python3爬虫
基本库的使用urllib
urllib包含了四个模块:
(1)request,http请求模块
(2)error,异常处理模块
(3)parse,url处理的工具模块
(4)robotparser,识别网站的robots.txt文件
1.request
from urllib import request, parse, error
import socket
'''
request.urlopen(url,data,timeout,cafile,capath,cadefault,context) url是必须的参数
'''
data = bytes(parse.urlencode({'user': '1300330101'},), encoding='utf-8')
try:
res = request.urlopen('http://148.70.139.25/login_sure/', data=data, timeout=1)
'''
res:read() readinto() getheaders() getheader(name) fileno()
msg version status reason close
'''
# print(res.read().decode('utf-8'))
print(type(res))
print(res.getheaders())
print(res.getheader('Server'))
except error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
'''
复杂的构造请求
req=request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
response=request.urlopen(req)
'''
2.requests
学了这个基本不用request了
import requests
from requests.auth import HTTPBasicAuth
'''
打开的方式
r=requests.get()
requests.post()
requests.head()
requests.put()
requests.delete()
requests.options()
r.text r.cookies r.status_code r.json r.content
r.headers r.encoding r.reason r.close() r.history
'''
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/48.0.2564.116 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4',
'Cookie':''
}
r = requests.get('https://www.baidu.com', headers=header, verify=False)# 不进行ssl认证
r.encoding = 'utf-8'
'''
基本用法见https://blog.csdn.net/qq_33564134/article/details/88818172
'''
# 文件的上传
files = {'file': open('names', 'rb')}
r = requests.post('http://httpbin/post', files=files)
# 代理设置
proxies = {
'http': 'http://10.10.10.1:2123',
'https': 'htttps://1.1.1.1:2090',
}
r = requests.post('url', proxies=proxies, timeout=1)
# 身份认证
r = requests.post('url',auth=HTTPBasicAuth('username', 'password'))
import requests
import re
import json
import time
def get_one_page(url):
m_header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/48.0.2564.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4'
}
res = requests.get(url, headers=m_header)
res.encoding = 'utf-8'
if res.status_code == 200:
return res.text
return None
def parse_one_page(html):
pattern = re.compile(r'.*?board-index.*?>(\d+).*?' # index排名
r'.*?(.*?).*?'
# name名字
r'(.*?)
.*?' # star主演
r'(.*?)
.*?' # releasetime时间
r'.*?', re.S)
items = re.findall(pattern, html)
print(items)
for item in items:
# yield的使用,长见识,长见识-----取出阻塞值yield{}可以给下个函数使用,少去了list的传递
yield {
'index': item[0].strip(),
'name': item[1].strip(),
'star': item[2].strip(),
'releasetime': item[3].strip(),
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'https://maoyan.com/board/4?offset='+str(offset)
print(url)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(0, 10):
main(i*10)
time.sleep(2)

解析库的使用
Beautiful Soup
如果说寻找特定的内容
from bs4 import BeautifulSoup
import lxml
import re
# soup的种类 tag标签 name标签的名字 Attributes标签的属性 内容
# tag = soup.b tag.name tag['class']|tag.attrs tag.string
# 遍历:
# contents 将子节点全部列出
# len(soup.contents)有多少个子节点
# find_all(tag,)
#
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 创建soup
soup = BeautifulSoup(html, 'lxml')
# print(soup.prettify()) # 自动修补格式,填充完成
# print(soup.body.contents) # body包含的全部内容
# print(soup.head.contents[0].string) # 找到标签title 读取内容
# print(soup.find_all('a')) # a的全部标签
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
AJAX数据的爬取
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。
<script>
function loadXMLDoc()
{
var xmlhttp;
if (window.XMLHttpRequest)
{
// IE7+, Firefox, Chrome, Opera, Safari 浏览器执行代码
xmlhttp=new XMLHttpRequest();
}
else
{
// IE6, IE5 浏览器执行代码
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","/try/ajax/demo_get.php",true);
xmlhttp.send();
}
</script>

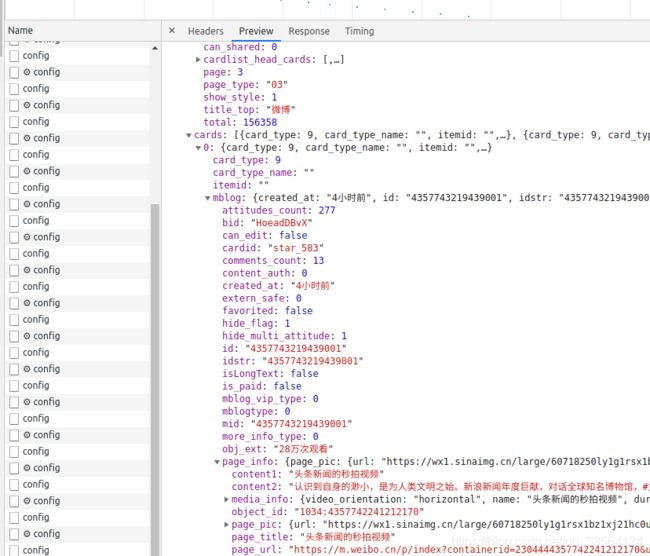
import requests
from urllib.parse import urlencode
