详解Pandas用法_02
原文地址:http://www.huaxiaozhuan.com/%E5%B7%A5%E5%85%B7/pandas/chapters/pandas.html
目录
六、数据清洗
1. 移除重复数据
2. apply
3. 缺失数据
4. 离散化
七、 字符串操作
八、 聚合与分组
1. 分组
2. GroupBy对象
3. 分组级运算
4. 透视表和交叉表
九、时间序列
1. Python 中的时间
2. 时间点 Timestamp
3. 时间段 Period
4. DatetimeIndex
5. PeriodIndex
6. resample 和频率转换
十、 DataFrame 绘图
十二、 数据加载和保存
1. 文本文件
2. Json
3. 二进制文件
4. Excel 文件
5. HTML 表格
6. SQL
六、数据清洗
1. 移除重复数据
-
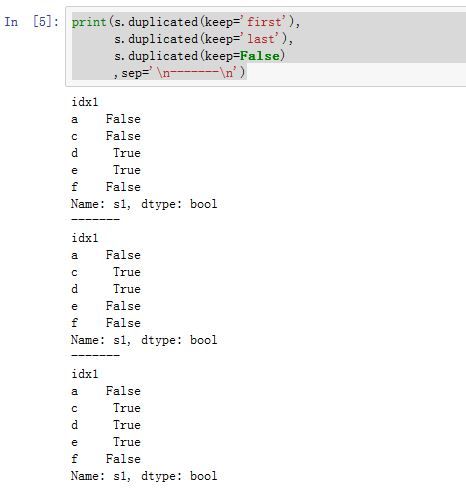
Series/DataFrame.duplicated(*args, **kwargs):返回一个布尔Series,指示调用者中,哪些行是重复的(重复行标记为True)。-
keep:一个字符串或者False,指示如何标记。它代替了废弃的参数take_last'first':对于重复数据,第一次出现时标记为False,后面出现时标记为True'last':对于重复数据,最后一次出现时标记为False,前面出现时标记为TrueFalse:对于重复数据,所有出现的地方都标记为True
而
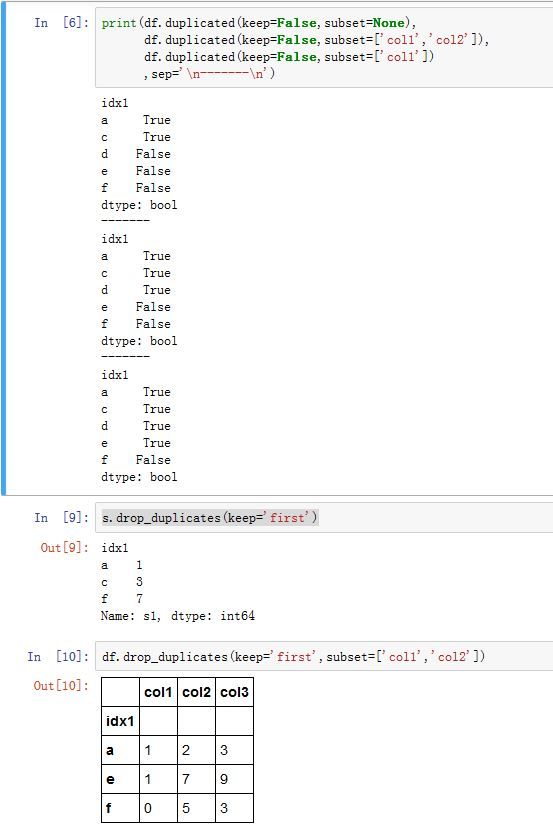
Series/DataFrame.drop_duplicates(*args, **kwargs):返回重复行被移除之后的Series/DataFrame。-
keep:一个字符串或者False,指示如何删除。 它代替了废弃的参数take_last'first':对于重复数据,保留第一次出现,后面出现时删除'last':对于重复数据,最后一次出现时保留,前面出现时删除False:对于重复数据,删除所有出现的位置
-
inplace:一个布尔值。如果为True,则原地修改。否则返回新建的对象。
对于
DataFrame,还有个subset参数。它是column label或者其列表,给出了考虑哪些列的重复值。默认考虑所有列。(即一行中哪些字段需要被考虑)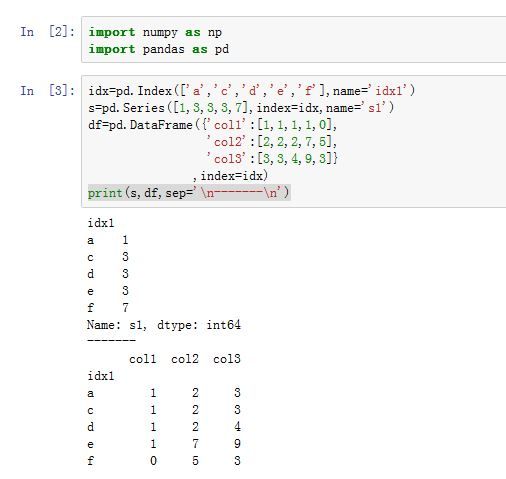
-
2. apply
-
你可以使用
numpy的ufunc函数操作pandas对象。 -
有时,你希望将函数应用到由各列或者各行形成的一维数组上,此时
DataFrame的.apply()方法即可实现此功能。.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)func:一个可调用对象,它会应用于每一行或者每一列axis:指定应用于行还是列。如果为0/'index',则沿着0轴计算(应用于每一列);如果为1/'columns',则沿着1轴计算(应用于每一行)。broadcast:一个布尔值,如果为True,则结果为DataFrame(不足的部分通过广播来填充)raw:一个布尔值。如果为False,则转换每一行/每一列为一个Series,然后传给func作为参数。如果True,则func接受到的是ndarray,而不是Seriesreduce:一个布尔值。用于判断当DataFrame为空时,应该返回一个Series还是返回一个DataFrame。如果为True,则结果为Series;如果为False,则结果为DataFrame。args:传递给func的额外的位置参数(第一个位置参数始终为Series/ndarray)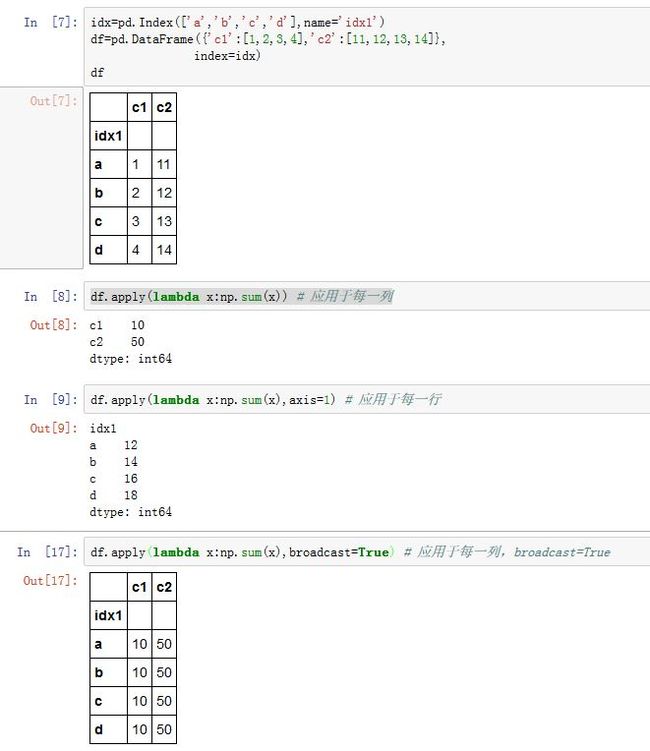
