图像相似度计算-kmeans聚类
关于图像相似度,主要包括颜色,亮度,纹理等的相似度,比较直观的相似度匹配是直方图匹配.直方图匹配算法简单,但受亮度,噪声等影响较大.另一种方法是提取图像特征,基于特征进行相似度计算,常见的有提取图像的sift特征,再计算两幅图像的sift特征相似度.对于不同的图像类型,也可以采用不同的特征,例如对于人脸如下,可以采用人脸识别网络提取人脸特性向量.本文介绍利用LightCNN提取人脸特征向量,并进行图像聚类的方法.
首先提取图像特征向量,由于是对人脸图像进行聚类,因此采用LightCNN提取图像的特征向量,github代码和模型下载:https://github.com/AlfredXiangWu/LightCNN.
下载代码和模型后,运行,extract_features.py提取图像的特征向量,LightCNN提取特征向量为256维.
将所有图片的特征向量保存在一个矩阵中,特征矩阵.例如有10张图像,则特征矩阵为 10×256 10 × 256 的矩阵.
之后采用kmeans对特征向量进行聚类:
feature_matrix = np.asarray(cPickle.load(open('features.pkl','rb')),'rb')))
num_clusters = 6
km_cluster = KMeans(n_clusters=num_clusters, max_iter=300, tol=1e-10,n_init=40, \
init='k-means++',algorithm='full', n_jobs=-1)
result = km_cluster.fit(feature_matrix)feature_matrix为特征矩阵,将图像聚类为num_clusters 类,result为聚类结果,包含聚类类别,聚类中心等.
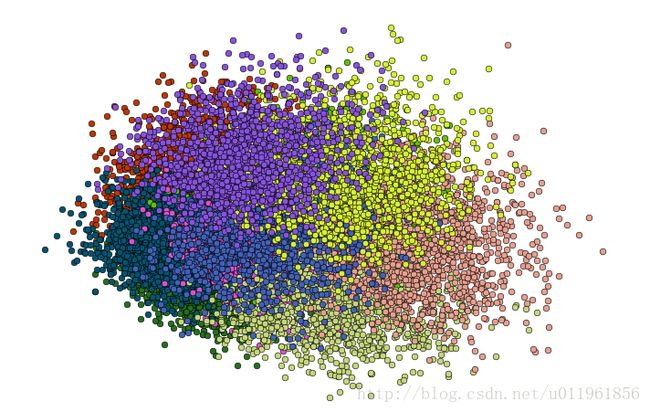
关于图像聚类结果显示,由于每张图像大小不同,而图像的特征向量为256维,不能直接显示.因此采用pca对特征向量进行降为.具体为将256维特征向量降为2维,即坐标点x,y,这样便可以在二维空间将聚类结果可视化.
pca = PCA(n_components=2) #输出两维
newData = pca.fit_transform(feature_matrix ) #载入N维最后每张图像的坐标点按照聚类类别标记为不同的颜色,从而可视化:
x1 = []
y1 = []
x2 = []
y2 = []
x3 = []
y3 = []
x4 = []
y4 = []
x5 = []
y5 = []
labels=result.labels_
for i in xrange(len(feature_matrix)):
if labels[i] == 0:
x1.append(newData[i][0])
y1.append(newData[i][1])
elif labels[i] == 1:
x2.append(newData[i][0])
y2.append(newData[i][1])
elif labels[i] == 2:
x3.append(newData[i][0])
y3.append(newData[i][1])
elif labels[i] == 3:
x4.append(newData[i][0])
y4.append(newData[i][1])
elif labels[i] == 4:
x5.append(newData[i][0])
y5.append(newData[i][1])
# 四种颜色 红 绿 蓝 黑
plt.plot(x1, y1, 'or')
plt.plot(x2, y2, 'og')
plt.plot(x3, y3, 'ob')
plt.plot(x4, y4, 'ok')
plt.plot(x5, y5, 'om')
plt.show()聚类效果: