Pandas索引操作、对齐运算、函数应用
- 11.Pandas索引操作—index对象
- 12.Pandas索引操作—重新索引
- 13.Pandas索引操作—增
- 14.Pandas索引操作—删
- 15.Pandas索引操作—改
- 16.Pandas索引操作—查
- 17.Pandas索引操作—高级索引
- 18.Pandas索引操作—作业
- 19.Pandas对齐运算—算术运算和数据对齐
- 20.Pandas对齐运算—填充值
- 21.Pandas对齐运算—混合运算
- 22.Pandas函数应用—apply和applymap
- 23.Pandas函数应用—排序
- 24.Pandas函数应用—唯一值和成员属性
- 25.Pandas函数应用—处理缺失数据
- 26.Pandas层级索引
- 27.Pandas统计计算和描述
- 28.Pandas入门总结
Pandas索引操作---index对象
import numpy as np
import pandas as pd
1. Series和DataFrame中的索引都是Index对象
ps1 = pd.Series(range(5),index=['a','b','c','d','e'])
print(type(ps1.index))
ps1

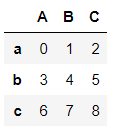
pd1 = pd.DataFrame(np.arange(9).reshape(3,3),index = ['a','b','c'],columns = ['A','B','C'])
pd1
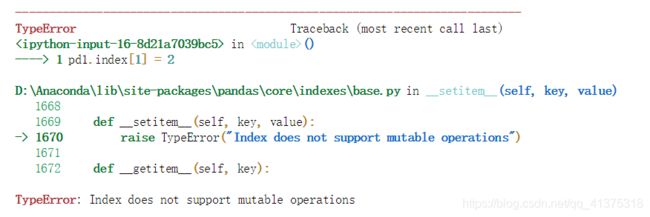
2. 索引对象不可变,保证了数据的安全
ps.index[0] = 2
ps

pd1.index[1] = 2
3.常见的Index种类
Index,索引
Int64Index,整数索引
MultiIndex,层级索引
DatetimeIndex,时间戳类型
Pandas索引操作---重新索引
二.索引的 一些基本操作
1.重新索引
2.增
3.删
4.改
5.查
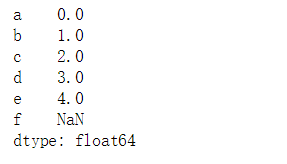
#1.reindex 创建一个符合新索引的新对象
ps2 = ps1.reindex(['a','b','c','d','e','f'])
ps2
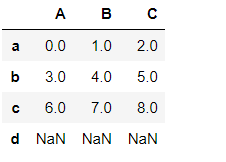
#行索引重建
pd2 = pd1.reindex(['a','b','c','d'])
pd2
#列索引重建
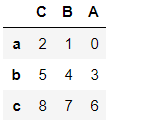
pd3 = pd1.reindex(columns = ['C','B','A'])
pd3
Pandas索引操作---增
ps1

ps1['g'] = 9
ps1

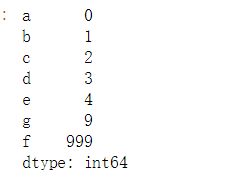
s1 = pd.Series({'f':999})
ps3 = ps1.append(s1)
ps3
pd1

#增加列
pd1[4] = [10,11,12]
pd1

# 插入
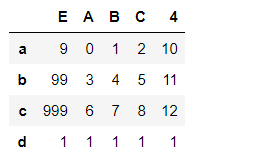
pd1.insert(0,'E',[9,99,999])
pd1

#增加行
#标签索引loc
pd1.loc['d'] = [1,1,1,1,1]
pd1
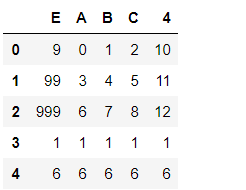
row = {'E':6,'A':6,'B':6,'C':6,4:6}
pd5 = pd1.append(row,ignore_index=True)
#ignore_index 参数默认值为False,如果为True,会对新生成的dataframe使用新的索引(自动产生),忽略原来数据的索引。
pd5
Pandas索引操作---删
#del
ps1

del ps1['b']
ps1

pd1
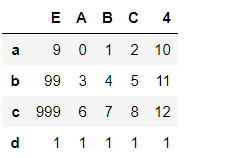
del pd1['E']
pd1
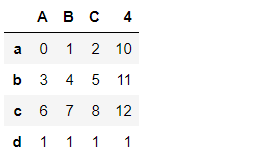
#drop 删除轴上数据
#删除一条
ps6 = ps1.drop('g')
ps6