-
有时,你希望将函数应用到
DataFrame中的每个元素,则可以使用.applymap(func)方法。之所以不叫map,是因为Series已经有个.map方法。
-
Series的.apply()方法应用到Series的每个元素上:.apply(func, convert_dtype=True, args=(), **kwds)func:一个可调用对象,它会应用于每个元素convert_dtype:一个布尔值。如果为True,则pandas会自动匹配func结果的最佳dtype;如果为False,则dtype=objectargs:传递给func的额外的位置参数。kwds:传递给func的额外的关键字参数。
返回结果可能是
Series,也可能是DataFrame(比如,func返回一个Series)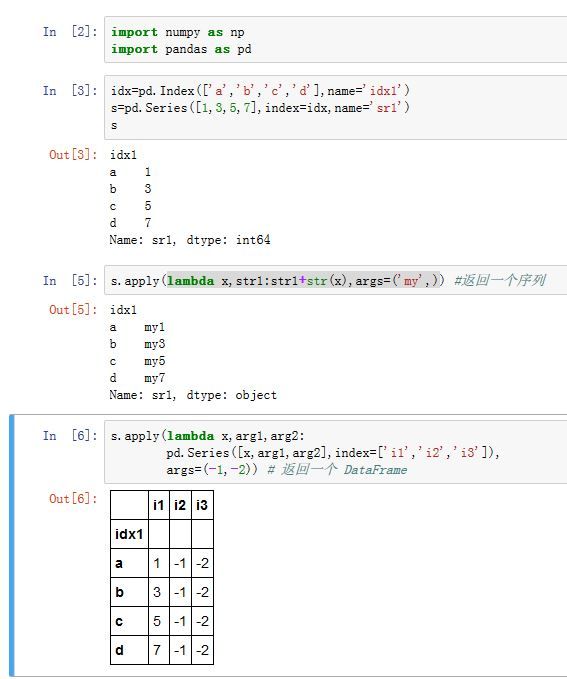
-
Series的.map(arg,na_action=None)方法会应用到Series的每个元素上:arg:一个函数、字典或者Series。如果为字典或者Series,则它是一种映射关系,键/index label就是自变量,值就是返回值。na_action:如果为ignore,则忽略NaN
返回相同
index的一个Series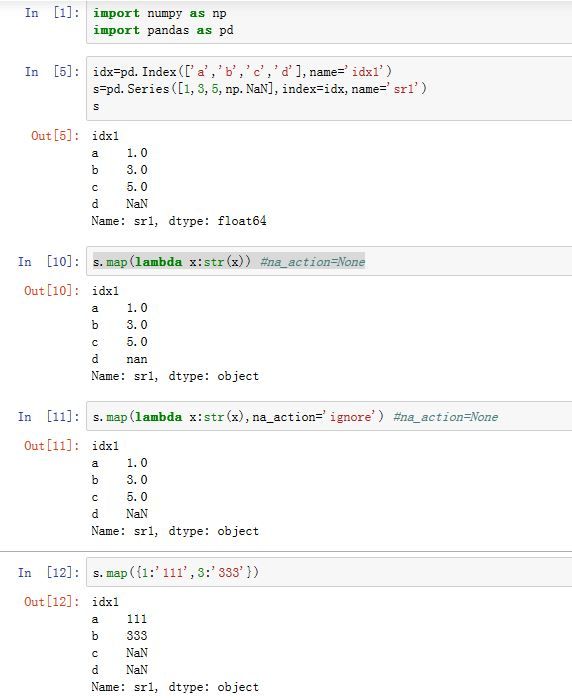
3. 缺失数据
-
pands对象上的所有描述统计都排除了缺失数据。
-
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False):根据各label的值中是否存在缺失数据来对轴label进行过滤。axis:指定沿着哪个轴进行过滤。如果为0/'index',则沿着0轴;如果为1/'columns',则沿着1轴。你也可以同时提供两个轴(以列表或者元组的形式)how:指定过滤方式。如果为'any',则如果该label对应的数据中只要有任何NaN,则抛弃该label;如果为'all',则如果该label对应的数据中必须全部为NaN才抛弃该label。thresh:一个整数,要求该label必须有thresh个非NaN才保留下来。它比how的优先级较高。subset:一个label的array-like。比如axis=0,则subset为轴 1 上的标签,它指定你考虑哪些列的子集上的NaNinplace:一个布尔值。如果为True,则原地修改。否则返回一个新创建的DataFrame
对于
Series,其签名为:Series.dropna(axis=0, inplace=False, **kwargs)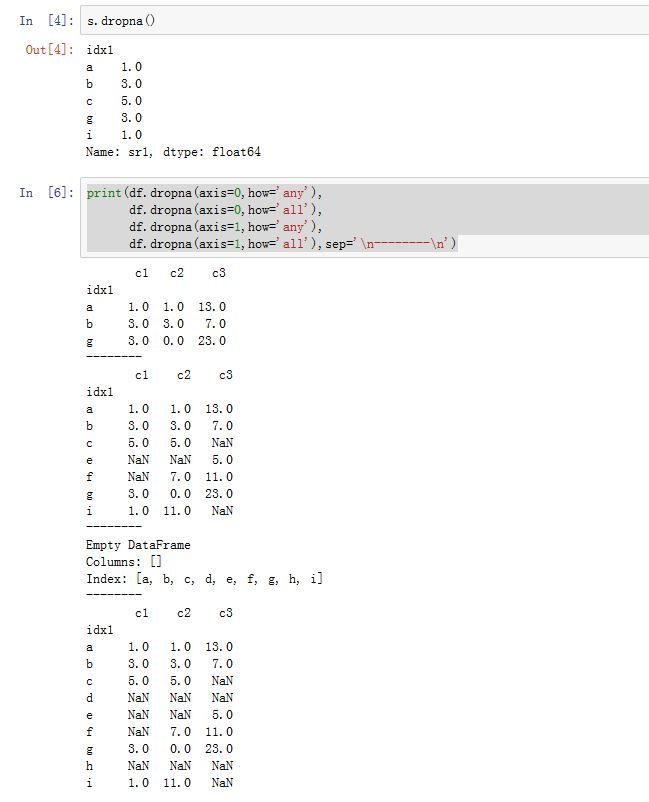

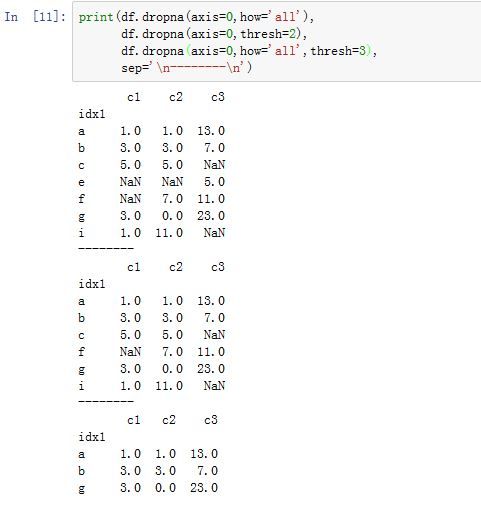
-
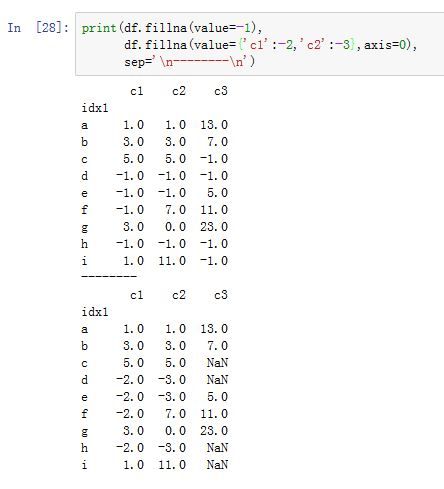
DataFrame/Series.fillna(value=None, method=None, axis=None, inplace=False, limit=None,downcast=None, **kwargs):用指定值或者插值方法来填充缺失数据。-
