Linux 2.6 内核中的最新电源管理技术综述
前言
本系列文章将结合近年来不断在各种硬件(包括 CPU、芯片组、PCI Express 等各种最新总线标准以及外设)上新增的节能技术。
从 Linux® 2.6内核及整个 software stack (包括 kernel、middleware 以及各种用户态 utility)如何添加对这些创新的节能技术的支持这一角度,为读者介绍 Linux 操作系统近几年来在电源管理方面所取得的长足进步以及未来的发展方向。作为本系列文章的开篇之作,首先要向大家介绍的是 cpufreq,它是 Linux 2.6内核为了更好的支持近年来在各款主流CPU 处理器中出现的变频技术而新增的一个内核子系统。
Cpufreq 的由来
随着 energy efficient computing 和 performance per watt 等概念的推广以及高级配置与电源接口ACPI(Advanced Configuration and Power Interface)标准的发展,目前市场上的主流 CPU 都提供了对变频(frequency scaling)技术的支持。例如Intel®处理器所支持的 Enhanced SpeedStep® 技术和 AMD® 处理器所支持的 PowerNow! ® 技术,另外像最新的PowerPC®、ARM®、SPARC® 和 SuperH® 等处理器中也提供了类似的支持。参考资料中列出了当前 Linux 2.6内核所支持的具备变频技术的处理器。需要注意的是,这里要讨论的变频技术与大家以前所熟知的超频是两个不同的概念。超频是指通过提高核心电压等手段 让处理器工作在非标准频率下的行为,这往往会造成 CPU 使用寿命缩短以及系统稳定性下降等严重后果。
而变频技术是指CPU硬件本身支持在不同的频率下运行,系统在运行过程中可以根据随时可能发生变化的系统负载情况动态在这些不同的运行频率之间进行切换,从而达到对性能和功耗做到二者兼顾的目的。
虽然多个处理器生产厂家都提供了对变频技术的支持,但是其硬件实现和使用方法必然存在着细微甚至巨大的差别。这就使得每个处理器生产厂家都需要按照其特殊 的硬件实现和使用方法向内核中添加代码,从而让自己产品中的变频技术在 Linux 中得到支持和使用。然而,这种内核开发模式所导致的后果是各个厂家的实现代码散落在 Linux 内核代码树的各个角落里,各种不同的实现之间没有任何代码是共享的,这给内核的维护以及将来添加对新的产品的支持都带来了巨大的开销,并直接导致了 cpufreq 内核子系统的诞生。实际上,正如前文所说,发明变频技术的目的是为了能够让系统在运行过程中随时根据系统负载的变化动态调整 CPU 的运行频率。这件事情可以分为两个部分,一部分是“做什么”的问题,另一部分是“怎么做”的问题。“做什么”是指如何根据系统负载的动态变化挑选出 CPU 合适的运行频率,而“怎么做”就是要按照选定的运行频率在选定的时间对 CPU 进行设置,使之真正工作在这一频率上。这也就是我们在软件设计中经常会遇到的机制 mechanism 与策略 policy 的问题,而设计良好的软件会在架构上保证二者是被清晰的隔离开的并通过规范定义的接口进行通信。
Cpufreq 的设计和使用
为了解决前文所提到的问题,一个新的内核子系统—— cpufreq 应运而生了。Cpufreq 为在Linux 内核中更好的支持不同 CPU 的变频技术提供了一个统一的设计框架,其软件结构如图 1 所示。
图 1. Cpufreq 的软件结构
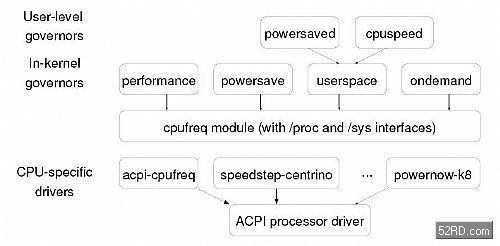
如图 1 所示,cpufreq 在设计上主要分为以下三个模块:
Cpufreq 模块(cpufreq module)对如何在底层控制各种不同CPU 所支持的变频技术以及如何在上层根据系统负载动态选择合适的运行频率进行了封装和抽象,并在二者之间定义了清晰的接口,从而在设计上完成了前文所提到的对 mechanism 与policy 的分离。
在 cpufreq 模块的底层,各个CPU 生产厂商只需根据其变频技术的硬件实现和使用方法提供与其 CPU 相关的变频驱动程序(CPU-specific drivers),例如 Intel 需要提供支持Enhanced SpeedStep 技术的 CPU 驱动程序,而 AMD 则需要提供支持 PowerNow! 技术的 CPU 驱动程序。
在 cpufreq 模块的上层,governor 作为选择合适的目标运行频率的决策者,根据一定的标准在适当的时刻选择出 CPU 适合的运行频率,并通过 cpufreq 模块定义的接口操作底层与 CPU 相关的变频驱动程序,将 CPU 设置运行在选定的运行频率上。
