python构建词向量分析《笑傲江湖》人物之间的关系
首先进行jieba分词,去除停用词;然后通过正则表达式去除无关字符,构建词向量;最后提取小说的所有人名并画图展示出来。
import jieba
import re
from gensim.models import Word2Vec
#读取数据
file = open(r'笑傲江湖.txt',encoding = 'utf-8')
text = file.readlines()
file.close()
#将换行符等特殊字符替换掉
text1 = text[1:] #第一行是这本小说的作者信息
text2 = [re.sub('\u3000| |\n','',i) for i in text1]
#分词,去除停用词
with open(r'停用词.txt','r',encoding = 'utf-8') as f:
stop_words = f.reanlines()
text_cut = [jieba.lcut(i) for i in text2]
stop_words = [re.sub(' |\n','',i) for i in stop_words]
text_ = [[i for i in word if i not in stop_words] for word in text_cut]
#构建词向量
my_wv = WordVec(text_,size = 200,min_counts = 5,window = 2,iter = 100)
#查看词向量
name = '令狐冲'
print(my_wv[name])
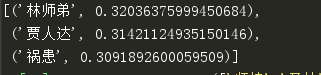
print(my_wv.similar_by_word(name,topn=3)) #查看跟'令狐冲'相关性前三的词
#查看跟令狐冲关系相当于师妹跟林平之的关系的词
my_wv.most_similar(['师妹','林平之'],[name],topn=3)
#查看跟令狐冲关系相当于师妹跟圣姑的关系的词
my_wv.most_similar(['师妹','圣姑'],[name],topn=3)#查看跟令狐冲关系相当于师妹跟林平之的关系的词
import jieba.posseg as poss
#分词后对词的属性进行分析
a = poss.lcut('林平之是谁')
print(a)
print([list(i)[0] for i in a if list(i)[1] == 'nr'])
print(list(a[0])[1] == 'nr')
print(list(a[0])[0])![]()
#提取这本小说里的所有人名
temp = [poss.lcut(i) for i in text2]
people = [[i.word for i in x if i.flag =='nr'] for x in temp]
temp2 = [' '.join(x) for x in people]
people2 = list(set(' '.join(temp2).split()))
data = []
newpeo = []
for i in people2:
try:
data.append(my_wv.wv[i])
newpeo.append(i)
except KeyError:
pass#PCA降维后画图
from sklearn.decomposition import PCA
data2 = PCA(n_components=2).fit_transform(data)
print(len(data))
print(data2.shape)#(514,2)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15,15),dpi=360)
for i in range(len(data2)):
plt.scatter(data2[i,0],data2[i,1])
plt.text(data2[i,0],data2[i,1],newpeo[i])
plt.savefig('foo.png') #保存到本地
plt.show()如果plt.show()显示的是空白的图的话就先将图片保存到本地,然后在打开图片查看即可。
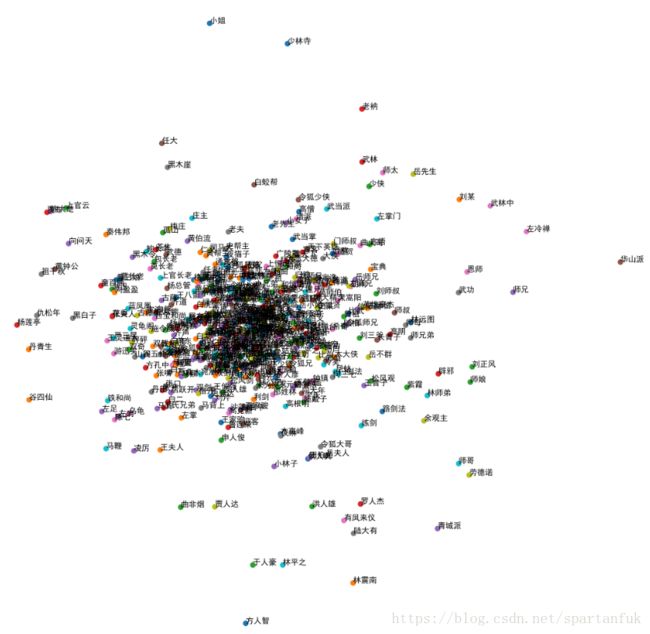
中间那一堆密密麻麻的应该是跑龙套的演员,放大一部分查看。