value:一个标量、字典、Series或者DataFrame。注意:value与method只能指定其中之一,不能同时提供。- 如果为标量,则它指定了填充
NaN的数据。 - 如果为
Series/dict,则它指定了填充每个index的数据 - 如果为
DataFrame,则它指定了填充每个DataFrame单元的数据
- 如果为标量,则它指定了填充
-
method:指定填充方式。可以为None,也可以为:'backfill'/'bfill':使用下一个可用的有效值来填充(后向填充)'ffill'/'pad':使用前一个可用的有效值来填充(前向填充)
-
axis:指定沿着哪个轴进行填充。如果为0/'index',则沿着0轴;如果为1/'columns',则沿着1轴 -
inplace:一个布尔值。如果为True,则原地修改。否则返回一个新创建的DataFrame -
limit:一个整数。如果method提供了,则当有连续的N个NaN时,只有其中的limit个NaN会被填充(注意:对于前向填充和后向填充,剩余的空缺的位置不同) -
downcast:一个字典,用于类型转换。字典形式为:{label->dtype},dtype可以为字符串,也可以为np.float64等。


-
-
DataFrame/Series.isnull():返回一个同样尺寸的布尔类型的对象,来指示每个值是否是nullDataFrame/Series.notnull():返回一个同样尺寸的布尔类型的对象,来指示每个值是否是not null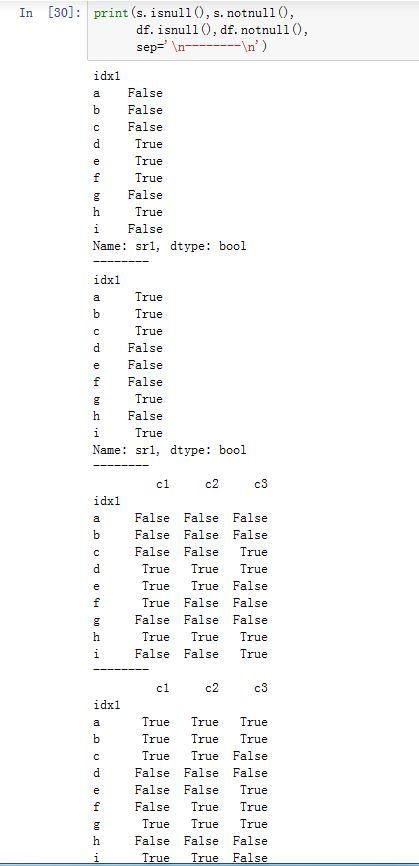
-
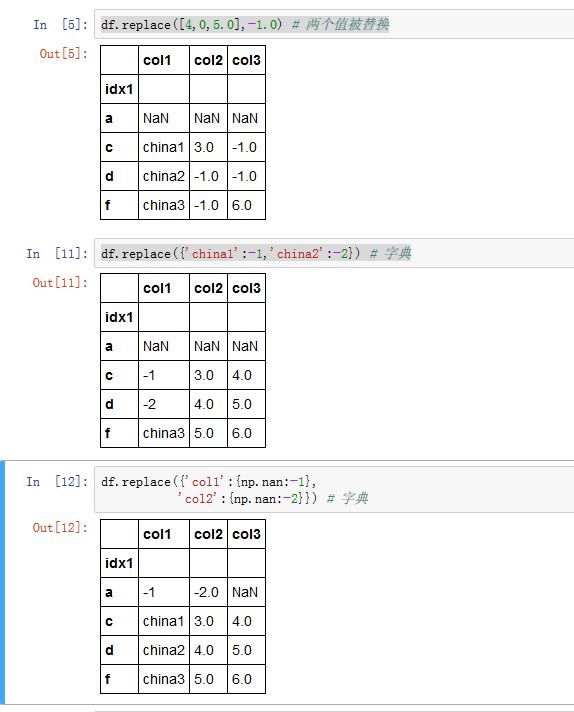
fillna()方法可以看作是值替换的一种特殊情况。更通用的是值替换replace()方法。Series/DataFrame.replace(to_replace=None, value=None, inplace=False, limit=None,
regex=False, method='pad', axis=None)
-
to_replace:一个字符串、正则表达式、列表、字典、Series、数值、None。指示了需要被替换的那些值-
字符串:则只有严格等于该字符串的那些值才被替换
-
正则表达式:只有匹配该正则表达式的那些值才被替换(
regex=True) -
列表:
- 如果
to_place和value都是列表,则它们必须长度严格相等 - 如果
regex=True,则列表中所有字符串都是正则表达式。
- 如果
-
字典:字典的键对应了被替换的值,字典的值给出了替换值。如果是嵌套字典,则最外层的键给出了
column名 -
None:此时regex必须是个字符串,该字符串可以表示正则表达式、列表、字典、ndarray等。如果value也是None,则to_replace必须是个嵌套字典。
-
-
value:一个字符串、正则表达式、列表、字典、Series、数值、None。给出了替换值。如果是个字典,则键指出了将填充哪些列(不在其中的那些列将不被填充) -
inplace:一个布尔值。如果为True,则原地修改。否则创建新对象。 -
limit:一个整数,指定了连续填充的最大跨度。 -
regex:一个布尔值,或者与to_replace类型相同。- 如果为
True,则to_replace必须是个字符串。 - 如果是个字符串,则
to_replace必须为None,因为它会被视作过滤器
- 如果为