目前最新的 Linux 内核中提供了 performance 、powersave 、userspace、conservative 和 ondemand 五种 governors 供用户选择使用,它们在选择 CPU 合适的运行频率时使用的是各自不同的标准并分别适用于不同的应用场景。用户在同一时间只能选择其中一个 governor 使用,但是可以在系统运行过程中根据应用需求的变化而切换使用另一个 governor 。
这种设计带来的好处是使得 governor 和 CPU 相关的变频驱动程序的开发可以相互独立进行,并在最大限度上实现代码重用,内核开发人员在编写和试验新的 governor 时不会再陷入到某款特定 CPU 的变频技术的硬件实现细节中去,而 CPU 生产厂商在向 Linux 内核中添加支持其特定的 CPU 变频技术的代码时只需提供一个相对来说简单了很多的驱动程序,而不必考虑在各种不同的应用场景中如何选择合适的运行频率这些复杂的问题。
内核中的 cpufreq 子系统通过 sysfs 文件系统向上层应用提供了用户接口,对于系统中的每一个 CPU 而言,其 cpufreq 的 sysfs 用户接口位于 /sys/devices/system/cpu/cpuX/cpufreq/ 目录下,其中 X 代表 processor id ,与 /proc/cpuinfo 中的信息相对应。以cpu0 为例,用户一般会在该目录下观察到以下文件:

$ ls
-
F
/
sys
/
devices
/
system
/
cpu
/
cpu0
/
cpufreq
/
affected_cpus
cpuinfo_cur_freq
cpuinfo_max_freq
cpuinfo_min_freq
ondemand
/
scaling_available_frequencies
scaling_available_governors
scaling_cur_freq
scaling_driver
scaling_governor
scaling_max_freq
scaling_min_freq
stats
/
这其中的所有可读文件都可以使用 cat 命令进行读操作,另外所有可写文件都可以使用 echo 命令进行写操作。其中cpuinfo_max_freq 和 cpuinfo_min_freq 分别给出了CPU 硬件所支持的最高运行频率及最低运行频率, cpuinfo_cur_freq 则会从 CPU 硬件寄存器中读取 CPU 当前所处的运行频率。虽然 CPU 硬件支持多种不同的运行频率,但是在有些场合下用户可以只选择使用其中的一个子集,这种控制是通过scaling_max_freq 和 scaling_min_freq 进行的。Governor在选择合适的运行频率时只会在 scaling_max_freq 和scaling_min_freq 所确定的频率范围内进行选择,这也就是scaling_available_frequencies 所显示的内容。与cpuinfo_cur_freq 不同, scaling_cur_freq 返回的是cpufreq 模块缓存的 CPU 当前运行频率,而不会对 CPU 硬件寄存器进行检查。 scaling_available_governors 会告诉用户当前有哪些 governors 可供用户使用,而 scaling_driver 则会显示该 CPU 所使用的变频驱动程序。 Stats 目录下给出了对 CPU 各种运行频率的使用统计情况,例如 CPU 在各种频率下的运行时间以及在各种频率之间的变频次数。 Ondemand 目录则与 ondemand governor 相关,在后文会进行相应的介绍。
通过以上的介绍,大家对如何使用 cpufreq 通过 sysfs 提供的用户接口已经有了大致的了解,但是对于绝大部分用户而言,逐一操作这些文件既费力又耗时。因此 Dominik 等人开发了cpufrequtils 工具包[2],为用户提供了更加简便的对内核cpufreq 子系统的操作接口。通过 cpufreq-info 的输出,读者可以很清楚的看到刚刚在上面介绍过的/sys/devices/system/cpu/cpuX/cpufreq/ 目录下各个文件的内容。
$ cpufreq
-
info
cpufrequtils
002
: cpufreq
-
info (C) Dominik Brodowski
2004
-
2006
Report errors and bugs to [email protected], please.