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/p/2304131618051664_-_WEIBO_SECOND_PROFILE_WEIBO',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
max_page = 10
def get_page(page):
params = {
'page_type': '03',
'containerid': '2304131618051664_-_WEIBO_SECOND_PROFILE_WEIBO',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json(), page
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json, page: int):
print(json)
if json:
items = json.get('data').get('cards')
for index, item in enumerate(items):
if page == 1 and index == 1:
continue
else:
item = item.get('mblog', {})
weibo = {}
weibo['id'] = item.get('id')
weibo['title'] = item.get('page_info', {}).get('content1')
weibo['content'] = item.get('page_info', {}).get('content2')
yield weibo
if __name__ == '__main__':
for page in range(1, max_page + 1):
json = get_page(page)
results = parse_page(*json)
for result in results:
print(result)

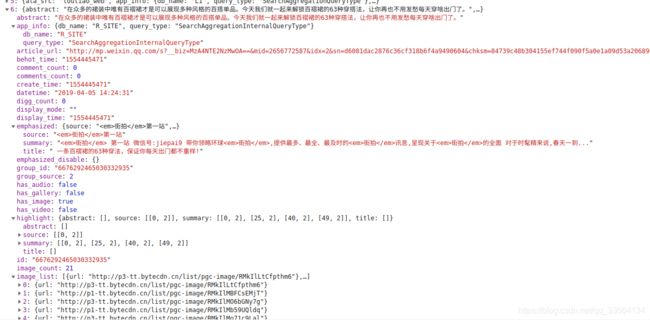
import requests
from urllib.parse import urlencode
from requests import codes
import os
from hashlib import md5
from multiprocessing.pool import Pool
import re
def get_page(offset):
params = {
'aid': '24',
'offset': offset,
'format': 'json',
#'keyword': '街拍',
'autoload': 'true',
'count': '20',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis'
}
base_url = 'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D'
url = base_url + urlencode(params)
try:
resp = requests.get(url)
print(url)
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None
def get_images(json):
if json.get('data'):
data = json.get('data')
for item in data:
if item.get('cell_type') is not None:
continue
title = item.get('title')
images = item.get('image_list')
for image in images:
origin_image = re.sub("list", "origin", image.get('url'))
yield {
'image': origin_image,
# 'iamge': image.get('url'),
'title': title
}
print('succ')
def save_image(item):
img_path = 'img' + os.path.sep + item.get('title')
print('succ2')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
resp = requests.get(item.get('image')) # 根据图片的url得到图片
if codes.ok == resp.status_code:
file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format(
file_name=md5(resp.content).hexdigest(),
file_suffix='jpg')
if not os.path.exists(file_path):
print('succ3')
with open(file_path, 'wb') as f:
f.write(resp.content)
print('Downloaded image path is %s' % file_path)
print('succ4')
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image,item %s' % item)
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 0
GROUP_END = 7
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups) # 线程池开启
pool.close()
pool.join()
result:

动态渲染页面的爬取
splash的使用
安装:
sudo apt install docker
sudo vim /etc/docker/daemon.json
{
“registry-mirrors”: [
“http://hub-mirror.c.163.com”,
“https://registry.docker-cn.com/”
]
}
sudo docker pull scrapinghub/splash # 安装
docker run -p 8050:8050 scrapinghub/splash # 运行
Lua脚本的使用
print("Hello World!")
-- test.lua 文件脚本
a = 5 -- 全局变量
local b = 5 -- 局部变量
function joke()
c = 5 -- 全局变量
local d = 6 -- 局部变量
end
joke()
print(c,d) --> 5 nil
do
local a = 6 -- 局部变量
b = 6 -- 对局部变量重新赋值
print(a,b); --> 6 6
end
print(a,b) --> 5 6
===========================================
a, b, c = 0, 1
print(a,b,c) --> 0 1 nil
a, b = a+1, b+1, b+2 -- value of b+2 is ignored
print(a,b) --> 1 2
a, b, c = 0
print(a,b,c) --> 0 nil nil
==============================================
a=10
while( a < 20 )
do
print("a 的值为:", a)
a = a+1
end
days = {"Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"}
for i,v in ipairs(days) do print(v) end //i imdex v value
function f(x)
print("function")
return x*2
end
for i=1,f(5) do print(i)
end//input 1-10
==============================================
--[ 定义变量 --]