-
method:指定填充类型。可以为'pad'/'ffill'/'bfill'。当to_replace是个列表时该参数有效。

-
-
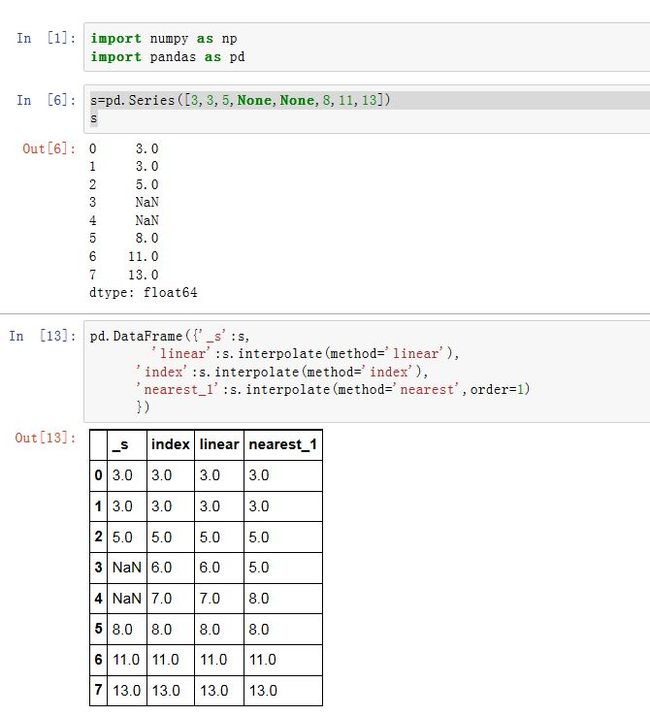
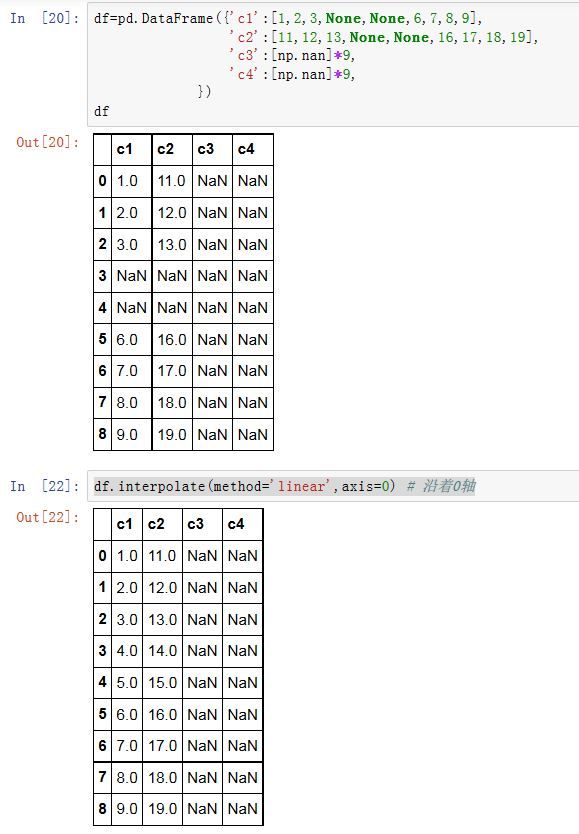
interpolate是通过前后数据插值来填充NaN。Series/DataFrame.interpolate(method='linear', axis=0, limit=None, inplace=False,
limit_direction='forward', downcast=None, **kwargs)
-
method:一个字符串,指定插值的方法。'linear':线性插值。只有它支持MultiIndex'index'/'values':使用索引标签的整数下标来辅助插值'nearest', 'zero', 'slinear', 'quadratic', 'cubic',
'barycentric', 'polynomial'使用scipy.interpolate.interp1d。对于'polynomial'/'spline',你需要传入一个order(一个整数)'krogh', 'piecewise_polynomial', 'spline', 'pchip','akima'也使用了scipy的插值算法。它们使用索引标签的整数下标来辅助插值。'time': interpolation works on daily and higher resolution data to interpolate given length of interval
-
axis:指定插值的轴。如果为0/'index'则沿着0 轴;如果为1/'columns'则沿着 1 轴 -
limit:一个整数,指定插值时,如果有K个连续的NaN,则只插值其中的limit个 -
limit_direction:一个字符串。当设定了limit时,指定处理前面limit个NaN,还是后面limit个NaN。可以为'forward'/'backward'/'both' -
inplace:一个布尔值。如果为True,则原地修改。否则创建新对象。 -
downcast:指定是否自动向下执行类型转换、 -
其他参数是传递给
scipy的插值函数的。

-
4. 离散化
-
连续数据常常会被离散化或者拆分成面元
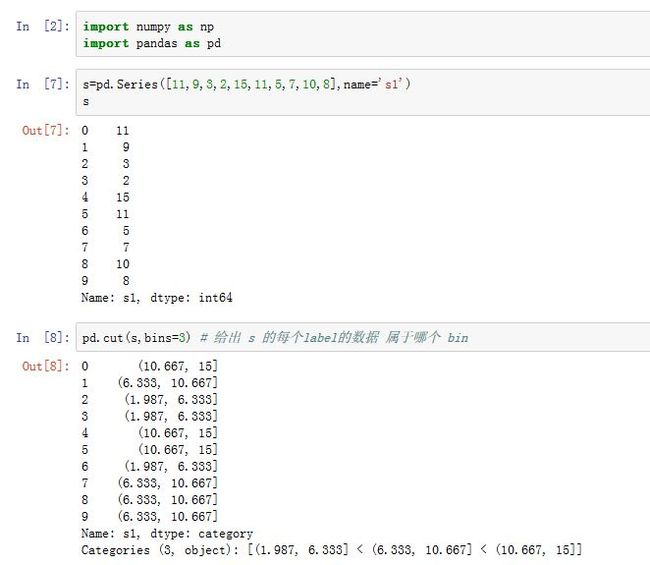
bin。可以通过pandas.cut()函数来实现:pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3,
include_lowest=False)
-
x:一维的数据。 -
bins:一个整数或者一个序列。- 整数:它指定了划分区间的数量。每个区间是等长的,且最左侧的区间的左侧比
x最小值小0.1%;最右侧的区间的右侧比x最大值大0.1%。 - 一个序列:它给出了
bins的每个划分点。
- 整数:它指定了划分区间的数量。每个区间是等长的,且最左侧的区间的左侧比
-
right:一个布尔值。如果为True,则区间是左开右闭;否则区间是左闭右开的区间。 -
labels:一个array或者None。如果为一个array,则它指定了结果bins的label(要求长度与bins数量相同)。如果为None,则使用区间来表示。 -
retbins:一个布尔值。如果为True,则返回bins -
