爬虫实战系列(七):scrapy获取高清桌面壁纸
声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
一.前言
电脑壁纸可谓是程序猿的第二张脸,网上高清的壁纸网站不少,而我个人比较偏爱的是WallpaperCraft,下面就将介绍如何利用scrapy框架来爬取壁纸。
二.爬取过程
2.1 项目生成
首先,生成一个scrapy项目,步骤是打开windows命令行,切换到要生成项目的地址,然后输入命令:
scrapy startproject wallpapers
生成的项目目录如下如所示:

2.2 生成spider
进入生成的项目目录,然后即可生成spider,命令如下:
scrapy genspider wallpaper wallpaperscraft.com
结果可以发现在spiders目录下多出了一个wallpaper.py文件,其中包含名为WallpaperSpider的类,即spider对应的类。
2.3 网页分析
2.3.1 页面跳转分析
进入WallpaperCraft主页,可以看到多种类型的壁纸可供选择,选取Art类型的壁纸链接打开可得如下界面:
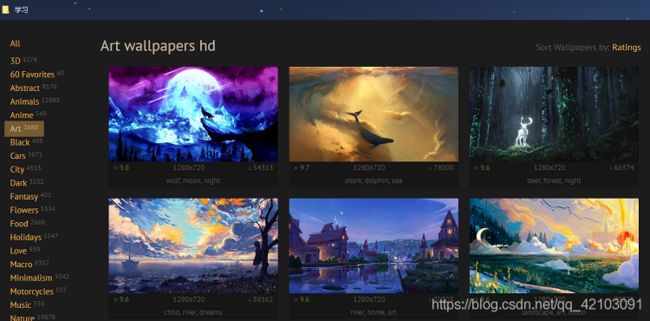
点击几次下方的箭头"->",即换页,查看对应的URL如下所示:
https://wallpaperscraft.com/catalog/art/page2
https://wallpaperscraft.com/catalog/art/page3
https://wallpaperscraft.com/catalog/art/page4
可得对应的URL中变化的只有page字段,因此跳转只需要更给page后所更的数字即可。
2.3.2 页面中的图片URL获取
在壁纸所在的网页(仍是2.3.1图示的那一页)选取第一张图片->右键->检查即可查看对应元素的源代码,部分源码截图如下:

上图中的URL展示如下:
https://images.wallpaperscraft.com/image/wolf_moon_night_150508_300x168.jpg
但该链接并不是指向原图,从链接可得其分辨率为 300 × 168 300\times168 300×168,而原图的分辨率为 1280 × 720 1280\times720 1280×720,因此该url并不是我们想要的,于是我点击了该图上方的一个链接,出现下图所示界面:

选中上述图片,右键然后复制图片链接地址如下:
https://images.wallpaperscraft.com/image/wolf_moon_night_150508_1280x720.jpg
可知该url才是指向原图的链接,观察可得该链接与之前的链接基本一致,唯一不同的是分辨率部分一个为 300 × 168 300\times168 300×168,而另一个为 1280 × 720 1280\times720 1280×720,因此只需要将之前链接的子串300x168替换为'1280x720'即可。
2.4 在Items内定义域
由于是下载图片,因此只需在items.py文件内给WallpapersItem类添加一个名为image_urls的域即可,顾名思义该域用来存储图片的链接,示例代码如下:
class WallpapersItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field() #图片链接
2.5 完善spider
经过以上的分析,我们即可进行WallpaperSpider类的完善,首先将start_urls删除改为使用方法start_requests,可得art类型的壁纸页面共有180页,因此可以通过循环生成180个链接,然后通过生成器产生180个请求对象(Request),示例代码如下:
def start_requests(self):
page_num = 180
for i in range(1,page_num + 1):
url = "https://wallpaperscraft.com/catalog/art/page{}".format(i)
yield scrapy.Request(url,callback=self.parse)
另外,我们还需要重写parse(self, response)方法,根据上面的分析,我们可以利用BeautifulSoup解析出对应的URL,然后进行替换操作就可以得到原图的URL,然后URL对象生成一个Item类对象并返回,示例代码如下:
def parse(self, response):
soup = BeautifulSoup(response.text,'lxml')
images = soup.findAll('img',attrs={'class':'wallpapers__image'})
image_urls = []
for image in images:
link = image.get('src')
image_urls.append(link.replace('300x168','1280x720'))
item = WallpapersItem()
item['image_urls'] = image_urls
return item
2.6自定义ImagesPipeline类
进入pipelines.py文件,在其中自定义一个继承于ImagesPipeline类的子类WallpapersImageDownloadPipeline,然后重写图像管道类的方法get_media_requests(self, item, info)和file_path(self, request, response=None, info=None),示例代码如下:
class WallpapersImageDownloadPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for url in item['image_urls']:
yield scrapy.Request(url)
def file_path(self, request, response=None, info=None):
return request.url.split('/')[-1]
2.7 修改配置文件
要想最后成功运行还需要进入settings.py文件进行相应的配置设置。首先,需要开启图像管道,示例代码如下:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'wallpapers.pipelines.WallpapersImageDownloadPipeline': 300,
}
然后可以设置图片保存的路径,示例代码如下:
IMAGES_STORE = 'images' #设置图片的保存路径
2.8 启动爬虫程序
启动仍然在命令行进行,首先进入爬虫项目的路径,然后输入如下命令:
scrapy crawl wallpaper
三.结果展示
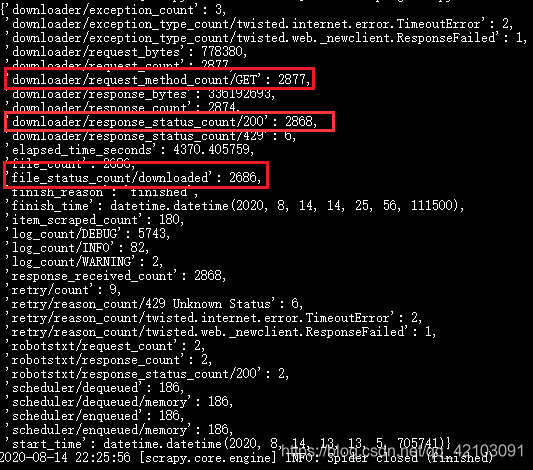
命令行对此次爬虫的总结见下图,可得总共有2877个请求,但最终下载下的图片只有2686张
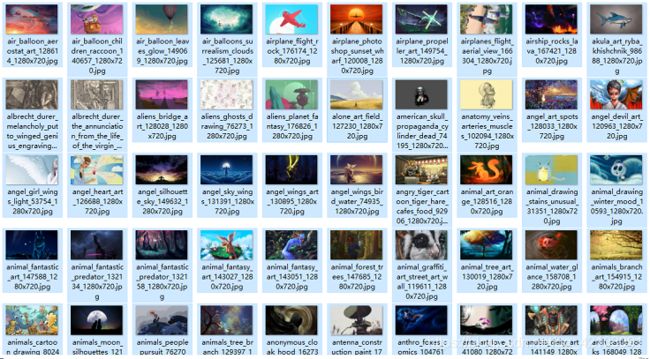
部分爬取图片展示如下:
完整工程下载地址:wallpapers
以上便是本文全部内容,要是觉得不错支持一下吧,若有不多的地方或者有什么改进的建议也请指正!!!