Datawhale_数据分析组队学习task1
Numpy基础
- ndarray:一种多维数组对象
- 创建ndarray
- ndarray的数据类型
- Numpy数组的运算
- 基本的索引和切片
- 切片索引
- 布尔型索引
- 花式索引
- 数组转置和轴对换
- 通用函数:快速的元素级数组函数
- 利用数组进行数据处理
- 将条件逻辑表述为数组运算
- 数学和统计方法
- 布尔型数组的方法
- 排序
- 唯一化及其他的集合逻辑
- 用于数组的文件输入输出
- 线性代数
ndarray:一种多维数组对象
创建ndarray
创建数组使用array函数,array函数接受一切序列型的对象(包括其他数组),然后产生新的含有传入数据的Numpy数组
# 一个列表转换
import numpy as np
data1 = [6,7.5,8,0,1]
arr1 = np.array(data1)
arr1
Out[1]:
array([6. , 7.5, 8. , 0. , 1. ])
# 嵌套序列转换为多维数组
data2 = ([1,2,3,4],[5,6,7,8])
arr2 = np.array(data2)
arr2
Out[2]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
# 创建指定长度或形状的全0数组
np.zeros(10)
Out[4]:
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [5]:
np.zeros((3,6))
Out[5]:
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
# 创建指定长度或形状的全1数组
np.ones((3,6))
Out[6]:
array([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]])
# 创建没有任何具体值的数组
np.empty((2,3,2)) # np.empty不一定会返回全0数组
Out[7]:
array([[[4.94065646e-323, 6.94563584e-310],
[6.95314361e-310, 6.95326906e-310],
[6.95323149e-310, 6.25799901e-309]],
[[0.00000000e+000, 1.77229088e-310],
[3.50977866e+064, 0.00000000e+000],
[0.00000000e+000, nan]]])
# arange是python内置函数range的数组版
np.arange(15)
Out[8]:
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
# 创建一个正方的N*N单位矩阵(对角线为1,其余为0)
np.eye(3)
Out[9]:
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
ndarray的数据类型
arr1.dtype
Out[11]:
dtype('float64')
arr2.dtype
Out[12]:
dtype('int64')
# astype()将一个数组转换数据类型
int_arr1 = arr1.astype(np.int64)
int_arr1.dtype # 浮点数转换成整数,小数部分将被截取删除
Out[17]:
dtype('int64')
float_arr2 = arr2.astype(np.float64)
float_arr2.dtype #整数转换成浮点型
Out[18]:
dtype('float64')
num_strings = np.array(['1.25','-9.6','42'])
num_strings.astype(float) #字符串转换成浮点型
Out[19]:
array([ 1.25, -9.6 , 42. ])
# 直接转换成另一数组的类型
int_array = np.arange(10)
calibers = np.array([.22,.270,.357,.380,.44,.50])
int_array.astype(calibers.dtype)
Out[20]:
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
Numpy数组的运算
arr = np.array([[1.,2.,3.],[4.,5.,6.]])
arr
Out[21]:
array([[1., 2., 3.],
[4., 5., 6.]])
arr**2
Out[23]:
array([[ 1., 4., 9.],
[16., 25., 36.]])
arr-arr
Out[24]:
array([[0., 0., 0.],
[0., 0., 0.]])
1/arr
Out[25]:
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
arr*0.5
Out[26]:
array([[0.5, 1. , 1.5],
[2. , 2.5, 3. ]])
arr2 = np.array([[0.,4.,1.],[7.,2.,12.]])
arr2
Out[27]:
array([[ 0., 4., 1.],
[ 7., 2., 12.]])