precision:一个整数,给出存储和显示bin label的精度 -
include_lowest:一个布尔值。如果为True,则最左侧bin的左侧是闭区间
返回的是一个
Categorical对象或者Series对象。该函数类似于numpy.histogram()函数。 -
-
另外一个划分的函数是:
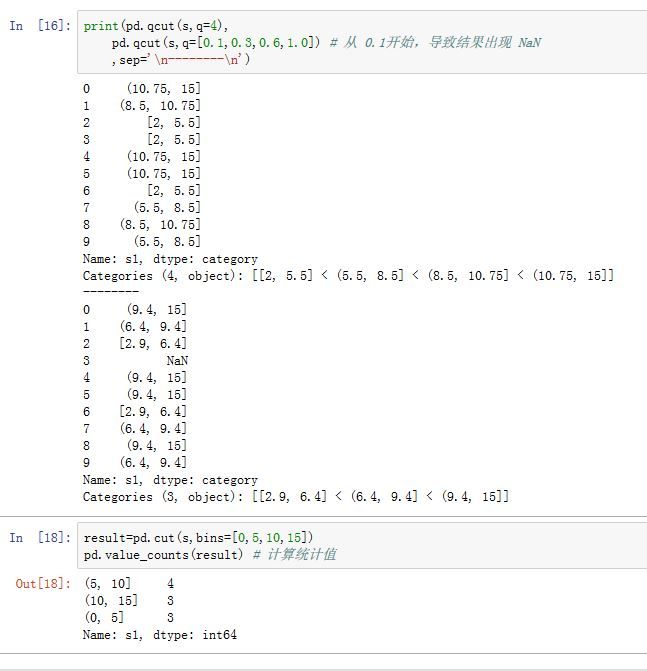
pandas.qcut(x, q, labels=None, retbins=False, precision=3)
-
q:一个整数或者序列。- 整数:它指定了划分区间的数量。
- 一个序列:它给出了百分比划分点。比如
[0,0.25,0.5,0.75,0.1]。0.25代表25%划分点。如果数据不在任何区间内,则标记为NaN。
-
其他参数与
cut相同。(qcut没有bins参数)

-
七、 字符串操作
-
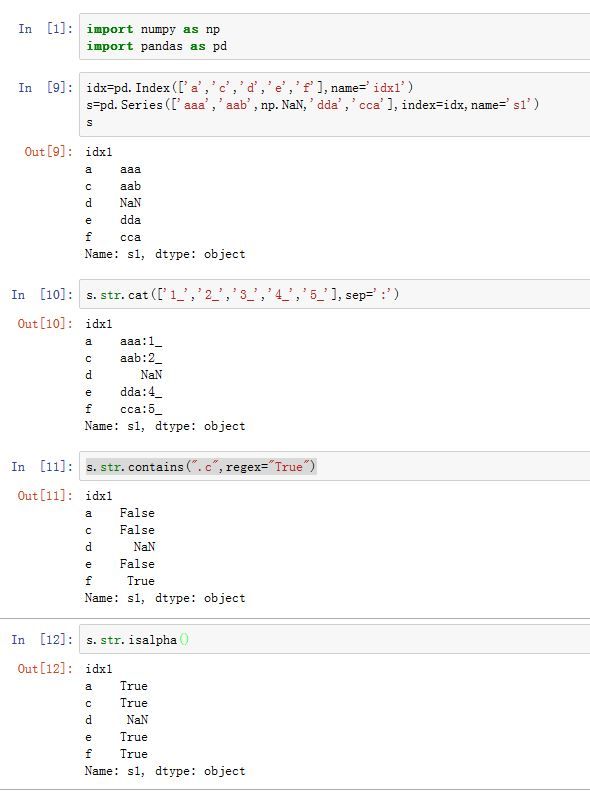
通过
Series.map()方法,所有字符串和正则表达式方法都能应用于各个值。但是如果存在NaN就会报错。为了解决这个问题,pandas提供了一些能够跳过NaN值的字符串操作方法。 -
Series.str能够将Series的值当作字符串处理,并且你可以通过Series.str.func来应用某些函数。其中func可以为:Series.str.capitalize()Series.str.cat([others, sep, na_rep])Series.str.center(width[, fillchar])Series.str.contains(pat[, case=True, flags=0, na=nan, regex=True])Series.str.count(pat[, flags])Series.str.decode(encoding[, errors])Series.str.encode(encoding[, errors])Series.str.endswith(pat[, na])Series.str.extract(pat[, flags, expand])Series.str.extractall(pat[, flags])Series.str.find(sub[, start, end])Series.str.findall(pat[, flags])Series.str.get(i)Series.str.index(sub[, start, end])Series.str.join(sep)Series.str.len()Series.str.ljust(width[, fillchar])Series.str.lower()Series.str.lstrip([to_strip])Series.str.match(pat[, case=True, flags=0, na=nan, as_indexer=False])Series.str.normalize(form)Series.str.pad(width[, side, fillchar])Series.str.partition([pat, expand])Series.str.repeat(repeats)Series.str.replace(pat, repl[, n, case, flags])Series.str.rfind(sub[, start, end])Series.str.rindex(sub[, start, end])Series.str.rjust(width[, fillchar])Series.str.rpartition([pat, expand])Series.str.rstrip([to_strip])Series.str.slice([start, stop, step])Series.str.slice_replace([start, stop, repl])Series.str.split([pat, n, expand])Series.str.rsplit([pat, n, expand])Series.str.startswith(pat[, na])Series.str.strip([to_strip])Series.str.swapcase()Series.str.title()Series.str.translate(table[, deletechars])Series.str.upper()Series.str.wrap(width, **kwargs)Series.str.zfill(width)Series.str.isalnum()Series.str.isalpha()Series.str.isdigit()Series.str.isspace()Series.str.islower()Series.str.isupper()Series.str.istitle()Series.str.isnumeric()Series.str.isdecimal()Series.str.get_dummies([sep])
-
你也可以通过
Series.str[:3]这种索引操作来进行子串截取。或者使用Series.str.get()方法进行截取。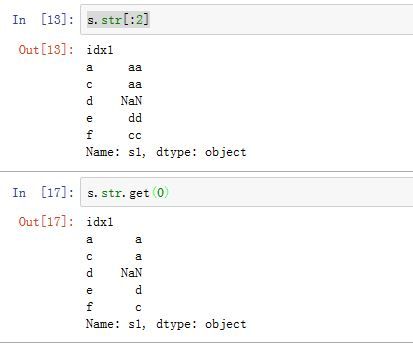
八、 聚合与分组
1. 分组
-
分组运算的过程为:拆分-应用-合并
- 拆分阶段:
Series/DataFrame等数据根据你提供的一个或者多个键,被拆分为多组 - 应用阶段:根据你提供的一个函数应用到这些分组上
- 合并阶段:将函数的执行结果合并到最终结果中
- 拆分阶段:
-
分组中有两种数据:源数据(被分组的对象),分组数据(用于划分源数据的)。
- 源数据每一行(axis=0) 对应于分组数据中的一个元素。分组数据中每一个唯一值对应于一个分组。
- 当分组数据也在源数据中时,可以直接通过指定列名来指定分组数据(值相同的为同一组)。
-
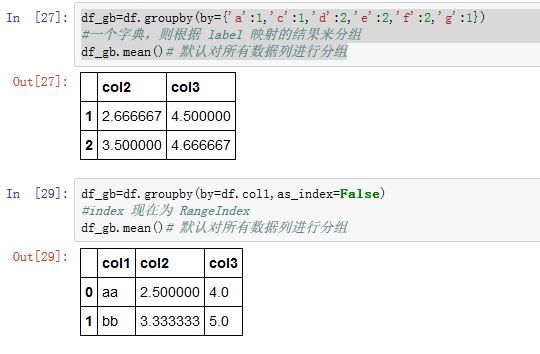
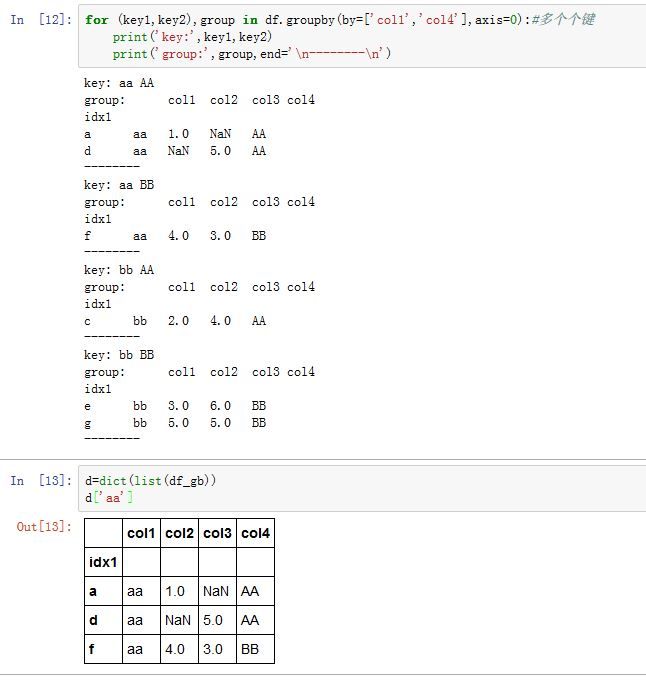
.groupby()方法是分组方法:Series/DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True,
group_keys=True, squeeze=False, **kwargs)
-
by:一个mapping function、list of function、一个字典、一个序列、一个元组、一个list of column name。它指定了分组数据。-
如果传入了函数,则在每个
index value上调用函数来产生分组数据 -
如果是
Series或者字典,则根据每个index value在字典/Series中的值来产生分组数据 -
如果是个
column label,则使用该label抽取出来的一列数据产生分组数据 -
如果是个
column label的list,则使用一组column label抽取出来的多列数据作为分组数据。 -
