OpenCV库的KNN算法使用
本文主要记录了KNN(K-Nearest Neighbor)算法的训练及在OpenCV库中的使用方法,主要分为以下几个部分:
1. KNN算法简介
2. KNN的训练方法
3. OpenCV中KNN的调用流程
4. 参考资料
一. KNN算法简介
KNN(K-Nearest Neighbor)即K最临近算法,属于机器学习中非参数估计(nonparametric estimation)的一种,在非参数估计中,我们只假设相似的输入具有相似的输出,这是一种合理的假设:世界是平稳的,并且无论密度,判别式还是回归函数都是缓慢地变化,KNN算法则是这种思想的一种具体体现。
所谓最邻近算法,即给定一个已训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近(注:衡量邻近的标准以具体选取的某个特征而言,例如下面示意图中使用的特征为欧式距离)的K个实例,这K个实例的多数属于某个类,则判定该输入实例同属此类。如下图所示:训练者取k值,计算以欧氏距离k为半径的圆内其他类别的个数,图中中心小红点以k为半径的圆内三角形个数最多,则判定中心小红点为三角形。
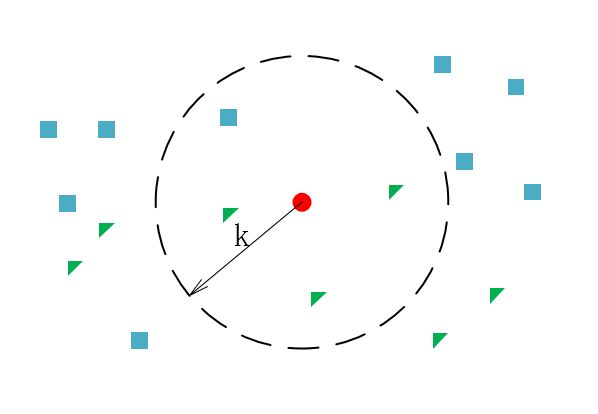
图一.KNN示意图
二.KNN的训练方法
自KNN算法诞生以来,出现了很多的训练方法,非参数方法的时间和空间复杂度与训练集成正比,因此对训练集的精简显得十分必要,其基本思想是选择训练集X的最小子集Z使得用Z代替X时,误差不增加(Dasarathy 1991)。
最著名和最早的方法是精简的最邻近(condensed nearest neighbor),由Hart在1968年提出,他同时提出了一种发现训练集X最小子集Z的贪心算法:该算法从空集Z开始,以随机次序逐个扫描X中的实例,并检查它们能否被 1-nn 用已经在Z中的实例正确分类,如果一个实例被错误分类,则将它添加到Z中;如果它被正确分类,则舍弃此实例。
通过上面的方法可以降低训练集的冗余度,从而减小算法在时间与空间的复杂度。使用该方法时,应当扫描数据多遍,知道没有实例再添加到Z中。该算法进行局部搜索,并且依赖于扫描X中实例的顺序,不同的扫描顺序可能找出不同的子集,每个子集在确认数据上具有不同的准确率。因此,不能保证找到最小的相容子集。找出最小相容子集是NP-完全问题(Wilfong 1992)。该贪心算法的流程图如下所示:

图二.训练流程图
三.OpenCV中的KNN调用流程
针对特定场景使用KNN算法训练之后通常会得到两个文件,一个文件用于保存训练样本数据,另一个文件用于保存各训练样本所对应的分类。有了这两个文件之后,使用OpenCV中提供的KNN相关函数读取此两个文件用于识别新的数据得到其所属的类别。此处使用GitHub上面的一个车牌识别工程进行说明,该工程地址在参考资料部分贴出。
此工程中使用KNN算法进行车牌识别,工程主目录下的两个xml文件images.xml与classification.xml中保存的即是KNN训练后的结果,两个文件的部分截图如下。其中较大的文件images.xml中保存的为归一化后的车牌字符图片灰度值,classification.xml中保存的images文件中各组图片灰度值对应的的分类(如截图所示两个文件的rows均为180,image中的180组数据对应着classification种相应的类别编码)
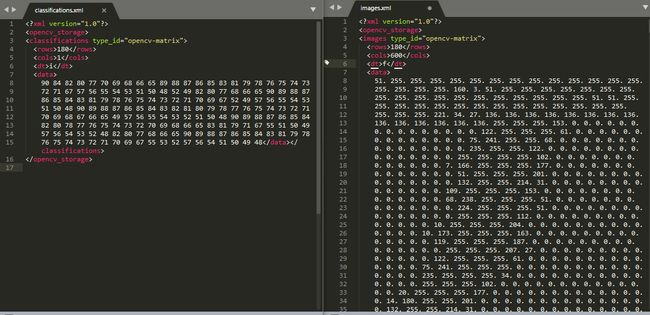
图三.KNN训练结果
使用OpenCV中相关函数调用训练后的文件进行识别的简易过程如下:
cv::Mat matClassificationInts; //将会读取classification.xml中的内容到此Mat变量中
cv::FileStorage
fsClassifications("classifications.xml",cv::FileStorage::READ); // 打开classification.xml
fsClassifications["classifications"] >> matClassificationInts; // 读取classification.xml中的数据到前面的matClassificationInts变量中
fsClassifications.release(); //释放fsClassifications
//如上操作,读取images.xml数据到matTrainingImagesAsFlattenedFloats中
cv::Mat matTrainingImagesAsFlattenedFloats;
cv::FileStorage fsTrainingImages("images.xml",cv::FileStorage::READ);
fsTrainingImages["images"] >> matTrainingImagesAsFlattenedFloats;
fsTrainingImages.release();
// train
// finally we get to the call to train, note that both parameters have to be of type Mat (a single Mat)
// even though in reality they are multiple images / numbers
kNearest->setDefaultK(1); //设置KNN算法中的K值为1
kNearest->train(matTrainingImagesAsFlattenedFloats, cv::ml::ROW_SAMPLE, matClassificationInts);
// finally we can call find_nearest !!!
//matROIFlattenedFloat为待识别图像
//1为K值
//matCurrentChar为识别后结果,即classification中对应的数据
kNearest->findNearest(matROIFlattenedFloat, 1, matCurrentChar); 四.参考资料
- Ethem Alpaydin.机器学习导论[M].机械工业出版社,2015.11
- 本文参考工程GitHub地址OpenCV_3_License_Plate_Recognition_Cpp