FCOS: Fully Convolutional One-Stage Object Detection论文解读和代码实践
FCOS是一个全卷积结构的anchor free 目标检测网络。虽然是anchor free,但是mAP精度却比RetinaNet高,而且又是全卷积结构,比起anchor base 的检测网络,少了很多超参数,推理速度也较anchor based的一些方法快上许多。
另外值得一提,作者开源的FCOS项目真的是良心,经常更新维护。
FCOS官方代码
摘要
作者提出了一种全卷积,一阶段目标检测网络,通过对每一个像素预测一个目标来解决目标检测问题(没有anchor,特征图上一个位置预测一个目标。anchor的办法是一个位置预测k个目标)。比起RetinaNet, SSD, YOLOV3, Faster RCNN等网络,FCOS不需要anchor,自然也不需要候选框。 通过消除anchor,FCOS避免了和ahor相关的复杂计算,比如在训练过程中要计算anchor和GT的IOU值。更重要的是,毕淼了和anchor相关的超参数,比如anchor的数目,比例和尺寸。FCOS具有更简单的网络结构,实现更高的精度。在单尺度单模型下,COCO上得到44.7%的AP。
方法
formulation
作者先论述如何不用anchor做检测。
F i ∈ R H × W × C F_i \in R^{H \times W \times C} Fi∈RH×W×C视作backbone输出的特征图,框GT记作 B i {B_i} Bi, B i = ( x 0 i , y 0 i , x 1 i , y 1 i , c i ) B_i = (x_0^i,y_0^i,x_1^i, y_1^i, c^i) Bi=(x0i,y0i,x1i,y1i,ci)。 x 0 , y 0 x_0, y_0 x0,y0是左上角坐标值, x 1 , y 1 x_1, y_1 x1,y1是右下角坐标值, c i c_i ci是第i个目标的类别。
对于在 F i F_i Fi上的某个位置(x,y),这个位置映射到原图的位置是 ( s / / 2 + x s , s / / 2 + y s ) ( s//2 + xs, s//2 + ys) (s//2+xs,s//2+ys),这个位置可以视作是在(x,y)在原图对应感受野的中心。
不同于anchor based的方法,使用anchor作为参考,对目标框进行回归。FCOS直接对GT的位置进行回归。具体来说,如果(x,y)这个位置落在GT内,则认为这个位置是正样本,否则就是负样本,(anchor based的办法需要在训练时计算IOU,双阈值,才能判断正负anchor)。对于位置的真值,仍然是四维向量,但计算方式发生了变化。 p ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) p^*=(l^*, t^*, r^*,b^*) p∗=(l∗,t∗,r∗,b∗)用于训练回归分支。四个值分别是这个点在框的四个边的距离。如下图所示:

如果一个点落到两个框的交集中了,这个点对应的框回归真值又该是多少呢?作者称一个位置如果落到多个框中,这个样本称作ambiguous sample。对于这样的样本,挑面积最小的框作为这个点的回归对象。如下图:

圆点在两个框中,但蓝色框面积较小,所以这个点的回归对象是由蓝色框作为GT计算出来的。回归GT计算方式也很简单。
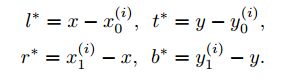
outputs
网络的输出形式也和anchor based 的不同。score分支输出80维向量(其实是81维,数据集是coco),回归分支仍然是四维。注意因为没有anchor,所以输出通道数不需要乘anchor的数目,大大降低了特征图的尺寸。
loss

FPN带来的提升
anchor free的检测有没有缺点呢,当然有!因为没有了anchor,对于目标重叠或者紧挨在一起的情况,anchor free就处理不好了。如果有anchor,不同尺度和比例的anchor会把即便是一个位置预测的anchor分配到不同目标上。没有anchor就无能为力了。所以作者使用了FPN。
作者认为,对于高层特征,小目标(或者紧挨的目标)的特征值就丢失了,留下的都是大目标或者比较显著的目标特征值。如果在这样的特征图上做预测,会得到很低的recall,因为丢失了很多目标的预测。尤其是对那些ambiguous sample做预测。
所以作者使用的网络是如下图所示:
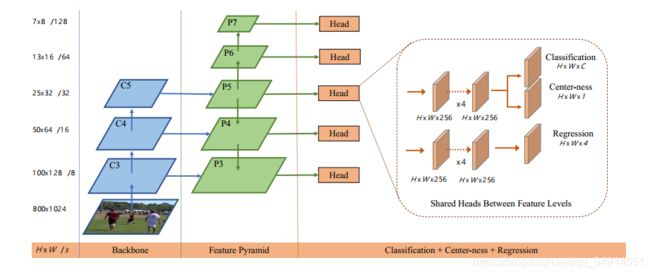

上面这一段是简单介绍了一下使用的backbone的具体结构。大家都看得懂。
anchor based 的检测给不同比例尺寸的anchor分配到不同尺度(层级)的特征图上。比如浅层特征,anchor的尺度会小一些。FCOS没有anchor,就直接限制不同尺度(层级)的特征图所能回归的距离。 如果一个位置的GT满足两个红色标注的条件,则说明这个位置不适合在当前尺度下预测位置,则这个位置不参与当前层级的回归loss计算。5个层级均有对应的范围。