如果是个序列,则它直接指定了分组数据。
-
如果是个序列的序列,则使用这些序列拼接成一个
MulitiIndex,然后根据这个MultiIndex替换掉index后,根据label value来分组。(事实上并没有替换,只是用于说明这个过程)如果
axis=1,则index label替换成column label
-
-
axis:指定沿着哪个轴分组。可以为0/'index',表示沿着 0轴。可以为1/'columns',表示沿着 1轴 -
level:一个整数、level name或者其序列。如果axis是个MultiIndex,则在指定级别上的索引来分组 -
as_index:一个布尔值。如果为True,则将group label作为输出的index。如果为False,则输出是SQL风格的分组(此时分组的key作为一列,而不是作为index)。Series中,该参数必须为True。 -
sort:一个布尔值。如果为True,则对分组的键进行排序。 -
group_keys:一个布尔值。如果为True,且调用了函数来决定分组,则添加分组键来区分不同的数据(否则你不知道每一行数据都对应于哪里) -
squeeze:一个布尔值。如果为True,则尽可能的缩减结果的类型。
该函数返回一个
GroupBy对象。

-
-
我们可以使用
dtype来分组,此时by=df.dtypes,axis=1: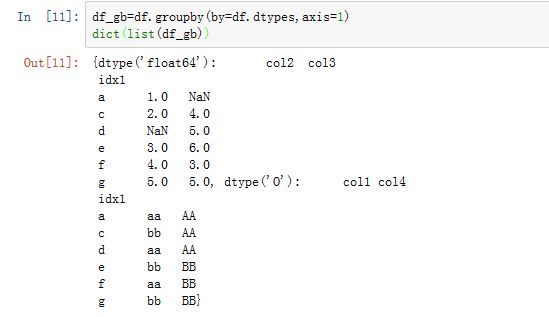
-
对于由
DataFrame产生的GroupBy对象,我们可以用一个或者一组列名对其索引。它其实一个语法糖。-
如果索引是一个列名,则
df.groupby('key1')['data1']等价于df['data1'].groupby(df['key1']) -
如果索引是一个元组和序列,则
df.groupby('key1')[['data1','data2']]并不等价于df[['data1','data2']].groupby(df['key1']),而是等同于df.groupby(df['key1'])- 之所以用
[['data1','data2']],是因为df[['data1','data2']]与df['data1','data2']语义不同。后者表示某个label是个元组,该元组的值为'data1','data2'。
- 之所以用
-
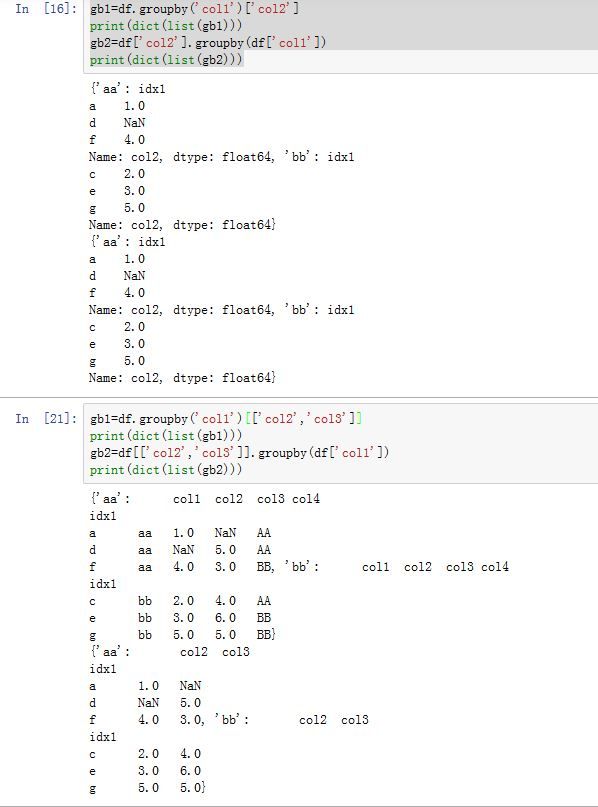
2. GroupBy对象
-
GroupBy对象是一个迭代器对象。迭代结果产生一组二元元组(由分组名和数据块组成)。- 如果有多重键,则元组的第一个元素将是由键组成的元组。
dict(list(GroupBy_obj))将生产一个字典,方便引用
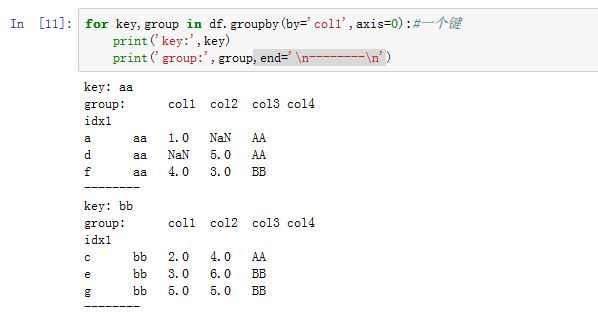
-
GroupBy.groups属性返回一个字典:{group name->group labels}GroupBy.indices属性返回一个字典:{group name->group indices}
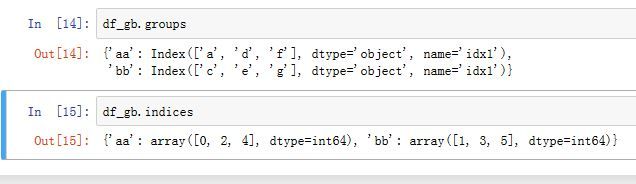
-