a = 10;
--[ 使用 if 语句 --]
if( a < 20 )
then
--[ if 条件为 true 时打印以下信息 --]
print("a 小于 20" );
end
print("a 的值为:", a);
==============================================
and or not
#返回长度
... 字符串的连接
其余和c一样
splash的使用
function main(splash, args)
return {hello='hello world '}
end

异步处理
function main(splash, args)
local url_list={"www.baidu.com","www.taobao.com"}
local urls=args.urls or url_list
local results={}
for index,url in ipairs(urls) do
local ok,reason=splash:go("http://"..url)
if ok then
splash:wait(0.5)
results[url]=splash:png()
end
end
return results
end

===================splash的对象的属性===================
args:
local url=splash.args.url
js_enabled s是否执行js的开关,默认true
splash.js_enabled=false // 是否加载js
splash.resource_timeout=0.1 // 超时设置
splash.images_enabled=false //是否加载图片
splash.plugins_enabled=false //是否加载插件
splash.scroll_position={y=400,x=200} //移动位置
===================对象的方法============================
splash:go(url,baseurl=nil,headers=nil,http_mrthod="POST",body=nil,formdata=nil)
// baseurl 时请求附加的路径
// headers 请求头
// http_mothod 请求的方法
// body 请求时的表单的数据
// formdata Conten-type或者application/x-www-form-urlencoded
// 返回的是状态和原因的组合
wait(time,cancel_on_redirect=false,cancel_on_error=true)
// 表示发生错误就不发生重定向,立即停止加载
// 直接调用js的方法
jsfunc([[
function()
{
var body=document.body;
var divs=body.getElemnetByTagName('div');
return divs.length;
}
]])
// 执行js语句
local title=splash:evaljs("documnet.title")
同样runjs()也相同,但是吧返回bool
function main(splash, args)
splash:autoload([[
function get_title()
{
return document.title;
}
]])
splash:go("https://www.baidu.com")
return {title=splash:evaljs("get_title()")}
end
定时器call_later(function,time)
function main(splash, args)
local shots={}
local timer=splash:call_later(function()
shots['a']= splash:png()
splash:wait(1)
shots['b']=splash:png()
end,0.2)
splash:go('http://www.taobao.com')
splash:wait(2)
return shots;
end
http_get(url,headers=nil,follow_redirects=true)模拟发送get请求
http_post(url,headers=nil,follow_redirects=true,body)模拟发送post请求
set_content('...')
html()返回html
png()
jpeg()
har()页面加载过程的描述
url()
get_cookies()
add_cookie()
clear_cookies()
get_viewport_size()返回浏览器的大小
set_viewport_size()
set_viewport_full()
set_user_agent()
set_custom_headers({["Accept"]="",["Host"]="www.baidu.com"})
select()) css选择器 input=splash.select('#kw')
input:send_text()
input:mouse_click()
select_all()
seleniumd的使用
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
'''
pip3 install selenium
http://npm.taobao.org/mirrors/chromedriver/ to this url download chrome driver and set environment
'''
# 等待条件
'''
# 定位一个元素检查的它的状态是否和期待的一样。locator是定位器,是(by,path)的元组,is_selected是布尔值
element_located_selection_state_to_be(locator, is_selected)
element_to_be_clickable(locator) 是否可以点击
frame_to_be_available_and_switch_to_it(locator) 判断是否可以switch进去
new_window_is_opened(current_handles) 新窗口是否打开
presence_of_all_elements_located(locator) 全部元素是否加载出来
EC.presence_of_element_located((By.id,'q')) id是q的节点是否加载出来
EC.title_is(xxx) 标题是否是xxx
EC.title_contains(xxx) 标题是否包含xxx
EC.visibility_of(locator) 元素是否可见
EC.text_to_be_present_in_element(locator,str) 是否包含字符串
EC.text_to_be_present_in_element_value(locator, int) 是否包含字数值
'''
browser = webdriver.Chrome()
try:
browser.get("http://www.baidu.com") # use chrome open url(baidu.com)
input = browser.find_element_by_id('kw') # 获取输入框,
input.send_keys('清华大学') # input id`s value
wait = WebDriverWait(browser,10) # 等待10
print(browser.current_url) # current url
print(browser.get_cookies()) # get cookie
print(browser.page_source) # html source
browser.execute_script('window.open()')
browser.switch_to_window(browser.window_handles[1])
browser.get('http://www.zhihu.com')
browser.switch_to_window(browser.window_handles[0])
except EC:
print('have error take!!!')