analyzing CPU
0
:
driver: acpi
-
cpufreq
CPUs which need to
switch
frequency at the same time:
0
1
hardware limits:
1000
MHz
-
1.67
GHz
available frequency steps:
1.67
GHz,
1.33
GHz,
1000
MHz
available cpufreq governors: userspace, conservative,
ondemand, powersave, performance
current policy: frequency should be within
1000
MHz
and
1.67
GHz.
The governor
"
ondemand
"
may decide which
speed to use
within
this
range.
current CPU frequency
is
1000
MHz.
analyzing CPU
1
:
driver: acpi
-
cpufreq
CPUs which need to
switch
frequency at the same time:
0
1
hardware limits:
1000
MHz
-
1.67
GHz
available frequency steps:
1.67
GHz,
1.33
GHz,
1000
MHz
available cpufreq governors: userspace, conservative,
ondemand, powersave, performance
current policy: frequency should be within
1000
MHz
and
1.67
GHz.
The governor
"
ondemand
"
may decide which
speed to use
within
this
range.
current CPU frequency
is
1000
MHz.
Ondemand governor 的由来及其实现刚刚我们在 cpufreq-info 的输出中可以看到 cpufreq 子系统一共提供了五种 governors 供用户选择使用,它们分别是 userspace,conservative,ondemand,powersave 和performance。在最新的内核中如果用户不进行额外设置的话,ondemand 会被作为默认的 governor 使用。为了理解是什么原因造成了这种现状,我们在这里带领读者回顾一下 cpufreq 子系统中的governor在内核中的开发历史。
Cpufreq 作为一个子系统最早被加入到 Linux 内核中时只配备了三个governors ,分别是performance、powersave 和userspace。当用户选择使用 performance governor 时,CPU会固定工作在其支持的最高运行频率上;当用户选择使用powersave governor 时,CPU会固定工作在其支持的最低运行频率上。因此这两种 governors 都属于静态 governor ,即在使用它们时 CPU 的运行频率不会根据系统运行时负载的变化动态作出调整。这两种 governors 对应的是两种极端的应用场景,使用 performance governor 体现的是对系统高性能的最大追求,而使用 powersave governor 则是对系统低功耗的最大追求。虽然这两种应用需求确实存在,但大多数用户在大部分时间里需要的是更加灵活的变频策略。最早的 cpufreq 子系统通过 userspace governor 为用户提供了这种灵活性。正如它的名字一样,使用 userspace governor 时,系统将变频策略的决策权交给了用户态应用程序,并提供了相应的接口供用户态应用程序调节 CPU 运行频率使用。通过使用 cpufrequtils 工具包中的 cpufreq-set 将 userspace 设置为 cpufreq 子系统所使用的 governor 后,我们可以看到与之前相比在 /sys/devices/system/cpu/cpuX/cpufreq/ 目录下多出了一个名为 scaling_setspeed 的文件,这正是 userspace governor 所提供的特殊用户接口。用户可以通过向该文件写入任何一个 scaling_available_frequencies 中所支持的运行频率,从而将 CPU 设置在该频率下运行。
