习结束!
Series、DataFrame、玩索引、各种增、各种删、各种排序......今天学的很过瘾,学完这些,我想我真正算得上——入门Pandas啦!
目录如下:
前言
一、描述性统计
1. 加总
2. 描述性统计
3. 相关系数
二、缺失值处理
1. 丢弃缺失值
2. 填充缺失值
三、层次化索引
1. 用层次索引选取子集
2. 自定义变量名
3. 变量名与索引互换
4. 数据透视表
四、数据导入导出
1. 数据导入
2. 数据导出
统计师的Python日记【第5天:Pandas,露两手】
前言
根据我的Python学习计划:
Numpy → Pandas → 掌握一些数据清洗、规整、合并等功能 → 掌握类似与SQL的聚合等数据管理功能 → 能够用Python进行统计建模、假设检验等分析技能 → 能用Python打印出100元钱 → 能用Python帮我洗衣服、做饭 → 能用Python给我生小猴子......
上一集开始学习了Pandas的数据结构(Series和DataFrame),以及DataFrame一些基本操作:改变索引名、增加一列、删除一列、排序。
今天我将继续学习Pandas。
一、描述性统计
想拿一个简单的数据试试手,翻到了一份我国2012-2015年季度GDP的数据,如下表(单位:万亿),

想整理到DataFrame中,如何处理?
用DataFrame:
gdp=DataFrame([[11.61,13.08, 13.67, 15.05],[12.81, 14.30, 15.07, 16.62], [13.87, 15.52, 16.35, 17.87], [14.80, 16.62,17.36, 18.94]], index=['2012', '2013', '2014', '2015'], columns=['s1', 's2','s3', 's4'])
得到了一张非常清爽的DataFrame数据表。
现在我要对这张表进行简单的描述性统计:
1. 加总
.sum()是将数据纵向加总(每一列加总)
这就很奇怪了,2012、2013、2014、2015四个年份的第一季度加总,这是什么鬼?其实我更想看横向加总,就是每一年四个季度加总,得到一年的总和,原来,指定axis=1即可:
特别注意的是缺失值的情况!
如果有缺失值,比如四个数值2,3,1,NaN,那么加总的结果是2+3+1+NaN=6,也就是缺失值自动排除掉了!这点特别注意,因为这可能会导致你的数据不必苛,比如某一年少一个季度的值,那么这一年其实就是三个季度的加总,跟其他年份四个季度怎么比?
因为刚入行的时候在excel上犯过这类错误,所以在此记录一下。
解决办法是指定 skipna=False,有缺失值将不可加总:
>>>df=DataFrame([[1.4, np.nan], [7.1, -4.5], [np.nan, np.nan], [0.75, -1.3]], index=['a', 'b', 'c', 'd'], columns=['one', 'two'])
>>>df
这是一组有缺失值的数据,现在来加总:
还可以累积加总:
关于缺失值,在后面还要专门学习(二、缺失值)。
2. 描述性统计
pandas除了加总,还可以利用 .describe() 得到每列的各种描述性分析:
当然,除了用 .describe() 还可以自己用函数来得到,比如:
一些函数记录在此(参考书本《利用Python进行数据分析》):
| 方法 |
描述 |
| count() |
非NA值的数量 |
| describe() |
各列的汇总统计 |
| min()、max() |
最小、最大值 |
| argmin()、argmax() |
最小、最大值对应的索引位置 |
| idxmin()、idxmax() |
最小、最大值对应的索引值 |
| quantile() |
样本分位数 |
| sum() |
加总 |
| mean() |
均值 |
| median() |
中位数 |
| mad() |
根据平均值计算的平均绝对离差 |
| var() |
方差 |
| std() |
标准差 |
| skew() |
偏度 |
| kurt() |
峰度 |
| cumsum() |
累计和 |
| cummax()、cummin() |
累计最大值和累计最小值 |
| cumprod() |
累计积 |
| diff() |
一阶差分 |
| pct_change() |
百分数变化 |
3. 相关系数
利用 .corr() 可以计算相关系数,比如计算四个季度的相关系数:
计算年份的相关系数呢?转置一下就可以了:
然而可惜的是——没有P值!