finally:
pass
# browser.close()
# 申明浏览器
'''
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.safari()
'''
# 访问页面获得源码
'''
browser.get(url)
html=browser.page_source
'''
# 查找节点
'''
browser.find_element_by_id()
browser.find_element_by_class_name()
browser.find_element_by_css_selector()
browser.find_element_by_tag_name()
browser.find_element_by_xpath()
browser.find_element(by,value)
多个节点elements
'''
# 节点交互
'''
input = browser.find_element_by_id('kw')
input.send_keys('value')
input.clear()
button = browser.find_element_by_id('su')
button.click()
'''
# 执行script
'''
browser.execute_cdp_cmd()
browser.execute_script()
'''
# 获取节点信息
'''
input.get_attribute('class') 属性
input.text value
input.id id
input.size size
input.tag_name tag name
input.location location
'''
# 切换Frame
'''
browser.switch_to_frame('frame name')
'''
# 延时等待
'''
browser.implicitly_wait(10) 等待10s
wait = WebDriverWait(browser, 10) 最大等待10s,遇到untill完成的时候可减少等待
input = wait.until(EC.presence_of_element_located(By.ID, 'kw')) 等待的条件,如果10s加载不出来就抛出异常
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
'''
# 前进和后退
'''
browser.get()*10
browser.back()
browser.forward()
'''
# cookies
'''
browser.get_cookies()
browser.get_cookie()
browser.add_cookie({'name': 'zz', 'domain': 'www.baidu.com', 'value': '123'})
browser.delete_cookie()
browser.delete_all_cookies()
'''
# 打开和切换窗口
'''
browser.execute_script('window.open()') 打开新窗口
browser.switch_to_window(browser.window_handles[1]) 进入新窗口
browser.get('http://www.zhihu.com') 在新窗口打开网页
browser.switch_to_window(browser.window_handles[0]) 回到旧窗口
'''
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from pyquery import PyQuery as pq
from urllib.parse import quote
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 1000)
KEYWORD = 'ipad'
MAX_PAGE = 3
def index_page(page):
"""
抓取索引页
:param page: 页码
"""
print('正在爬取第', page, '页')
url = 'https://s.taobao.com/search?q=' + quote(KEYWORD)
browser.get(url)
WebDriverWait(browser, 20)
print(browser.get_cookies())
try:
url = 'https://s.taobao.com/search?q=' + quote(KEYWORD)
browser.get(url)
if page > 1:
# 等待节点的加载-----等待条件
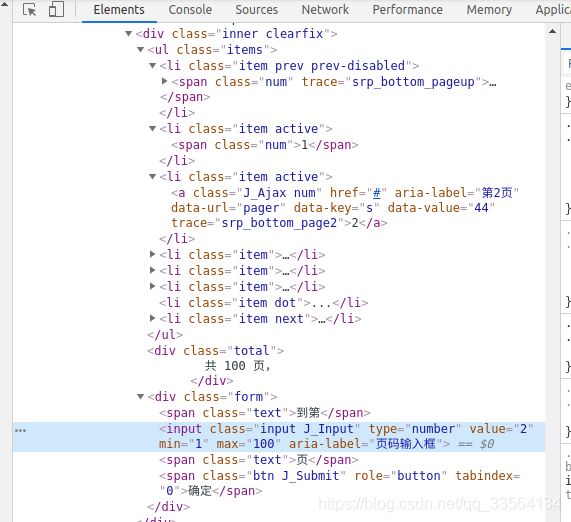
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')))
# 节点是否可以点击----等待条件
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page) # 页面的设定
submit.click()
# 是否包含某个文字----等待条件
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.m-itemlist .items .item')))
get_products()
except TimeoutException:
index_page(page)
def get_products():
"""
提取商品数据
"""
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
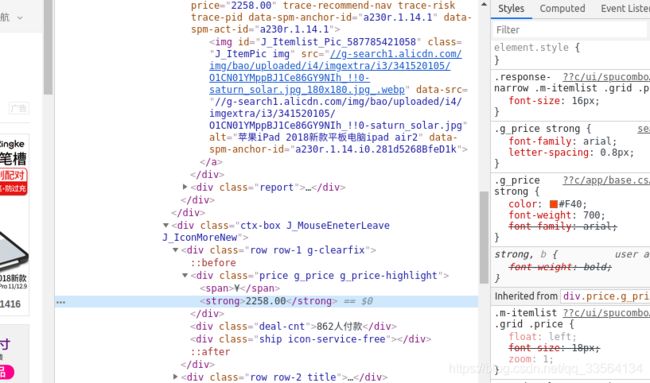
product = {
'image': item.find('.pic .img').attr('data-src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text(),
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
def main():
"""
遍历每一页
"""
for i in range(1, MAX_PAGE + 1):
index_page(i)
browser.close()
if __name__ == '__main__':
main()


验证码识别
图形验证码
import tesserocr
from PIL import Image
# discern code ,way one
'''
image = Image.open('code.jpeg')
result = tesserocr.image_to_text(image)
print(result)
'''
# discern code ,way two
'''
print(tesserocr.file_to_text('code.jpeg'))
'''
# 有些图片加上了一些干扰的东西,所以可以进行图片处理
image = Image.open('code.jpeg')
image = image.convert('L') # 灰度处理
# -----------二值化处理 way one-------------
# image = image.convert('1') # 二值化处理,默认阀值127
# -----------二值化处理 way two-------------
table = []
for i in range(256):
if i < 150: # 二值化的阀值180
table.append(0)
else:
table.append(1)
image = image.point(table, '1') # 二值化处理
image.show()
print(tesserocr.image_to_text(image))
极验滑动验证码
具体的步骤:类初始化参数,有手机号码和,用open()进入网站,然后点击注册按钮,进入注册页面,移动鼠标mouse_to_code(),获得image1,然后进行get_position()得到位置,进行图片的剪切,get_geetest_image()
之后点击验证码,弹出另外一张图,得到为imag2,进行图片的比对,之后拖动
1.网站的查看,寻找特定的点





import time
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
BORDER = 6
INIT_LEFT = 60
'''
# 定位一个元素检查的它的状态是否和期待的一样。locator是定位器,是(by,path)的元组,is_selected是布尔值
element_located_selection_state_to_be(locator, is_selected)
element_to_be_clickable(locator) 是否可以点击
frame_to_be_available_and_switch_to_it(locator) 判断是否可以switch进去
new_window_is_opened(current_handles) 新窗口是否打开
presence_of_all_elements_located(locator) 全部元素是否加载出来
EC.presence_of_element_located((By.id,'q')) id是q的节点是否加载出来
EC.title_is(xxx) 标题是否是xxx
EC.title_contains(xxx) 标题是否包含xxx
EC.visibility_of(locator) 元素是否可见
EC.text_to_be_present_in_element(locator,str) 是否包含字符串
EC.text_to_be_present_in_element_value(locator, int) 是否包含字数值
'''
class CrackGeetest():
def __init__(self):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
self.url = 'https://www.huxiu.com/'
self.browser = webdriver.Chrome(chrome_options=chrome_options)