# cpufreq - set - g userspace
# cat cpuinfo_cur_freq
1000000
# cat scaling_available_frequencies
1667000 1333000 1000000
# echo 1333000 > scaling_setspeed
# cat cpuinfo_cur_freq
1333000
刚刚提到在使用 userspace governor 时,系统将变频策略的决策权交给了用户态应用程序。该用户态应用程序一般是一个 daemon 程序,每隔一定的时间间隔收集一次系统信息并根据系统的负载情况使用 userspace governor 提供的 scaling_setspeed 接口动态调整 CPU 的运行频率。作为这个daemon 程序,当时在几个主要的 Linux 发行版中使用的一般是 powersaved 或者 cpuspeed。这两个 daemon 程序一般每隔几秒钟统计一次 CPU 在这个采样周期内的负载情况,并根据统计结果调整 CPU 的运行频率。这种 userspace governor 加用户态 daemon 程序的变频方法虽然为用户提供了一定的灵活性,但通过开源社区的广泛使用所得到的意见反馈逐渐暴露了这种方法的两个严重缺陷。第一个是性能方面的问题。例 如powersaved 每隔五秒钟进行一次系统负载情况的采样分析的话,我们可以分析一下在下面给出的应用场景中的用户体验。假设 powersaved 的采样分析刚刚结束,而且由于在刚刚结束的采样周期内系统负载很低,CPU 被设置在最低频率上运行。这时用户如果打开 Firefox® 等对 CPU 运算能力要求相当高的程序的话,powersaved 要在下一个采样点——大约五秒钟之后才有机会观察到这种提高 CPU 运行频率的需求。也就是说,在Firefox 启动之初的五秒钟内 CPU 的计算能力并没有被充分发挥出来,这无疑会使用户体验大打折扣。第二个是系统负载情况的采样分析的准确性问题。将监控系统负载情况并对未来 CPU 的性能需求做出判断的任务交给一个用户态程序完成实际上并不合理,一方面是由于一个用户态程序很难完整的收集到所有需要的信息,因为这些信息大部分都保存 在内核空间;另一方面一个用户态程序如果想要收集这些系统信息,必然需要进行用户态与内核态之间的数据交互,而频繁的用户态与内核态之间的数据交互又会给 系统性能带来负面影响。
那么这两个问题有没有解决的方法呢?应该讲社区中的开发人员就第二个问题比较容易达成一致,既然在用户态对系统的负载情况进行采集和分析存在这样那样的问 题,那么更加合理的做法就是应该将这部分工作交由内核负责。但是第一个问题呢?第一个问题最直观的解决方案就是降低对系统负载进行采样分析的时间间隔,这 样 powersaved 就能尽早的对系统负载的变化做出及时的响应。然而这种简单的降低采样分析的时间间隔的方案同样存在着两方面的问题,一方面这意味着更加频繁的用户态与内核 态之间的数据交互,因此必然也就意味着对系统性能带来更大的负面影响;另一方面的主要原因在于当时各个 CPU 生产厂家的变频技术在硬件上仍不完善,具体体现就是在对 CPU 进行变频设置时所需的操作时间过长,例如 Intel 早期的 Speedstep 技术在对 CPU 进行变频设置时需要耗时 250 微秒,在此过程中 CPU 无法正常执行指令。读者如果简单的计算一下不难发现,即使对于一个主频为 1GHz 的 CPU 而言, 250 微秒也意味着 250,000 个时钟周期,在这期间 CPU 完全可以执行完上万条指令。因此从这个角度而言,简单的降低采样分析的时间间隔对系统性能带来的负面影响更加严重。幸运的是随着硬件技术的不断完善和改 进,对 CPU 进行变频设置所需的操作时间已经显著降低,例如 Intel 最新的 Enhanced Speedstep 技术在对 CPU 进行变频设置时耗时已降至 10 微秒,下降了不止一个数量级。正是这种 CPU 硬件技术的发展为内核开发人员解决这些早期的遗留问题提供了契机,Venkatesh 等人提出并设计实现了一个新的名为 ondemand 的 governor ,它正是人们长期以来希望看到的一个完全在内核态下工作并且能够以更加细粒度的时间间隔对系统负载情况进行采样分析的 governor。在介绍 ondemand governor 的具体实现之前,我们先来看一下如何使用 ondemand governor 及其向用户提供了哪些操作接口。通过 cpufreq-set 将 ondemand 设置为当前所使用的 governor 之后,在 /sys/devices/system/cpu/cpuX/cpufreq 目录下会出现一个名为 ondemand 的子目录