arr2 > arr
Out[28]:
array([[False, True, False],
[ True, False, True]])
基本的索引和切片
arr = np.arange(10)
arr
Out[29]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[5]
Out[30]:
5
arr[5:8]
Out[31]:
array([5, 6, 7])
arr[5:8] = 12 #任何修改都会直接反映到源数组上
arr
Out[32]:
array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
高纬度数c组各索引位置上的元素是一维数组
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr2d[2]
Out[33]:
array([7, 8, 9])
arr2d[0][2]
Out[34]:
3
arr2d[0,2] # 轴0作为行,轴1作为列
Out[35]:
3
arr2d[1,1]
Out[37]:
5
切片索引
# 一维数组切片
arr = np.arange(8)
arr[1:6]
Out[39]:
array([1, 2, 3, 4, 5])
# 二维数组切片
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr2d[:2] #多维数组切片是沿着一个轴选取元素,arr2d[:2]表示选取前两行
Out[40]:
array([[1, 2, 3],
[4, 5, 6]])
# 选取前两行,一列以后
arr2d[:2,1:]
Out[41]:
array([[2, 3],
[5, 6]])
# 选取第二行的前两列
arr2d[1,:2]
Out[43]:
array([4, 5])
# 选取第三列的前两行
arr2d[:2,2]
Out[45]:
array([3, 6])
# 对切片赋值会扩散到整个选区
arr2d[:2,2] = 0
arr2d
Out[46]:
array([[1, 2, 0],
[4, 5, 0],
[7, 8, 9]])
布尔型索引
# np.random的randn函数生成正态分布的随机数据
names = np.array(['bob','joe','will','bob','will','joe','joe'])
data = np.random.randn(7,4)
names
Out[47]:
array(['bob', 'joe', 'will', 'bob', 'will', 'joe', 'joe'], dtype='花式索引
花式索引指的是利用整数数组进行索引
# 创建一个8X4数组
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
arr
Out[62]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
# 以特定顺序选取行子集
arr[[4,3,0,6]]
Out[65]:
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])
# 使用负数索引从末尾选取行
arr[[-3,-5,-7]]
Out[66]:
array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])
# 一次传入多个索引数组返回的是一个一维数组,其中元素对应各个索引元祖
arr = np.arange(32).reshape((8,4))
arr
Out[67]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
arr[[1,5,7,2],[0,3,1,2]] # 选出元素(1,0),(5,3),(7,1),(2,2)
Out[68]:
array([ 4, 23, 29, 10])
# 选取矩阵的行列子集
arr[[1,5,7,2]][:,[0,3,1,2]]
Out[70]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
数组转置和轴对换
转置返回的是源数据的试图,不进行任何复制操作
arr = np.arange(15).reshape(3,5)
arr
Out[71]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
# T转置
arr.T
Out[72]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
# 利用np.dot计算矩阵内积
arr = np.random.randn(6,3)
arr
Out[73]:
array([[ 0.82990869, 0.978127 , 0.89006737],
[-0.74031421, 1.23880287, 0.56713976],
[ 0.78642412, 0.00772851, 1.50437436],
[-0.69620762, 0.25525058, -0.25010726],
[-1.04339991, -0.59785673, -1.71862417],
[-0.8396994 , -0.64462607, 0.36059148]])
np.dot(arr.T,arr)
Out[74]:
array([[4.13375998, 0.888119 , 3.16643973],
[0.888119 , 3.32955301, 2.31600418],
[3.16643973, 2.31600418, 6.52325852]])
# transpose需要得到一个由轴编号组成的元祖才能对这些轴进行转置
arr = np.arange(16).reshape((2,2,4))
arr
Out[75]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
arr.transpose((1,0,2))
Out[76]:
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
通用函数:快速的元素级数组函数
arr = np.arange(10)
arr
Out[77]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.sqrt(arr)
Out[78]:
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
np.exp(arr)
Out[79]:
array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01,
5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03,
2.98095799e+03, 8.10308393e+03])
x = np.random.randn(8)
y = np.random.randn(8)
x
Out[80]:
array([-0.10746618, -1.2594579 , -1.14647544, 0.74994199, -1.10151013,
-1.2192859 , 0.42678941, 1.26688581])
y
Out[81]:
array([ 1.36711565, 0.26264542, 0.35566308, 0.55849781, -1.94557587,
0.01849588, 0.2542382 , -1.28094715])
np.maximum(x,y) # numpy.maximum计算x和y元素级别最大的元素
Out[83]:
array([ 1.36711565, 0.26264542, 0.35566308, 0.74994199, -1.10151013,
0.01849588, 0.42678941, 1.26688581])

利用数组进行数据处理
# np.meshgrid 函数接受两个一维数组,并产生两个二维码矩阵
points = np.arange(-5,5,0.01)
xs,ys = np.meshgrid(points,points)
ys
Out[84]:
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])
xs
Out[85]:
array([[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
...,
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99]])
z = np.sqrt(xs**2+ys**2)
z
Out[86]:
array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