self.browser.maximize_window()
self.wait = WebDriverWait(self.browser, 6)
self.mobile = '13377309257'
self.code_from_mobile = '123456'
def __del__(self):
pass
# self.browser.close()
def get_register_button(self):
"""
点击网站首页的注册按钮
:return: None
"""
button = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'js-register')))
print("首页注册按钮找到")
button.click()
return None
def mouse_to_code(self):
"""
将鼠标移动到指定的位置
:return: none
"""
area = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'gt_slider')))
ActionChains(self.browser).move_to_element(area).perform()
print("musoe to code")
return None
def get_screenshot(self):
"""
获取网页截图
:return: 截图对象
"""
print("start shot image")
screenshot = self.browser.get_screenshot_as_png()
print("end shot image")
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_position(self):
"""
获取验证码位置(有缺口的那张图片的位置大小)
:return: 验证码位置元组
"""
print("开始找 img position")
time.sleep(1)
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'gt_box')))
print("img 位置找到")
location = img.location
size = img.size
print(size)
# 按理说这样是可以的,可能因为网站设置问题
'''
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size[
'width']
'''
#可以观察得到,
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x']-300, location['x'] -300 + size[
'width']
return (top, bottom, left, right)
def get_slider(self):
"""
获取滑块
:return: 滑块对象
"""
slider = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'gt_slider_knob')))
print('slider was found')
return slider
def get_geetest_image(self, name='captcha.png'):
"""
获取验证码图片
:return: 图片对象
"""
top, bottom, left, right = self.get_position()
print('验证码位置', top, bottom, left, right)
print('window size (%s)' % self.browser.get_window_rect())
screenshot = self.get_screenshot()
print("picture was found")
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
captcha.show()
return captcha
def open(self):
"""
打开网页输入用户名密码
:return: None
"""
self.browser.get(self.url)
self.get_register_button()
mobile = self.wait.until(EC.presence_of_element_located((By.ID, 'sms_username')))
code_from_mobile = self.wait.until(EC.presence_of_element_located((By.ID, 'sms_captcha')))
# 玄学,不得不相信,该等待还是的等待
time.sleep(1)
mobile.send_keys(self.mobile)
code_from_mobile.send_keys(self.code_from_mobile)
def get_gap(self, image1, image2):
"""
获取缺口偏移量
:param image1: 不带缺口图片
:param image2: 带缺口图片
:return:
"""
left = 60
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
return left
def is_pixel_equal(self, image1, image2, x, y):
"""
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取两个图片的像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 60
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False
def get_track(self, distance):
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正2
a = 2
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
def move_to_gap(self, slider, track):
"""
拖动滑块到缺口处
:param slider: 滑块
:param track: 轨迹
:return:
"""
ActionChains(self.browser).click_and_hold(slider).perform()
for x in track:
ActionChains(self.browser).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(self.browser).release().perform()
def login(self):
"""
登录
:return: None
"""
submit = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'login-btn')))
submit.click()
time.sleep(10)
print('登录成功')
def crack(self):
# 输入用户名密码
self.open()
# self.get_screenshot()
# 将鼠标移动到指定的位置
self.mouse_to_code()
# # 获取验证码图片
image1 = self.get_geetest_image('captcha1.png')
# image1 = Image.open('captcha1.png')
# # 点按呼出缺口
slider = self.get_slider()
slider.click()
# # 获取带缺口的验证码图片
time.sleep(2)
image2 = self.get_geetest_image('captcha2.png')
# image2 = Image.open('captcha2.png')
# # 获取缺口位置
gap = self.get_gap(image1, image2)
print('缺口位置', gap)
# # 减去缺口位移
gap -= 4
# # 获取移动轨迹
track = self.get_track(gap)
print('滑动轨迹', track)
# # 拖动滑块
self.move_to_gap(slider, track)
#
time.sleep(0.5)
success = self.wait.until(
EC.presence_of_element_located((By.CLASS_NAME, 'gt_ajax_tip')))
print(success)
#
# # 失败后重试
if str(success.get_attribute('class')).find('gt_success'):
print(success.get_attribute('class'))
print("success")
else:
self.crack()
if __name__ == '__main__':
crack = CrackGeetest()
crack.crack()

代理池
#GetHtml.py
import requests
from requests.exceptions import ConnectionError
base_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
}
def get_page(url, options={}):
"""
抓取代理
:param url:
:param options:
:return:
"""
headers = dict(base_headers, **options)
print('正在抓取', url)
try:
response = requests.get(url, headers=headers)
print('抓取成功', url, response.status_code)
if response.status_code == 200:
return response.text
except ConnectionError:
print('抓取失败', url)
return None
#crawler.py
import json