#删除多条
ps1.drop(['c','d'])

#dataframe
#删除行
pd1.drop('a')
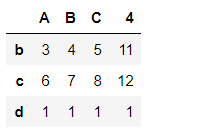
pd1.drop(['a','d'])

#删除列
pd1.drop('A',axis=1) #1列 0 行
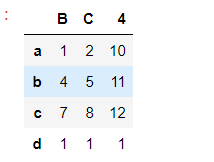
pd1.drop('A',axis='columns')
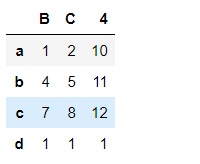
#inplace属性 在原对象上删除,并不会返回新的对象
ps1

ps1.drop('d',inplace=True)
ps1

Pandas索引操作---改
ps1 = pd.Series(range(5),index=['a','b','c','d','e'])
print(type(ps1.index))
ps1

pd1 = pd.DataFrame(np.arange(9).reshape(3,3),index = ['a','b','c'],columns = ['A','B','C'])
pd1

ps1['a'] = 999
ps1

ps1[0] = 888
ps1

#直接使用索引
pd1['A'] = [9,10,11]
pd1
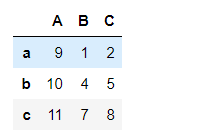
#对象.列
pd1.A = 6
pd1
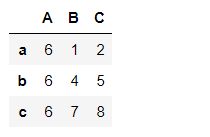
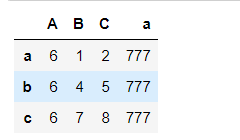
# 变成增加列的操作
pd1['a'] = 777
pd1
#loc 标签索引
pd1.loc['a'] =777
pd1

pd1.loc['a','A'] = 1000
pd1

Pandas索引操作---查
#Series
# 1.行索引
ps1

ps1['a']
![]()
ps1[0]
![]()
#2.切片
# 位置切片索引
ps1[1:4]

#标签切片 按照水印名切片操作 是包含终止索引的
ps1['b':'e']

# 3.不连续索引
ps1[['b','e']]

ps1[[0,2,3]]

# 布尔索引
ps1[ps1>2]

#dataframe
pd1
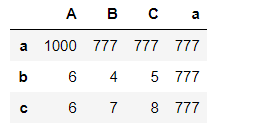
#1.列索引
pd1['A']

#取多列
pd1[['A','C']]
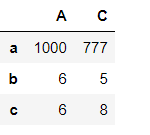
#选取一个值
pd1['A']['a']
![]()
#2.切片
pd1[:2] #获取行
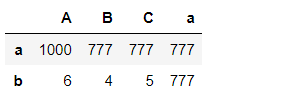
Pandas索引操作---高级索引
高级索引
loc 标签索引
iloc 位置索引
ix 标签与位置混合索引
#loc 标签索引
#loc是基于标签名的索引 自定义的索引名
ps1['a':'c']

ps1.loc['a':'c']

pd1
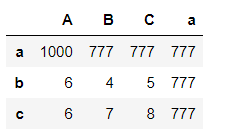
pd1.loc['a':'b','A':'C'] #第一个参数索引行 第二个是列

#2.iloc位置索引
ps1[1:3]

ps1.iloc[1:3]

pd1.iloc[0:2,0:3]

#3.ix标签与位置混合索引
ps1.ix[1:3]
ps1.ix['b':'c']

pd1.ix[0:2,0]

