Mimicking Very Efficient Network for Object Detection
背景
Mimic作为一种模型小型化的方法,Hinton在 Distilling the Knowledge in a Neural Network一文中已经详细定义并介绍过,但近些年来大部分有关于mimic的论文主要都是局限在较为简单的classification 的任务中,而对于较为复杂一些的detection任务,直接套用以前的方案则显得不行。本文提出了一种学习feature map来实现Object Detection任务上mimic的方法。
传统的Mimic过程,一般使用一个已经训练好的大模型,固定该模型的weights不变,设计一个小模型,学习大模型的soft targets 或者logits的输出;大模型学习到有效的信息可以传递给小模型,使得小模型也可以有较为不错的性能表现,其Loss函数如下:

其中W为小模型的weights,g(x;W) 为小模型的输出,z为学习的大模型的输出。
然而直接套用该方法在检测任务中,效果很差,因此作者进行了进一步的探索。首先,对于常见的检测网络如Faster-RCNN、RFCN、SSD等进行分析,可以发现,它们主要包含两部分,分别为feature extractor以及feature decoder。而不同的大网络主要是feature extractor不同,因此作者认为对于feature map进行mimic,可以获得较为有效的结果。

Mimic方法详细叙述:
因此作者提出了本文的mimic算法,在使用本身ground-truth监督小模型训练的同时,加入大小模型之间feature map的监督,使得mimic的效果会更好。大致的流程如下图所示:
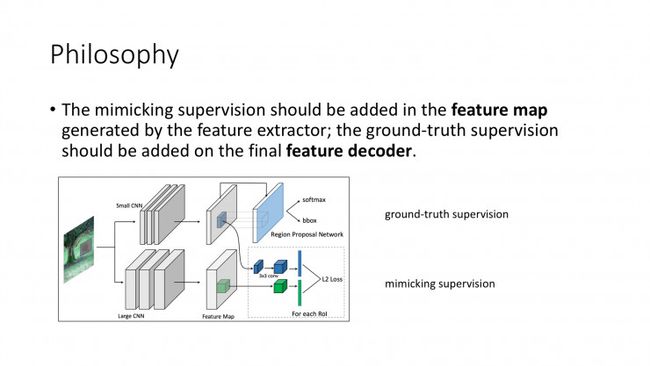
但同时作者也指出,单纯使小模型学习大模型的feature map并不能work,原因在于feature map的维度太高,包含太多全局的信息,而对于仅有少量object的feature map,通常只有微弱的响应。因此,该文中提出了一个新的卷积网络mimic方法,即将学习整个feature map变为学习proposal采样之后的feature来简化任务。
在由小网络生成的proposal中,使用spatial pyramid pooling方法在大小网络上进行局部特征采样(后经作者指正为直接使用pixel-wise的学习),然后通过L2 loss减小二者之间的差别,loss function定义如下:
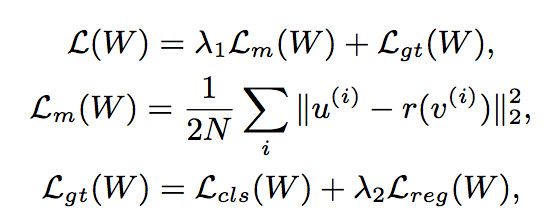
总的loss主要由两部分组成,分别为mimic loss 以及ground-truth loss,作者在实验中发现,对于mimic loss进行normalization可以取得更为稳定的mimic结果:
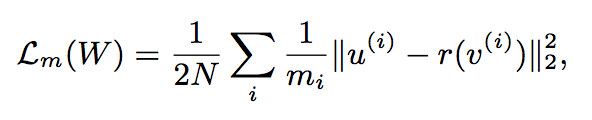
同时,作者还提到了对于小网络与大网络feature map大小不同的情况(譬如小网络中输入图像减半),可以增加一个转换层(deconvolution)使得大小网络最终mimic的层保持一致,如下图所示:

另外,在faster rcnn中stage2 fast rcnn的训练过程中,也可以添加大网络的监督信号(监督框的classification以及regression),使得小网络可以学习到更多大网络的有效信息,得到更好的结果。
结果分析:
作者在Caltech行人数据集以及PASCAL VOC 2007 数据集上进行了实验。
Caltech使用log average Miss Rate on False Positive Per Image作为评价标准,作者首先训练并得到了两个baseline检测网络:

同时,定义了mimic的小网络的结构为1/n-Inception 网络,网络的深度与层数没有改变,减小每层conv的channel个数,使得网络变得更细。
可以看到直接使用传统mimic方法训练模型,结果非常糟糕,甚至不及直接使用数据集对小网络进行训练:

而后作者使用本文方法进行Mimic训练,取得了较为可观的性能增长:

从上述结果中,可以看到使用mimic的结果取得了与原网络差不多甚至稍好的结果。

同理,在VOC数据集的测试结果中也可以看到,Mimic的方法取得了很有竞争力的结果。
现场问答
在2017 CVPR现场与论文的作者李全全进行的讨论与交流:
Q:本文为何使用 spatial pyramid pooling进行feature map的sample,是否考虑使用其他方式例如ROI-pooling?
A:经过李全全确认,他后期是直接使用ROI,也即两个feature map pixel-wise相减,而不是spatial pyramid pooling;使用SPP的效果理应是好于单size的pooling的(roi-pooling)。
Q:为何使用单层(最后一层)feature map进行mimic,是否可以融合多个feature map?
A:可以尝试融合多个feature map 进行监督,理论上来说效果应该会比较好,但由于时间较为紧张,所以没有做。文中使用的normalization是为了稳定,因为每次出来的proposal的size是不断变化的,因此在计算loss的时候的pixel的数量也会发生较大的变化,因此需要使用normalization。
Q:为何使用 deconvolution,是否可以对feature map 直接进行线性缩放?
A:直接对于feature map进行缩放是可行的。同时,这样的结构本身会在小物体的检测上比较有用。如果把deconv层独立成一个分支的话(deploy的时候去掉这个分支),效果可能比不上将这个小网络放大,目前看来,大的feature层对于小物体的检测还是比较有好处的。
Q:为何使用小网络生成的 proposal ,有没有尝试过直接使用 ground-truth boxes?
A:希望模型更多的是关注object在feature map上有响应的地方,所以使用Top-proposal。具体来说,Top-proposal的方法中,proposal的数量设定在256或者512,正负样本比例设定在1:1;而使用GroundTruth的框来做监督的效果并不好,作者有进行过类似的实验:对于负样本来说使用random的sample,正样本直接使用GroundTruth,结果比使用top-proposal的方法差一些。
Q:有没有尝试过其他不同网络结构的mimic (更小或者更瘦长的)?
A:对于mimic来说,其实小网络本身有一个baseline,大网络有一个baseline,mimic的任务便是缩小两者之间的差别;而对于小网络来说,相似的网络会有较好的学习能力,当然对于不同结构的小网络也可以使用deconv的方式来进行学习。
论文地址:http://openaccess.thecvf.com/content_cvpr_2017/papers/Li_Mimicking_Very_Efficient_CVPR