最近准备用Resnet来解决问题,于是重读Resnet的paper
《Deep Residual Learning for Image Recognition》, 这是何恺明在2016-CVPR上发表的一篇paper,在2015年12月已经发布在arXiv上,并且用文中所述的网络在 2015年 的ILSVRC获得分类任务冠军,在2015-COCO detection,segmentation 的冠军.
先说一下新的收获:
结合了caffe的prototxt才知道, F(x) + x ,是 element-wise addition , 是逐元素相加,之前以为是在通道那个维度进行连接呢.
cifar10 实验中, Data Aumentation的方法,在 32*32的基础上行进行padding , 得到 36*36的图片,然后再随机的crop出 32*32 的,这种方法是([24] C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeply-supervised nets. ArXiv:1409.5185, 2014.) 当中提到的. 以后可以考虑这种方法
在cifar10的实验当中, 训练 resnet-110时, 初始学习率不能像之前那样设置为0.1 而是设置成 0.01, 等到训练了400 个interactions 时,再把学习率增大到0.1 ( 差不多3个epochs的时候, 把学习率增大到
0.1) . 这种一开始小, 然后大的方法, 可以借鉴.
Abstract:
深层网络难以训练, 而深层的Resnet 可以训练得很好. Resnet改变传统神经网络学习的内容, 传统上,让神经网络直接学习(mapping)一个复杂函数, 而Resnet是让网络学习一个Residual function (文中提及的 F(x) ) . 而且证明了这样效果好, 获得了多个竞赛任务冠军.
Introduction:
神经网络越深可以得到的特征的”level”越丰富 .越深就越好. 想要更好,就要越深. 越深,那么问题就来了.
两个问题: 1. vanishing/exploding gradients 2. degradation problem
针对1. 有batch normalization 以及 intermediate normalization layers 这两种方法来解决,但是也就在几十层内奏效
问题2. 越深, 反而训练 error 越高. 主要是深了, 不好训练
存在问题, Resnet就是来解决问题的. 利用 residual learning frame 解决 问题2.degradation problem. 就是越深, training error 没有像之前那样会升高, 而是降低. 到底residual是什么意思呢? Residual function 是什么function呢?
通常, 神经网络学习的输入是 x, 输出是 y = H(x), 那么神经网络学习的是一个映射H(). 直接学习H()可能不那么容易, 那么假设 H() 是这样一个形式, 就是 H(x) = x + F(x) . 再假设一个条件, 就是我们要学习的映射是一个 identity mapping的话, 直接学习 H() 不容易, 然而 学习 x +F(x) 就容易了. 以为让 F(x)等于0 ,那么好了. 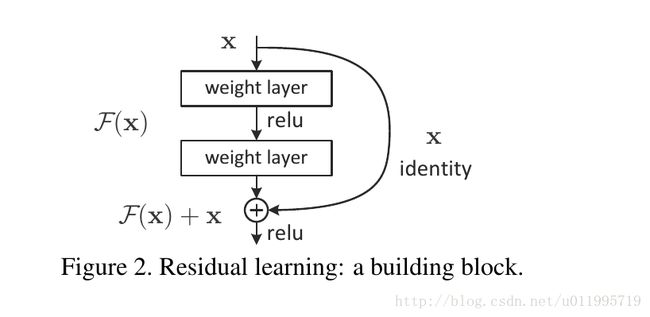
F(x) + x 这个形式可以理解为传统的前向神经网络 加上一个 shortcut connections ,什么意思呢? 如上图:
Related work
Residual representation, 讲到 VLAD ,VLAD是通过Residual vector 编码得到的一种 representation .结果显示很还不错.( 要深究的话, 还要去看看文中给的文献, 到底residual vector是什么概念, 作者是如何想到把residual vector的思想给用到这里来的)
shortcut connections, 说到shortcut connections 的工作被人研究了不少年了, 给了一些 关于 shortcut connections 的paper . 最后对比highway networks , highway networks 的shortcut connections 有一个gating functions, 而Resnet没有. 这样就不会增加额外的参数 .
Deep residual learning
residual learning , 就是 将本来是学习 H(x) 这样一个映射, 现在把映射变成 x +F(x) 了.
先假设本身要映射的是一个identity mapping , 那么 x + F(x)映射 要比 H(x)这个映射要来得简单, 然后说, 实际情况并不像 学习一个 identity mapping , 但是, 这样做有助于解决 precondition 问题.
(终究搞不懂为什么work ,反正paper中说这样做的效果好, 做了实验也是好….)
Identity mapping by shortcuts
定义一个 building block 是这样的 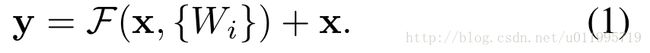
F(x {w}) 要和 x 相加, 那么经过 F()的映射, 维度可能发生变化, 维度不同是不能相加的, 所以作者探讨了如何使x的维度与F()一致. 一种方法就是给x一个线性变换, 就是wx的方法( 经过实验, 最终并不是用这个方法)
看图 , 当虚线部分那里, feature maps 是56*56*64 然后要变成 28 * 28 * 128 , 这样维度就不一样了,
所以要对shortcut connections 进行操作,使得 56* 56 * 64 变得和 28* 28 *128一致
这里有两种方法(1) 补零 . (2) 线性变换
Experiments
实验部分主要是做了 imagenet 和cifar10 的实验, 对于imagenet 主要是对标vgg, 更深,参数更少,性能更好. 对于cifar10 主要是验证深层resnet的性能, 并不对标state of the art.
如果有做相应实验的话, 建议看一看作者的实验描述, 讲得还是很详细的.