Pandas索引操作---作业
Pandas对齐运算---算术运算和数据对齐
import numpy as np
import pandas as pd
#Series
s1 = pd.Series(np.arange(4),index = ['a','b','c','d'])
s2 = pd.Series(np.arange(5),index = ['a','c','e','f','g'])
s1

s2

s1+s2

#DataFrame
df1 = pd.DataFrame(np.arange(12).reshape(4,3),index = ['a','b','c','d'],columns= list('ABC'))
df2 = pd.DataFrame(np.arange(9).reshape(3,3),index = ['a','d','f'],columns= list('ABD'))
df1
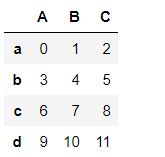
df2

df1+df2
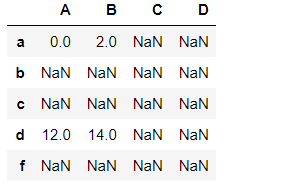
Pandas对齐运算---填充值
使用填充值的算术方法
s1
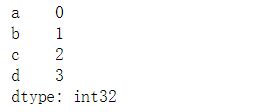
s2

s1+s2

s1.add(s2,fill_value =0 )

df1.add(df2,fill_value = 0)

1/df1

df1.rdiv(1) #字母r开头 会翻转参数

df1.reindex(columns=df2.columns,fill_value=9)

Pandas对齐运算---混合运算
DataFrame和Series混合运算
arr = np.arange(12).reshape(3,4)
arr
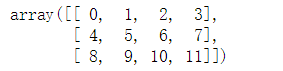
arr[0]
![]()
arr-arr[0]

df1
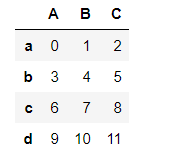
s3 =df1.iloc[0]
s3

df1-s3
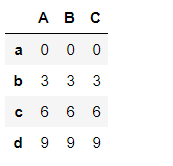
s4 = df1['A']
s4

df1.sub(s4,axis=0) # == axis=0
Pandas函数应用---apply和applymap
import numpy as np
import pandas as pd
#1.1 可以直接使用numpy的函数
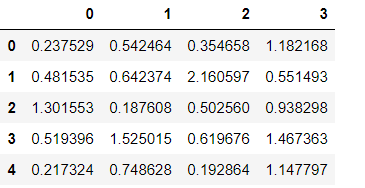
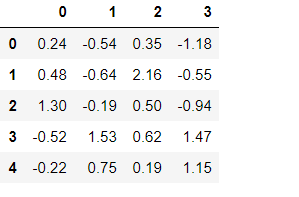
df = pd.DataFrame(np.random.randn(5,4))
df

np.abs(df)
#1.2 通过apply将函数应用到列或行
f = lambda x:x.max()
df.apply(f)
# 注意轴的方向 默认axis0 列

df.apply(f,axis=1)

#1.3通过applymap将函数应用到每个数据
f2 = lambda x:'%.2f'%x
df.applymap(f2)
Pandas函数应用---排序
2.1 索引排序
s1 = pd.Series(np.arange(4),index=list('dbca'))
s1

s1.sort_index() #默认升序

s1.sort_index(ascending = False) #降序

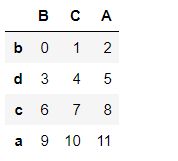
pd1 = pd.DataFrame(np.arange(12).reshape(4,3),index=list('bdca'),columns = list('BCA'))
pd1
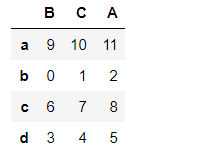
#按照行排序
pd1.sort_index()
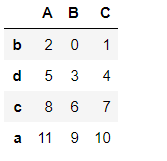
#按照列排序
pd1.sort_index(axis=1)
2.2 按值排序
s1
s1['a'] = np.nan
s1

s1.sort_values() #根据值的大小进行排序,当有缺失值,会默认排最后
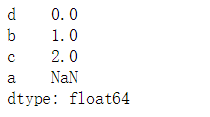
s1.sort_values(ascending=False)

