(2) [NeurIPS12] ImageNet Classification with Deep Convolutional Neural Networks
计划完成深度学习入门的126篇论文第二篇,摘自多伦多大学Alex Krizhevskyh和Geoffrey Hinton合著发表在NeurIPS2012的论文,同时也算是2012年ImageNet的冠军得主论文。
摘要Abstract
论文作者训练了一个大型深度卷积神经网络来对120万的高分别率图片做1000分类,并且优于之前的精度记录。使用了6000万个参数以及65万个神经单元。在前五层神经网络使用了最大池化层,以及三层的全连接层,在最后一层使用了1000-softmax。为了使计算更快捷使用了GPU来做计算,并且使用dropout来避免过拟合。
The
neural network, which has 60 million parameters and 650,000 neurons, consists
of five convolutional layers, some of which are followed by max-pooling layers,
and three fully-connected layers with a final 1000-way softmax. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation. To reduce overfitting in the fully-connected
layers we employed a recently-developed regularization method called “dropout”
that proved to be very effective.
一、介绍
1. 传统的方式是使用大量的机器学习方法。为了提高效果,收集了大量数据集,使用了计算力更大的模型,使用更好的防止过拟合的技巧。直到近期已经在MNIST上达到了和人类效果更好的误差率,但是在实际的展示图片中,我们还需要更大的训练集。
2. 为了学习到数百万张图片,我们需要一个更大的学习能力模型。在深度学习中,不同的深度和宽度决定了他们的能力。和标准的前向网络相比,CNN使用的参数更少,所以更容易训练。
3. 尽管CNN这么有吸引力,我们还是需要昂贵的计算资源来训练这些大量的高分辨率的图片。目前的GPUs就很适合做这件事情。
4. 在比赛中,我们写了一个高优化的GPU框架来处理2D卷积,所以我们大大减少了训练时间同时也提高了结果表现。最终我们发现了一个最优的框架结构,使用5层的卷积网络和3层的全连接层,不管是减少哪一层都会带点至少1%的误差率。
5. 最后一共花了五六天时间训练才得到结果,也提出未来如果有更大的数据集和更快的GPU,效果还会更好。(博主补充:已经有啦,而且更新了好几代,ImageNet这个比赛现在的结果也刷新了2012年的好几次记录,特别是何凯明的RestNet后)
二、数据集
ImageNet数据集包含了超过1500万个高精度带标签的图像,从属于22000个类别。这些图片从网络上被收集,并被人工标签,使用的是亚马逊的框图云技术,类似于把图片中的物体使用框划分出来,并且归类。一共大约120万张图片,50000张是验证集,150000是测试集。
根据2012年的比赛提供的测试集,在ILSVRC-2012我们也测试了这个版本的数据集的结果,对于这个版本的数据集,测试集标签是不可用的。在ImageNet上,通常报告两个错误率:top-1和top-5,其中top-5错误率是测试图像中,正确的标签不在模型认为最可能出现的五个标签中的比例
在实验数据中,我们下采样down-sampled固定的图像分辨率为256×256。给定一个矩形图像,我们首先重构图片大小,短边长度是256,然后裁剪出中央256×256固定大小的图像。我们没有以任何其他方式对图像进行预处理,只是从每个像素中减去训练集上的平均像素。因此,我们将在(居中)像素的原始RGB值上进行网络训练。
三、架构
1. 网络架构:five convolutional and three fully-connected
![(2) [NeurIPS12] ImageNet Classification with Deep Convolutional Neural Networks_第1张图片](http://img.e-com-net.com/image/info8/a31ef2063b1742f8b5a88c1cfe8c898c.jpg)
2. 非线性激活函数ReLU
① f(x) = tanh(x) or f(x) = (1 + e-x)-1
② 在实验中发现,ReLU显然别tanh更快。
③ 并且ReLU的误差也比tanh小得多,如下图中,实线是ReLU取得了25%的误差率。
![(2) [NeurIPS12] ImageNet Classification with Deep Convolutional Neural Networks_第2张图片](http://img.e-com-net.com/image/info8/8c1574a4c35a462f85f854e1349d351b.jpg)
3. 在GPU上训练( GTX 580 GPU has only 3GB)
并且提出实际上,在最终的卷积层中,1- gpu网络与2- gpu网络拥有相同数量的内核。这是因为大多数的网络的参数都在第一个全连通层中,该层以最后一个卷积层作为输入。因此,为了使这两个网络具有大致相同数量的参数,我们没有将最终卷积层的大小减半(也没有将随后的完全连接层减半)。因此,我们偏向于使用1-GPU网络,因为它比2-GPU网络的一半还要“大”。
4. 局部正则
ReLUs具有一个理想的特性,即它们不需要输入标准化来防止饱和。如果至少有一些训练的例子产生一个积极的输入到一个ReLU,学习将发生在那个神经元。然而,我们仍然发现以下的局部归一化方案有助于推广。为ai x;y,在位置(x;然后应用ReLU非线性,响应归一化活动bi x;y由表达式给出