...,
[7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568]])
将条件逻辑表述为数组运算
xarr = np.array([1.1,1.2,1.3,1.4,1.5])
yarr = np.array([2.1,2.2,2.3,2.4,2.5])
cond = np.array([True,False,True,True,False])
result = [(x if c else y)
for x,y,c in zip(xarr,yarr,cond)]
result
Out[87]:
[1.1, 2.2, 1.3, 1.4, 2.5]
arr = np.random.randn(4,4)
arr
Out[88]:
array([[ 0.73207141, -0.3958585 , 0.75544218, -0.55719725],
[ 0.48104231, 0.58363087, 0.33361039, 0.84412933],
[-0.58104459, 1.08238197, 0.16255388, -0.53626035],
[-2.23463577, -0.97606222, 1.57489806, 1.18146064]])
arr > 0
Out[89]:
array([[ True, False, True, False],
[ True, True, True, True],
[False, True, True, False],
[False, False, True, True]])
np.where(arr > 0,2,-2)
Out[90]:
array([[ 2, -2, 2, -2],
[ 2, 2, 2, 2],
[-2, 2, 2, -2],
[-2, -2, 2, 2]])
np.where(arr > 0,2,arr)
Out[91]:
array([[ 2. , -0.3958585 , 2. , -0.55719725],
[ 2. , 2. , 2. , 2. ],
[-0.58104459, 2. , 2. , -0.53626035],
[-2.23463577, -0.97606222, 2. , 2. ]])
数学和统计方法
arr = np.random.randn(5,4)
arr
Out[92]:
array([[ 4.32852554e-01, -1.77246260e+00, -6.87294058e-01,
-5.01447421e-01],
[ 2.87802927e-01, -1.53771554e+00, 4.31850432e-02,
-1.89447230e+00],
[ 8.43513487e-01, 8.75527573e-01, 1.16126902e+00,
1.95121291e-01],
[-4.75622793e-01, -1.05447526e+00, 4.26596841e-01,
4.35797140e-05],
[ 1.53545026e+00, 4.43769698e-01, -9.81413231e-01,
9.86633062e-02]])
arr.mean()
Out[93]:
-0.12805538135321762
np.mean(arr)
Out[94]:
-0.12805538135321762
arr.sum()
Out[95]:
-2.5611076270643522
# arr.mean(1)计算行的平均值
# arr.aum(0)计算每列的和
arr.mean(axis = 1)
Out[96]:
array([-0.63208788, -0.77529997, 0.76885784, -0.27586441, 0.27411751])
arr.sum(axis = 0)
Out[97]:
array([ 2.62399643, -3.04535613, -0.03765639, -2.10209154])
基本数组统计方法:

布尔型数组的方法
sum常用来对布尔型数组的True值计数
any用于测试数组是否存在一个或多个True
all检查数组中所有值是否都是True
arr = np.random.randn(100)
(arr > 0).sum()
Out[99]:
37
bools = np.array([False,False,True,False])
bools.any()
Out[101]:
True
bools.all()
Out[102]:
False
排序
arr = np.random.randn(6)
arr
Out[103]:
array([ 0.28876591, -0.07490967, -0.88418536, -1.30688162, -0.67393059,
0.35432183])
arr.sort()
arr
Out[105]:
array([-1.30688162, -0.88418536, -0.67393059, -0.07490967, 0.28876591,
0.35432183])
# 多维数组可以在任何一个轴向上排序
arr = np.random.randn(5,3)
arr
Out[106]:
array([[ 0.79113801, 1.06138973, 0.0159926 ],
[ 0.40293958, 0.21995582, -0.22049539],
[ 0.39487758, 1.10488635, -2.3285318 ],
[ 0.36191475, -0.24281842, -1.23205623],
[ 0.26793385, -0.09723077, -1.27148164]])
arr.sort(1)
arr
Out[108]:
array([[ 0.0159926 , 0.79113801, 1.06138973],
[-0.22049539, 0.21995582, 0.40293958],
[-2.3285318 , 0.39487758, 1.10488635],
[-1.23205623, -0.24281842, 0.36191475],
[-1.27148164, -0.09723077, 0.26793385]])
唯一化及其他的集合逻辑
mp.unique用于找出数组中的唯一值并返回已排序的结果
names = np.array(['bob','joe','will','bob','will','joe','joe'])
np.unique(names)
Out[109]:
array(['bob', 'joe', 'will'], dtype='数组的集合运算:
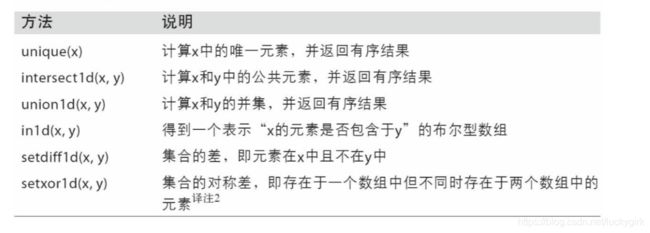
用于数组的文件输入输出
np.save和np.load是读写磁盘数组数据的两个主要函数
names = np.array(['bob','joe','will','bob','will','joe','joe'])
np.unique(names)
Out[109]:
array(['bob', 'joe', 'will'], dtype='线性代数
dot函数用于矩阵乘法
# x.dot(y)等价于np.dot(x,y)
x = np.array([[1,2,3],[4,5,6]])
y = np.array([[6,23],[-1,7],[8,9]])
print(x)
print('---------')
print(y)
print('---------')
print(x.dot(y))
print('---------')
print(np.dot(x,y))
>>>
[[1 2 3]
[4 5 6]]
---------
[[ 6 23]
[-1 7]
[ 8 9]]
---------
[[ 28 64]
[ 67 181]]
---------
[[ 28 64]
[ 67 181]]
常用的numpy.linalg函数

from numpy.linalg import inv,qr
X = np.random.randn(5,5)
mat = X.T.dot(X)
inv(mat)C
Out[120]:
array([[ 3.31569425, 2.96451728, -4.18919507, 2.38050924, -2.4653789 ],
[ 2.96451728, 3.39557309, -3.89500341, 1.83332174, -2.43322536],
[-4.18919507, -3.89500341, 6.4975655 , -4.44758048, 4.48373885],
[ 2.38050924, 1.83332174, -4.44758048, 4.08734637, -3.55776549],
[-2.4653789 , -2.43322536, 4.48373885, -3.55776549, 3.6876755 ]])