FPN减弱了ambiguity的影响,但是,由于不同层级特征预测对应大小的目标,所以使用共享的head网络不合理,作者就使用了一个训练标量参数,scale每一层的特征图,再用exp映射到正值。
center ness
作者发现FPN虽然带来了提升,但仍然有些低质量的框,这些低质量的框是由离目标中心很远的位置预测得到的。作者想减弱那些离目标中心比较远的位置对应的score,达到soft的效果。作者的做法是在score分支在加一个layer预测center ness。每个特征图单元都对应一个值。预测值用sigmoid映射到0-1之间,会用来乘在score上获得最终的分数。而center ness的训练目标是按照下面公式计算得到的。
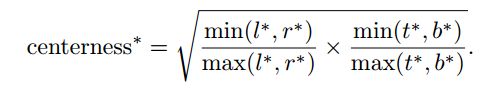
可以假设一个点,在某一个框中,被FCOS视作正样本,参与计算score和框回归,同时离框中心还很远,处于边界位置。现在想抑制住这个点的score值,按照上面的公式计算,这个点离左右框的距离比值,和离上下框的距离比值的和,应该很小。乘积值再乘上score就能抑制掉离目标中心远的位置了。注意,centerness只在测试时乘上score,训练时用上面的公式得到target。激活函数式sigmoid
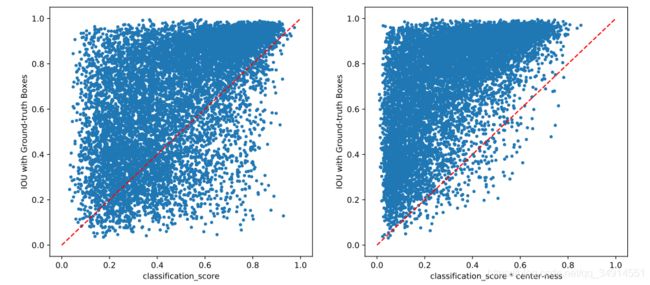
作者在实验中发现,center ness确实有作用。如果没有centerness,在预测结果中会出现不少score很高,但是box和GT的IOU很低。通过centerNess之后,抑制了很多这样的样本。
代码实践
FCOS这个工程写的很复杂。
先看模型部分,通过build_backbone建立FPN网络作为backbone,build_rpn建立head。class FCOSPostProcessor做后处理,FCOSLossComputation用于训练。
我们着重看看数据如何decode成框的吧。
在forward_for_single_feature_map函数中可以看到如果对特征图解码。输入score,reg,center ness和location。前三个就是三个分支得到的特征图,location是每个像素的坐标(按照公式映射到原图坐标)。
关键步骤有以下:
box_cls = box_cls * centerness[:, :, None] # N, H*W, C
抑制离目标中心远的特征图
detections = torch.stack([
per_locations[:, 0] - per_box_regression[:, 0],
per_locations[:, 1] - per_box_regression[:, 1],
per_locations[:, 0] + per_box_regression[:, 2],
per_locations[:, 1] + per_box_regression[:, 3],
], dim=1) # X
按照计算reg target反过去求得框的左上角,右下角坐标值。
compute_locations_per_level函数就是用来把特征图上每个坐标映射到原图坐标上的。
def compute_locations_per_level(self, h, w, stride, device):
shifts_x = torch.arange(
0, w * stride, step=stride,
dtype=torch.float32, device=device
) # 0:w*s-1:s
shifts_y = torch.arange(
0, h * stride, step=stride,
dtype=torch.float32, device=device
) # 0:h*s-1:s
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x) # 整个二维坐标,以s为间隔
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
locations = torch.stack((shift_x, shift_y), dim=1) + stride // 2 # 就是前面提到的映射公式,把坐标映射到原图上。
return locations
代码的运行需要Cpython,编译出NMS的Cpython代码。按照开源的readme安装就行了。如果没有GPU测试,还需要修改inference.py函数select_over_all_levels里面,选择使用boxlist_nms(cpu不支持ml_NMS)而不是boxlist_ml_nms
下图是我随便找了一张图片。速度虽然快,跑的是R50_FPN_1x.pth这个模型。
updated on 2020.1.9
在windows上即便有GPU,也没法成功编译,因为FCOS基于MaskRCNN-benchmark修改的,而MaskRCNN-benchmark本身就只能在Linux上编译通过。但解决方法不是没有。
首先打开setup.py,删除和CUDA有关的编译选项和文件,只编译cpu下的NMS操作。使用GPU推理的时候,在遇到NMS的地方,先把BoXList这个对象类使用to移到CPU上,NMS处理完再移到GPU上。机智!!!
下面是补充实验,我可视化了centerness。尺度是由小变大。

关于FCOS的ppt,可以点击这里下载。自己用来做组会用的。