$ sudo cpufreq
-
set
-
g ondemand
$ ls
/
sys
/
devices
/
system
/
cpu
/
cpu0
/
cpufreq
/
ondemand
/
ignore_nice_load
powersave_bias
sampling_rate
sampling_rate_max
sampling_rate_min
up_threshold
$ sudo cat sampling_rate_min sampling_rate
sampling_rate_max
40000
80000
40000000
$ sudo cat up_threshold
30
在这个子目录下名字以 sampling 打头的三个文件分别给出了ondemand governor 允许使用的最短采样间隔,当前使用的采样间隔以及允许使用的最长采样间隔,三者均以微秒为单位。
以笔者的电脑为例, ondemand governor 每隔 80 毫秒进行一次采样。另外比较重要的一个文件是 up_threshold ,它表明了系统负载超过什么百分比时ondemand governor 会自动提高CPU 的运行频率。以笔者的电脑为例,这个数值为 30% 。那么这个表明系统负载的百分比数值是如何得到的呢?在支持Intel 最新的 Enhanced Speedstep 技术的 CPU 中,在处理器硬件中直接提供了两个 MSR 寄存器(Model Specific Register)供 ondemand governor 采样分析系统负载情况使用。这两个 MSR 寄存器的 名字分别为 IA32_MPERF 和 IA32_APERF[5] ,其中 IA32_MPERF MSR 中的 MPERF 代表Maximum Performance , IA32_APERF MSR 中的 APERF 代表Actual Performance 。就像这两个 MSR 的名字一样, IA32_MPERF MSR 寄存器是一个当 CPU 处在 ACPI C0 状态下时按照 CPU 硬件支持的最高运行频率每隔一个时钟周期加一的计数器;IA32_APERF MSR 寄存器是一个当 CPU 处在 ACPI C0 状态下时按照 CPU 硬件当前的实际运行频率每隔一个时钟周期加一的计数器。有了这两个寄存器的存在,再考虑上 CPU 处于ACPI C0 和处于 ACPI C1、C2、C3 三种状态下的时间比例,也就是 CPU 处于工作状态和休眠状态的时间比例, ondemand governor 就可以准确的计算出 CPU 的负载情况了。
得到了 CPU 的负载情况,接下来的问题就是如何选择 CPU 合适的运行频率了。刚刚在前面提到,当系统负载超过up_threshold 所设定的百分比时, ondemand governor 将会自动提高 CPU 的运行频率,但是具体提高到哪个频率上运行呢?在 ondemand governor 监测到系统负载超过 up_threshold所设定的百分比时,说明用户当前需要 CPU 提供更强大的处理能力,因此 ondemand governor 会将CPU设置在最高频率上运行,这一点社区中的开发人员和广大用户都没有任何异议。但是当 ondemand governor 监测到系统负载下降,可以降低 CPU 的运行频率时,到底应该降低到哪个频率呢? ondemand governor 的最初实现是在可选的频率范围内调低至下一个可用频率,例如笔者使用的 CPU 支持三个可选频率,分别为 1.67GHz、 1.33GHz 和 1GHz ,如果 CPU 运行在 1.67GHz 时ondemand governor 发现可以降低运行频率,那么 1.33GHz 将被选作降频的目标频率。