import re
from pyquery import PyQuery as pq
from .GetHtml import get_page
class ProxyMetaclass(type):
def __new__(cls, name, bases, attrs):
count = 0
attrs['__CrawlFunc__'] = []
for k, v in attrs.items():
if 'crawl_' in k:
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs)
class Crawler(object, metaclass=ProxyMetaclass):
def get_proxies(self, callback):
proxies = []
for proxy in eval("self.{}()".format(callback)):
# print('成功获取到代理', proxy)
proxies.append(proxy)
return proxies
def crawl_daili66(self, page_count=4):
"""
获取代理66
:param page_count: 页码
:return: 代理
"""
start_url = 'http://www.66ip.cn/{}.html'
urls = [start_url.format(page) for page in range(1, page_count + 1)]
for url in urls:
print('Crawling', url)
html = get_page(url)
if html:
doc = pq(html)
trs = doc('.containerbox table tr:gt(0)').items()
for tr in trs:
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
yield ':'.join([ip, port])
def crawl_ip3366(self):
for page in range(1, 4):
start_url = 'http://www.ip3366.net/free/?stype=1&page={}'.format(page)
html = get_page(start_url)
ip_address = re.compile('\s*(.*?) \s*(.*?) ')
# \s * 匹配空格,起到换行作用
re_ip_address = ip_address.findall(html)
for address, port in re_ip_address:
result = address+':'+ port
yield result.replace(' ', '')
def crawl_kuaidaili(self):
for i in range(1, 4):
start_url = 'http://www.kuaidaili.com/free/inha/{}/'.format(i)
html = get_page(start_url)
if html:
ip_address = re.compile('(.*?) ')
re_ip_address = ip_address.findall(html)
port = re.compile('(.*?) ')
re_port = port.findall(html)
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','')
def crawl_xicidaili(self):
for i in range(1, 3):
start_url = 'http://www.xicidaili.com/nn/{}'.format(i)
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Cookie':'_free_proxy_session=BAh7B0kiD3Nlc3Npb25faWQGOgZFVEkiJWRjYzc5MmM1MTBiMDMzYTUzNTZjNzA4NjBhNWRjZjliBjsAVEkiEF9jc3JmX3Rva2VuBjsARkkiMUp6S2tXT3g5a0FCT01ndzlmWWZqRVJNek1WanRuUDBCbTJUN21GMTBKd3M9BjsARg%3D%3D--2a69429cb2115c6a0cc9a86e0ebe2800c0d471b3',
'Host':'www.xicidaili.com',
'Referer':'http://www.xicidaili.com/nn/3',
'Upgrade-Insecure-Requests':'1',
}
html = get_page(start_url, options=headers)
if html:
find_trs = re.compile('(.*?) ', re.S)
trs = find_trs.findall(html)
for tr in trs:
find_ip = re.compile('(\d+\.\d+\.\d+\.\d+) ')
re_ip_address = find_ip.findall(tr)
find_port = re.compile('(\d+) ')
re_port = find_port.findall(tr)
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','')
def crawl_ip3366(self):
for i in range(1, 4):
start_url = 'http://www.ip3366.net/?stype=1&page={}'.format(i)
html = get_page(start_url)
if html:
find_tr = re.compile('(.*?) ', re.S)
trs = find_tr.findall(html)
for s in range(1, len(trs)):
find_ip = re.compile('(\d+\.\d+\.\d+\.\d+) ')
re_ip_address = find_ip.findall(trs[s])
find_port = re.compile('(\d+) ')
re_port = find_port.findall(trs[s])
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','')
def crawl_iphai(self):
start_url = 'http://www.iphai.com/'
html = get_page(start_url)
if html:
find_tr = re.compile('(.*?) ', re.S)
trs = find_tr.findall(html)
for s in range(1, len(trs)):
find_ip = re.compile('\s+(\d+\.\d+\.\d+\.\d+)\s+ ', re.S)
re_ip_address = find_ip.findall(trs[s])
find_port = re.compile('\s+(\d+)\s+ ', re.S)
re_port = find_port.findall(trs[s])
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','')
def crawl_data5u(self):
start_url = 'http://www.data5u.com/free/gngn/index.shtml'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'JSESSIONID=47AA0C887112A2D83EE040405F837A86',
'Host': 'www.data5u.com',
'Referer': 'http://www.data5u.com/free/index.shtml',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
}
html = get_page(start_url, options=headers)
if html:
ip_address = re.compile('(\d+\.\d+\.\d+\.\d+) .*?(\d+) ', re.S)
re_ip_address = ip_address.findall(html)
for address, port in re_ip_address:
result = address + ':' + port
yield result.replace(' ', '')
from proxypool.crawler import Crawler
import requests
import multiprocessing as mp
import time
pro_list=[]
class Getter():
def __init__(self):
self.crawler = Crawler()
def is_over_threshold(self):
"""
判断是否达到了代理池限制
"""
return True
def run(self):
print('获取器开始执行')
proxies_list = []
if self.is_over_threshold():
for callback_label in range(self.crawler.__CrawlFuncCount__):
callback = self.crawler.__CrawlFunc__[callback_label]
# 获取代理
proxies = self.crawler.get_proxies(callback)
pro_list.append( proxies)
# tester(proxies)
# proxies_list.append(proxies)
# print(proxies)
# yield proxies_list
def my_run(proxy):
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
try:
