Python超参数自动搜索模块GridSearchCV上手
网格搜索算法与K折交叉验证
网格搜索算法和K折交叉验证法是机器学习入门的时候遇到的重要的概念。
网格搜索算法是一种通过遍历给定的参数组合来优化模型表现的方法。
以决策树为例,当我们确定了要使用决策树算法的时候,为了能够更好地拟合和预测,我们需要调整它的参数。在决策树算法中,我们通常选择的参数是决策树的最大深度。
于是我们会给出一系列的最大深度的值,比如 {'max_depth': [1,2,3,4,5]},我们会尽可能包含最优最大深度。
不过,我们如何知道哪一个最大深度的模型是最好的呢?我们需要一种可靠的评分方法,对每个最大深度的决策树模型都进行评分,这其中非常经典的一种方法就是交叉验证,下面我们就以K折交叉验证为例,详细介绍它的算法过程。
首先我们先看一下数据集是如何分割的。我们拿到的原始数据集首先会按照一定的比例划分成训练集和测试集。比如下图,以8:2分割的数据集:

训练集用来训练我们的模型,它的作用就像我们平时做的练习题;测试集用来评估我们训练好的模型表现如何,它的作用像我们做的高考题,这是要绝对保密不能提前被模型看到的。
因此,在K折交叉验证中,我们用到的数据是训练集中的所有数据。我们将训练集的所有数据平均划分成K份(通常选择K=10),取第K份作为验证集,它的作用就像我们用来估计高考分数的模拟题,余下的K-1份作为交叉验证的训练集。
对于我们最开始选择的决策树的5个最大深度 ,以 max_depth=1 为例,我们先用第2-10份数据作为训练集训练模型,用第1份数据作为验证集对这次训练的模型进行评分,得到第一个分数;然后重新构建一个 max_depth=1 的决策树,用第1和3-10份数据作为训练集训练模型,用第2份数据作为验证集对这次训练的模型进行评分,得到第二个分数……以此类推,最后构建一个 max_depth=1 的决策树用第1-9份数据作为训练集训练模型,用第10份数据作为验证集对这次训练的模型进行评分,得到第十个分数。于是对于 max_depth=1 的决策树模型,我们训练了10次,验证了10次,得到了10个验证分数,然后计算这10个验证分数的平均分数,就是 max_depth=1 的决策树模型的最终验证分数。
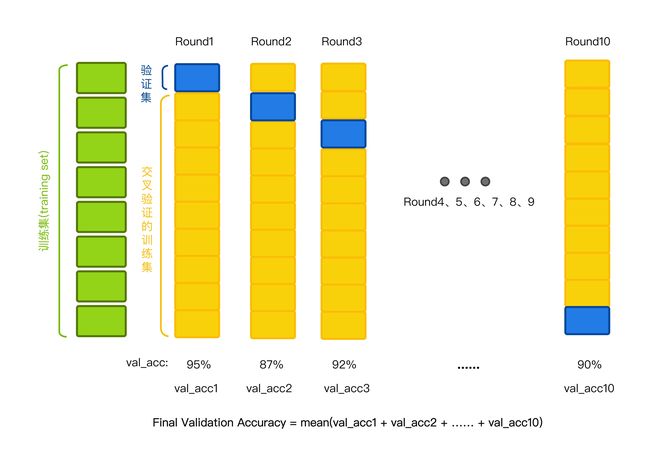
对于 max_depth = 2,3,4,5 时,分别进行和 max_depth=1 相同的交叉验证过程,得到它们的最终验证分数。然后我们就可以对这5个最大深度的决策树的最终验证分数进行比较,分数最高的那一个就是最优最大深度,我们利用最优参数在全部训练集上训练一个新的模型,整个模型就是最优模型。
下面提供一个简单的利用决策树预测乳腺癌的例子:
from sklearn.model_selection import GridSearchCV, KFold, train_test_split
from sklearn.metrics import make_scorer, accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data['data'], data['target'], train_size=0.8, random_state=0)
regressor = DecisionTreeClassifier(random_state=0)
parameters = {'max_depth': range(1, 6)}
scoring_fnc = make_scorer(accuracy_score)
kfold = KFold(n_splits=10)
grid = GridSearchCV(regressor, parameters, scoring_fnc, cv=kfold)
grid = grid.fit(X_train, y_train)
reg = grid.best_estimator_
print('best score: %f'%grid.best_score_)
print('best parameters:')
for key in parameters.keys():
print('%s: %d'%(key, reg.get_params()[key]))
print('test score: %f'%reg.score(X_test, y_test))
import pandas as pd
pd.DataFrame(grid.cv_results_).T直接用决策树得到的分数大约是92%,经过网格搜索优化以后,我们可以在测试集得到95.6%的准确率:
best score: 0.938462
best parameters:
max_depth: 4
test score: 0.956140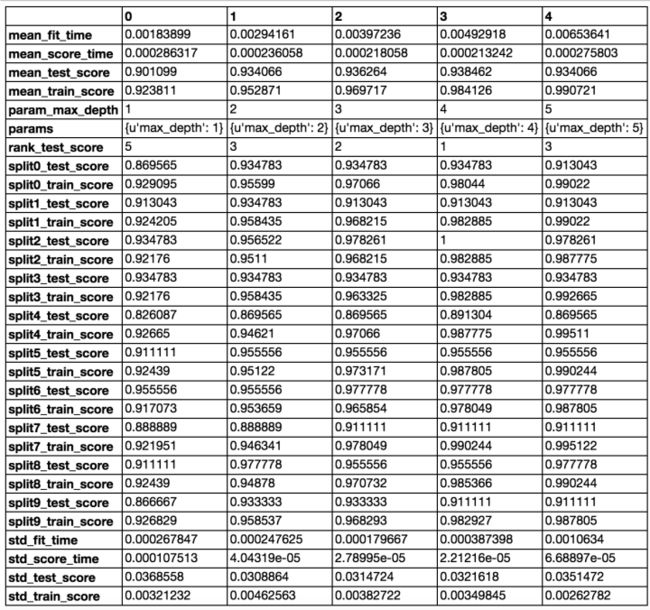