这种降频策略的主导思想是尽量减小对系统性能的负面影响,从而不会使得系统性能在短时间内迅速降低以影响用户体验。但是在 ondemand governor 的这种最初实现版本在社区发布后,大量用户的使用结果表明这种担心实际上是多余的, ondemand governor 在降频时对于目标频率的选择完全可以更加激进。因此最新的 ondemand governor 在降频时会在所有可选频率中一次性选择出可以保证 CPU 工作在 80% 以上负荷的频率,当然如果没有任何一个可选频率满足要求的话则会选择 CPU 支持的最低运行频率。大量用户的测试结果表明这种新的算法可以在不影响系统性能的前提下做到更高效的节能。在算法改进后, ondemand governor 的名字并没有改变,而 ondemand governor 最初的实现也保存了下来,并且由于其算法的保守性而得名conservative 。
支持 Intel Enhanced Speedstep 技术的 CPU 驱动程序的实现前文在讨论cpufreq 的软件结构时已经指出, cpufreq 从设计上将 CPU 变频的 policy 与mechanism 分离开来并由上层的governor 负责决定 CPU 合适的工作频率。但是在governor根据系统负载的变化决定调整 CPU 的运行频率时,最终还是需要底层与 CPU 相关的特定驱动程序完成设置 CPU 运行频率的任务。这里向读者介绍一下支持 Intel 最新的Enhanced Speedstep 技术的 CPU 驱动程序的实现原理,关注的重点是如何对 CPU 进行变频设置。实际上支持 Intel Enhanced Speedstep 技术的处理器为用户提供了非常简单的编程接口,对 CPU 运行频率进行设置是通过一个名为 IA32_PERF_CTL 的MSR 寄存器进行的,另外还有一个名为 IA32_PERF_STATUS 的MSR 寄存器可供检查 CPU 当前所处的运行频率。当用户需要对CPU 运行频率进行设置时只需按照 Intel 开发手册的说明向IA32_PERF_CTL MSR 寄存器中写入规定的数值即可。
总结及未来的发展方向
本文为读者介绍了变频技术在 CPU 硬件上的出现以及 Linux 内核中最初的实现存在的各种问题,并由此导致了 cpufreq 这一新的内核子系统的诞生。虽然早期的cpufreq模块所提供的三种 governors 能够在一定程度下满足用户的需要并且提供了一定的灵活性,但是由于受到当时 CPU 硬件技术水平的限制,仍然有很多不尽如人意的地方。之后随着 CPU 变频硬件技术的不断发展,尤其是 Intel Enhanced Speedstep 技术的出现,原有的技术障碍被打破,随之而来的是 cpufreq 内核子系统有了一个全新的更加完善而高效的 ondemand governor 。
由此不难看出,内核中的 cpufreq 子系统是由于 CPU 硬件变频技术的出现而出现,同时也在随着 CPU 硬件变频技术的发展而发展。这其实也预示着内核中 cpufreq 子系统未来的发展方向,即继续跟随 CPU 硬件变频技术的发展脚步与时俱进。在本文的最后简单为读者介绍一下在 Intel 最新的 CPU 中针对硬件变频支持的一项新技术。前文提到在支持 Intel 最新的Enhanced Speedstep 技术的 CPU 中提供了名字分别为IA32_MPERF 和 IA32_APERF 的两个 MSR 寄存器,以便为cpufreq 模块所使用的 governor 动态收集系统的负载情况提供直接的硬件支持。其中 IA32_APERF MSR 寄存器当 CPU 处在ACPI C0 状态下时按照 CPU 硬件当前的实际运行频率每隔一个时钟周期加一。 Intel 最新的处理器中进一步考虑了CPU 在运行过程中由于访问内存或 IO 等原因可能会出现流水线停摆的状况时, IA32_APERF 以前这种简单的按照 CPU 当前实际运行频率每隔一个时钟周期加一的做法并不能完全准确的反映CPU 的负载情况。在 Intel 最新的处理器中如果出现流水线停摆的情况, IA32_APERF 将暂时停止累加,而是在对用户真正“有用”的时间周期才会递增,这样 CPU 硬件就可以为cpufreq 模块所使用的 governor 提供比以前更加准确的系统负载统计信息。