res = requests.get('http://www.baidu.com', timeout=1, proxies=proxies, verify=False)
if res.status_code == 200:
print('Successfully', proxy)
except:
pass
# print('faild')
def tester(proxies_list):
pool = mp.Pool(processes=30) # 进程池数
pool.map(my_run, proxies_list)
pool.close()
pool.join()
# for pro in proxies_list:
# pool.apply_async(my_run, (pro,))
getter = Getter()
getter.run()
list=[]
for pro in pro_list:
for i in pro:
list.append(i)
tester(list)
/usr/bin/python3.5 /home/zz/Downloads/ProxyPool-master/proxypool/getter.py
获取器开始执行
正在抓取 http://www.ip3366.net/?stype=1&page=1
抓取成功 http://www.ip3366.net/?stype=1&page=1 200
正在抓取 http://www.ip3366.net/?stype=1&page=2
抓取成功 http://www.ip3366.net/?stype=1&page=2 200
正在抓取 http://www.ip3366.net/?stype=1&page=3
抓取成功 http://www.ip3366.net/?stype=1&page=3 200
Crawling http://www.66ip.cn/1.html
正在抓取 http://www.66ip.cn/1.html
抓取成功 http://www.66ip.cn/1.html 200
Crawling http://www.66ip.cn/2.html
正在抓取 http://www.66ip.cn/2.html
抓取成功 http://www.66ip.cn/2.html 200
Crawling http://www.66ip.cn/3.html
正在抓取 http://www.66ip.cn/3.html
抓取成功 http://www.66ip.cn/3.html 200
Crawling http://www.66ip.cn/4.html
正在抓取 http://www.66ip.cn/4.html
抓取成功 http://www.66ip.cn/4.html 200
正在抓取 http://www.xicidaili.com/nn/1
抓取成功 http://www.xicidaili.com/nn/1 200
正在抓取 http://www.xicidaili.com/nn/2
抓取成功 http://www.xicidaili.com/nn/2 200
正在抓取 http://www.iphai.com/
抓取成功 http://www.iphai.com/ 200
正在抓取 http://www.data5u.com/free/gngn/index.shtml
抓取成功 http://www.data5u.com/free/gngn/index.shtml 200
正在抓取 http://www.kuaidaili.com/free/inha/1/
抓取成功 http://www.kuaidaili.com/free/inha/1/ 200
正在抓取 http://www.kuaidaili.com/free/inha/2/
抓取成功 http://www.kuaidaili.com/free/inha/2/ 503
正在抓取 http://www.kuaidaili.com/free/inha/3/
抓取成功 http://www.kuaidaili.com/free/inha/3/ 200
Successfully 61.128.208.94:3128
Successfully 110.52.235.121:9999
Successfully 111.165.16.115:8118
Successfully 116.209.56.122:9999
Successfully 104.248.14.241:3128
Successfully 171.83.166.97:9999
Successfully 5.58.156.61:53654
Successfully 182.47.86.249:8118
Successfully 134.209.41.247:3128
Successfully 112.85.128.187:9999
Successfully 112.85.130.241:9999
Successfully 103.47.94.67:23500
Successfully 111.177.177.166:9999
Successfully 59.45.13.220:57868
Process finished with exit code 0
pyspider爬虫框架
ubuntu环境发生错误先运行
sudo apt-get install libssl-dev libcurl4-openssl-dev python-dev
apt-get install libxml2-dev libxslt1-dev python-dev
然后 pip3 install pyspider
scrapyd框架
官网教程
创建项目:scrapy startproject tutorial
运行项目:scrapy crawl quotes -o quotes.json,输出为json
元素的查看shell方式:
scrapy shell 'http://quotes.toscrape.com'
>>>response.css('title')
[<Selector xpath='descendant-or-self::title' data='Quotes to Scrape '>]
>>>response.css('.article-item-box h4 a::text').extract()
tutorial/
scrapy.cfg # 项目部署的配置文件
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # 配置文件
spiders/ # a directory where you'll later put your spiders
__init__.py
数据的提取Seletor(同样是一个网页解析库)
1.xpath选择器
response.xpath(’//a/text()’).extract()
response.xpath(’//a’).xpath(’@href’).extract()
response.xpath(’//a’).re(‘href="(.*?/details/.*?)"’)这个就厉害了
2.css选择器
response.css(’.article-item-box a::attr(href)’).extract()
response.css(’.article-item-box a::text’).extract()
response.css(’.article-item-box h4 a::attr(herf)’).getall()
[‘https://blog.csdn.net/qq_33564134/article/details/88958274’, ‘https://blog.csdn.net/qq_33564134/article/details/88926508’, ‘https://blog.csdn.net/qq_33564134/article/details/88846003’, ‘https://blog.csdn.net/qq_33564134/article/details/88818172’, ‘https://blog.csdn.net/qq_33564134/article/details/88767403’, ‘https://blog.csdn.net/qq_33564134/article/details/88747726’, ‘https://blog.csdn.net/qq_33564134/article/details/88722124’, ‘https://blog.csdn.net/qq_33564134/article/details/88689497’, ‘https://blog.csdn.net/qq_33564134/article/details/88549606’, ‘https://blog.csdn.net/qq_33564134/article/details/88354366’, ‘https://blog.csdn.net/qq_33564134/article/details/88365798’, ‘https://blog.csdn.net/qq_33564134/article/details/88090489’, ‘https://blog.csdn.net/qq_33564134/article/details/87563453’, ‘https://blog.csdn.net/qq_33564134/article/details/85255067’, ‘https://blog.csdn.net/qq_33564134/article/details/85042179’, ‘https://blog.csdn.net/qq_33564134/article/details/85019301’, ‘https://blog.csdn.net/qq_33564134/article/details/85017937’]
spider的用法
基础属性
name:爬虫的名称
allowed_domains:允许爬取的域名
start_urls:起始的url列表
custom_settings会覆盖全局的配置
settings:
start_requests()默认使用start_urls来构造response
parse()被当做response默认的回调函数
closed() spider关闭时默认的回调函数
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
'''
this can repleace def start_requests