也可以单独只计算两列的系数,比如计算S1与S3的相关系数:
二、缺失值处理
Pandas和Numpy采用NaN来表示缺失数据,
1. 丢弃缺失值
两种方法可以丢弃缺失值,比如第四天的日记中使用的的城市人口数据:
将带有缺失的行丢弃掉:
这个逻辑是:“一行中只要有一个格缺失,这行就要丢弃。”
那如果想要一行中全部缺失才丢弃,应该怎么办?传入 how=’all‘ 即可。
Chu那行被丢弃掉了。
另一种丢弃缺失值的方法是 data[data.notnull()] ,但是只能处理 数值型 数据。
2. 填充缺失值
用 .fillna() 方法对缺失值进行填充,比如将缺失值全部变为0:
还可以指定填充方法:
method=
-
'ffill' 向前填充,即将前面的内容填充进来;
-
'bffill' 向后填充,即将后面的内容填充进来。
举个例子:
后面baoding的pop被填充进来了。
三、层次化索引
我们前面的索引就是Chu、Bao、Ha、Hu......,单一层次索引,如果索引为亚洲-中国-各个省-各个市,变量为人口,这就是典型的层次化索引。
>>> worldPop = pd.Series([13.74,13.41, 13.08, 1.27, 3.21, 3.09],index=[['China','China','China','Japan','US','US'],[2015,2010,2005,2015,2015,2010]])
这个例子中索引有两层,国家和年份,来学习一些简单的操作。
1. 用层次索引选取子集:
选取多个子集呢?
2. 自定义变量名
自定义变量名的好处很多,可以更方便的对数据进行选择。使用 columns= 自定义变量名:
索引的名字也可以当变量一样命名,分别命名country和year两个索引名:
用 .swaplevel() 可以调换两个索引contry和year的位置:
3. 将索引与变量互换
使用 .reset_index([]) 可以将索引变成列变量。
使用 .set_index([]),也可以讲变量变成索引:
4. 数据透视表
大家都用过excel的数据透视表,把行标签和列标签随意的布局,pandas也可以这么实施,使用 .unstack() 即可:
四、数据的导入导出
1. 数据导入
表格型数据可以直接读取为DataFrame,比如用 read_csv 直接读取csv文件:
有文件testSet.csv:
存在D盘下面,现在读取:
发现了一个问题——第一行被当做变量名了!所以要指定 header=None:
变量名变成了0、1,还是变扭啊,我们来指定个变量吧:
用 names= 可以指定变量名。
看到var1那列,如果想用这列做索引,咋办?好办!
用 index_col= 即可指定索引。
除了read_csv,还有几种读取方式:
| 函数 |
说明 |
| read_csv |
读取带分隔符的数据,默认分隔符为逗号 |
| read_table |
读取带分隔符的数据,默认分隔符为制表符 |
| read_fwf |
读取固定宽格式数据(无分隔符) |
| read_clipboard |
读取剪贴板中的数据 |
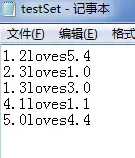
read_table可以读取txt的文件,说到这里,想到一个问题——如果txt文件的分隔符很奇怪怎么办?
比如——
这个testSet.txt文件用“loves”做分隔符!
隐隐觉得有人向我表白,但是有点恶心......
在实际中,更可能是某种乱码,解决这种特殊分隔符,用 sep= 即可。
忽略红色背景的部分。
还有一种情况是开头带有注释的:
使用 skiprows= 就可以指定要跳过的行:
从我多年统计师从业经验来看,学会了如何跳过行,也要学如何读取某些行,使用 nrows=n 可以指定要读取的前n行,以数据
为例:

2. 数据导出
导出csv文件使用 data.to_csv 命令:
data.to_csv(outFile, index=True, encoding='gb2312')
index=True 指定输出索引,当数据中有中文的时候用 encoding= 来解码,否则会出现乱码,一般 gb2312 即可,有些例外的情况用 gb18030 基本都能解决。