再举一个SVM的例子:
1. 引言
当我们跑机器学习程序时,尤其是调节网络参数时,通常待调节的参数有很多,参数之间的组合更是繁复。依照注意力>时间>金钱的原则,人力手动调节注意力成本太高,非常不值得。For循环或类似于for循环的方法受限于太过分明的层次,不够简洁与灵活,注意力成本高,易出错。本文介绍sklearn模块的GridSearchCV模块,能够在指定的范围内自动搜索具有不同超参数的不同模型组合,有效解放注意力。
2. GridSearchCV模块简介
这个模块是sklearn模块的子模块,导入方法非常简单
from sklearn.model_selection import GridSearchCV
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score='raise', return_train_score=True)
其中cv可以是整数或者交叉验证生成器或一个可迭代器,cv参数对应的4种输入列举如下:
- None:默认参数,函数会使用默认的3折交叉验证
- 整数k:k折交叉验证。对于分类任务,使用StratifiedKFold(类别平衡,每类的训练集占比一样多,具体可以查看官方文档)。对于其他任务,使用KFold
- 交叉验证生成器:得自己写生成器,头疼,略
- 可以生成训练集与测试集的迭代器:同上,略
3. 分析结果自动保存
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
CSV文件有个突出的优点,可以用excel等软件打开,比起记事本和matlab、python等编程语言界面,便于查看、制作报告、后期整理等。
GridSearchCV模块中,不同超参数的组合方式及其计算结果以字典的形式保存在 clf.cv_results_中,python的pandas模块提供了高效整理数据的方法,只需要3行代码即可解决问题。
cv_result = pd.DataFrame.from_dict(clf.cv_results_)
with open('cv_result.csv','w') as f:
cv_result.to_csv(f)完整例程
代码清晰易懂,无须解释。https://github.com/JiJingYu/tensorflow-exercise/tree/master/svm_grid_search
import pandas as pd
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
iris = datasets.load_iris()
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 2, 4], 'gamma':[0.125, 0.25, 0.5 ,1, 2, 4]}
svr = svm.SVC()
clf = GridSearchCV(svr, parameters, n_jobs=-1)
clf.fit(iris.data, iris.target)
cv_result = pd.DataFrame.from_dict(clf.cv_results_)
with open('cv_result.csv','w') as f:
cv_result.to_csv(f)
print('The parameters of the best model are: ')
print(clf.best_params_)
y_pred = clf.predict(iris.data)
print(classification_report(y_true=iris.target, y_pred=y_pred))5. 相关资料
- sklearn.model_selection.GridSearchCV模块主页: http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
- pandas.DataFrame模块主页:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
- 本文例程 https://github.com/JiJingYu/tensorflow-exercise/tree/master/svm_grid_search
6.未来展望
当前的工作局限于算法超参数搜索,还没有结合预处理方式自动搜索、不同算法之间自动搜索、不同深度学习模型自动搜索等。如何利用pipeline、keras、tf等模块,实现整个环节的自动搜索,是下一步学习与总结的方向。
注:
决策树转自:
https://zhuanlan.zhihu.com/p/25637642
SVM转自:
https://www.cnblogs.com/nwpuxuezha/p/6618205.html