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
'''
def parse(self, response):
# 保存成为文件
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
# 信息的提取
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
useragent的设置
在midlewares.py里面添加类
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agents = [
'Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2',
'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1'
]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agents)
def process_response(self, request, response, spider):
response.status = 201
return response
然后在setting.py文件,取消注释
SPIDER_MIDDLEWARES = {
'tutorial.middlewares.TutorialSpiderMiddleware': 543,
}
pipeline的使用
pipeline可以启用数据库等
核心的方法
必须实现的一个方法:def process_item(self, item, spider)
def process_item(self, item, spider):
"""
如果错误会抛出异常DropItem
:param item:
:param spider:
:return: item
"""
print(item['title'])
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (item.table, keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
def open_spider(self, spider):
"""
spider开启的时候启用该函数,该函数就是一些初始化,比如连接数据库
:param spider:
:return:
"""
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8',
port=self.port)
self.cursor = self.db.cursor()
def close_spider(self, spider):
"""
spider关闭时会启用
:param spider:
:return:
"""
self.db.close()
@classmethod
def from_crawler(cls, crawler):
"""
可以配置全局的对象
:param crawler:
:return:
"""
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
=一个完整的例子
scrapy startproject image360 新建项目
scrapy genspider images images.so.com 在spider下创建images名称的爬虫可以得到如下的源码
# -*- coding: utf-8 -*-
import scrapy
class ImagesSpider(scrapy.Spider):
name = 'images'
allowed_domains = ['images.so.com']
start_urls = ['http://images.so.com/']
def parse(self, response):
pass
==================1.重写items.py=======================
import scrapy
from scrapy import Item, Field
class Image360Item(scrapy.Item):
collection = table = 'images'
id = Field()
url = Field()
title = Field()
thumb = Field()
==================2.重写images.py=======================
# -*- coding: utf-8 -*-
from scrapy import Spider, Request
from urllib.parse import urlencode
import json
from image360.items import Image360Item
class ImagesSpider(Spider):
name = 'images'
allowed_domains = ['images.so.com']
start_urls = ['http://images.so.com/']
def start_requests(self):
data = {'ch': 'photography', 'listtype': 'new'}
base_url = 'https://image.so.com/zj?'
for page in range(1, self.settings.get('MAX_PAGE') + 1):
data['sn'] = page * 30
params = urlencode(data)
url = base_url + params
yield Request(url, self.parse)
def parse(self, response):
result = json.loads(response.text)
for image in result.get('list'):
item = Image360Item()
item['id'] = image.get('imageid')
item['url'] = image.get('qhimg_url')
item['title'] = image.get('group_title')
item['thumb'] = image.get('qhimg_thumb_url')
yield item
==================3.重写settings.py=======================
# -*- coding: utf-8 -*-
# Scrapy settings for image360 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'image360'
MAX_PAGE = 10
SPIDER_MODULES = ['image360.spiders']
NEWSPIDER_MODULE = 'image360.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'image360 (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'image360.middlewares.Image360SpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'image360.middlewares.Image360DownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'image360.pipelines.Image360Pipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'my'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123'
MYSQL_PORT = 3306
ITEM_PIPELINES = {
'image360.pipelines.ImagePipeline': 300,
'image360.pipelines.MysqlPipeline': 301,
}
IMAGES_STORE = './images'
==================4.重写pipelines.py=======================
# -*- coding: utf-8 -*-
import pymysql
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawler(cls, crawler):
"""
可以配置全局的对象
:param crawler:
:return:
"""
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
"""
spider开启的时候启用该函数,该函数就是一些初始化,比如连接数据库
:param spider:
:return:
"""
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8',
port=self.port)
self.cursor = self.db.cursor()
def close_spider(self, spider):
"""
spider关闭时会启用
:param spider:
:return:
"""
self.db.close()
def process_item(self, item, spider):
"""
如果错误会抛出异常DropItem
:param item:
:param spider:
:return: item
"""
print(item['title'])
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (item.table, keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['url'])
环境要求mysql+ubuntu
sudo apt insatll mysql-server
pip3 install pymysql

scrpy 对接splash
通用爬虫
未完的大业,没有需求就没有生产
你可能感兴趣的:(python)