其中sum运行在相同空间位置的n个“相邻”内核映射上,n是层中内核的总数。内核映射的顺序当然是任意的,在训练开始之前就确定了。这种反应正常化实现了一种形式的横向抑制,其灵感来自于在真实神经元中发现的类型,在使用不同内核计算的神经元输出之间产生了对大型活动的竞争。
四、减少过拟合程度
我们的神经网络架构有6000万个参数。尽管ILSVRC的1000个类使每个训练示例对从图像到标签的映射施加10位约束,但如果不进行大量的过拟合,这对于学习这么多参数来说是不够的。下面,我们将介绍两种主要的方法来对抗过拟合。
1. 数据增强:Data Augmentation
减少图像数据过拟合最简单、最常用的方法是使用标签保留转换人为地放大数据集。
我们采用了两种不同的数据扩充形式,这两种形式都允许从原始图像中生成转换后的图像,而只需很少的计算,因此转换后的图像不需要存储在磁盘上。在我们的实现中,转换后的图像是在CPU上的Python代码中生成的,GPU正在对前一批图像进行训练。因此,这些数据扩充方案实际上是不需要计算的。
- 第一种方式是生成翻转平移图像。我们从256x256幅图像中随机抽取224x224的块(以及它们的水平反射),并在这些提取的块上训练我们的网络。
- 第二种是用RGBchannels来训练图像。并且使用PCA来对图像训练集降维。
![]()
2. dropout:结合许多不同模型的预测是减少测试误差的一个非常成功的方法
- 然而,有一个非常有效的模型组合版本,在训练期间只需要花费大约2倍的成本。最近引入的dropout技术是将每个隐藏神经元的输出设置为0,概率为0.5。
- 以这种方式脱落的神经元不参与正向传递,也不参与反向传播。所以每次输入出现时,神经网络都会对不同的架构进行采样,但是所有这些架构都共享权重。
- 这种技术减少了神经元复杂的共适应,因为神经元不能依赖于特定的其他神经元的存在。因此,它被迫学习与其他神经元的许多不同随机子集一起使用的更健壮的特征。
- 在测试时,我们使用所有的神经元,但是将它们的输出乘以0.5,这是一个合理的近似,近似于取指数众多drop - in网络产生的预测分布的几何平均值。
五、学习中的细节
1. 权重更新的规则
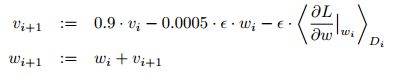
2. 初始化
我们初始化每一层的权值,从标准差为0.01的零均值高斯分布开始。我们用常数1初始化了第二层、第四层、第五层卷积层以及完全连通的隐层中的神经元偏差。这个初始化通过为ReLUs提供积极的输入来加速学习的早期阶段。我们用常数0初始化剩余层的神经元偏差bias。
3. 学习率
- 我们对所有层使用相同的学习率。
- 我们采用的训练方法是,当验证错误率不再随着当前学习率的提高而提高时,将学习率除以10。
- 初始化学习率为0.01,终止前降低6倍。
我们通过120万张图像的训练集对网络进行了大约90个周期的训练,这组图像在两台NVIDIA GTX 580 3GB gpu上运行了5到6天
六、实验结果
ILSVRC-2010的结果在Table1中,在ILSVRC-期间获得的最佳性能2010年的竞争是47.1%和28.2%,采用的方法是将针对不同特征的6个稀疏编码模型的预测结果平均。
![(2) [NeurIPS12] ImageNet Classification with Deep Convolutional Neural Networks_第3张图片](http://img.e-com-net.com/image/info8/5619ecd9cfee47739beb5965de791091.jpg)
![(2) [NeurIPS12] ImageNet Classification with Deep Convolutional Neural Networks_第4张图片](http://img.e-com-net.com/image/info8/ad79bb487d004b0787f5a26bff06424e.jpg)
在这个ILSVRC-2012数据集上,我们遵循文献中使用一半图像用于训练,一半用于测试的惯例。由于没有建立测试集,我们的分割必然不同于以前的作者所使用的分割,但是这不会显著地影响结果。
我们在这个数据集上的前1和前5的错误率是67.4%和40.9%,这是通过上面描述的网络实现的,但是在最后一个池层的基础上增加了第6个卷积层。在这个数据集上发表的最佳结果是78.1%和60.9%。如Table2。
![(2) [NeurIPS12] ImageNet Classification with Deep Convolutional Neural Networks_第5张图片](http://img.e-com-net.com/image/info8/3e6f31173c3b4d608ce6d0bbe08eed1a.jpg)
在图4的左侧面板中,我们通过计算8张测试图像的前5个预测,定性地评估了网络已经了解到的内容。请注意,即使是偏离中心的物体,如左上角的螨虫,也能被网络识别出来。大多数排名前五的标签看起来都是合理的。例如,只有其他类型的猫被认为是豹子的合理标签。在某些情况下(格栅、樱桃),照片的预定焦点确实模糊不清。
如果两幅图像产生欧氏距离的特征激活向量,我们可以说神经网络的高层认为它们是相似的。图4显示了来自测试集的5张图像和来自训练集的6张图像,根据这个度量,这6张图像与每个图像最相似。注意,在像素级别上,在L2中检索到的训练图像通常不接近第一列中的查询图像。例如,检索到的狗和大象以各种姿势出现。我们在补充材料中提供了更多测试图像的结果。利用两个4096维实值向量之间的欧几里得距离计算相似度效率不高,但通过训练一个自动编码器将这些向量压缩成短二进制码可以提高计算效率。这将产生一种比对原始像素应用自动编码器更好的图像检索方法,原始像素不使用图像标签,因此具有检索具有相似边缘模式的图像的趋势,无论它们在语义上是否相似。