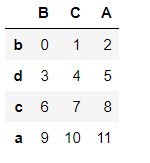
pd1
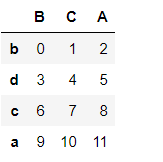
pd1.sort_values(by=['A','B'])
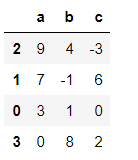
pd2 = pd.DataFrame({'a':[3,7,9,0],'b':[1,-1,4,8],'c':[0,6,-3,2]})
pd2
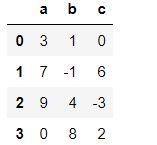
pd2.sort_values(by='b') #指定b列排序

pd2.sort_values(by=['a','c'],ascending=False) #指定多列排序
Pandas函数应用---唯一值和成员属性
s1 = pd.Series([2,6,8,9,8,3,6],index=['a','a','c','c','c','c','c'])
s1

#返回一个series中的唯一值
s2=s1.unique() #返回一个数组
s2
![]()
s1.index.is_unique
![]()
s1 = pd.Series([2,6,8,9,8,3,6])
s1

#计算series值的个数
s1.value_counts() #返回一个series

#isin 判断值是否存在 返回布尔类型
s1.isin([8]) #判断8是否存在s1

#判断多个值
s1.isin([8,2])

data = pd.DataFrame({'a':[3,7,9,0],'b':[1,-1,4,8],'c':[0,6,-3,2]})
data
data.isin([2,4])

Pandas函数应用---处理缺失数据
df3 = pd.DataFrame([np.random.randn(3), [1., 2., np.nan],
[np.nan, 4., np.nan], [1., 2., 3.]])
df3
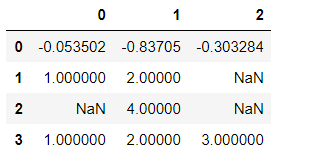
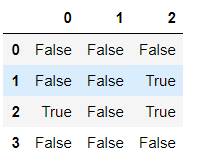
# 1.判断是否存在缺失值 isnull()
df3.isnull()
# 2.丢弃缺失数据 dropna()
df3.dropna() #默认丢弃行
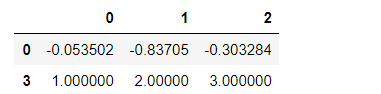
df3.dropna(axis=1)

# 3.填充缺失数据
df3.fillna(-100.)

Pandas层级索引
1.层级索引
import numpy as np
import pandas as pd
s1 = pd.Series(np.random.randn(12),index = [['a','a','a','b','b','b','c','c','c','d','d','d'],[0,1,2,0,1,2,0,1,2,0,1,2]])
s1
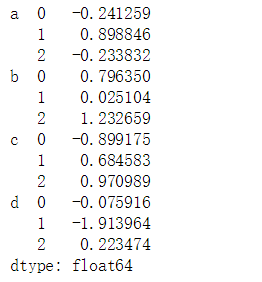
print(type(s1.index))
print(s1.index)

2.选取
#1.外层选取
s1['b']

#2.内层获取
s1[:,2]

s1['a',0]

3.交换
#1.swaplevel()交换内层和外层的索引
s1.swaplevel()

#2.sortlevel()先对外层索引进行排序,在对内层索引进行排序, 默认升序
s1.sortlevel()

#交换并排序分层
s1.swaplevel().sortlevel()

Pandas统计计算和描述
import numpy as np
import pandas as pd
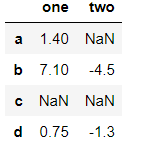
df=pd.DataFrame([[1.4,np.nan],[7.1,-4.5],
[np.nan,np.nan],[0.75,-1.3]],
index=['a','b','c','d'],
columns=['one','two'])
df
#默认按列求和
df.sum()

# 按行求和
df.sum(axis=1,skipna=False)

df.idxmax()

df.cumsum()

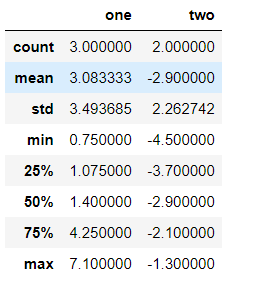
# 汇总统计
df.describe()
s1 = pd.Series(['a','a','b','c']*4)
s1

s1.describe()