GroupBy的统计函数有(排除了NaN):GroupBy.count():计算各分组的非NaN的数量GroupBy.cumcount([ascending]):计算累积分组数量GroupBy.first():计算每个分组的第一个非NaN值GroupBy.head([n]):返回每个分组的前n个值GroupBy.last():计算每个分组的最后一个非NaN值GroupBy.max():计算每个分组的最大值GroupBy.mean(*args, **kwargs):计算每个分组的均值GroupBy.median():计算每个分组的中位数GroupBy.min():计算每个分组的最小值GroupBy.nth(n[, dropna]):计算每个分组第n行数据。 如果n是个整数列表,则也返回一个列表。GroupBy.ohlc():计算每个分组的开始、最高、最低、结束值GroupBy.prod():计算每个分组的乘GroupBy.size():计算每个分组的大小(包含了NaN)GroupBy.sem([ddof]):计算每个分组的sem(与均值的绝对误差之和)GroupBy.std([ddof]):计算每个分组的标准差GroupBy.sum():计算每个分组的和GroupBy.var([ddof]):计算每个分组的方差GroupBy.tail([n]):返回每个分组的尾部n个值
另外
SeriesGroupBy/DataFrameGroupBy也支持Series/DataFrame的统计类方法以及其他方法:#SeriesGroupBy - DataFrameGroupBy 都有的方法:
.agg(arg, *args, **kwargs)
.all([axis, bool_only, ...])
.any([axis, bool_only, ...])
.bfill([limit])
.corr([method, min_periods])
.count()
.cov([min_periods])
.cummax([axis, skipna])
.cummin([axis, skipna])
.cumprod([axis])
.cumsum([axis])
.describe([percentiles, ...])
.diff([periods, axis])
.ffill([limit])
.fillna([value, method, ...])
.hist(data[, column, by, ...])
.idxmax([axis, skipna])
.idxmin([axis, skipna])
.mad([axis, skipna, level])
.pct_change([periods, ...])
.plot
.quantile([q, axis, ...])
.rank([axis, method, ...])
.resample(rule, *args, **kwargs)
.shift([periods, freq, axis])
.size()
.skew([axis, skipna, level, ...])
.take(indices[, axis, ...])
.tshift([periods, freq, axis])
#SeriesGroupBy独有的方法
SeriesGroupBy.nlargest(*args, **kwargs)
SeriesGroupBy.nsmallest(*args, **kwargs)
SeriesGroupBy.nunique([dropna])
SeriesGroupBy.unique()
SeriesGroupBy.value_counts([normalize, ...])
#DataFrameGroupBy独有的方法
DataFrameGroupBy.corrwith(other[, axis, drop])
DataFrameGroupBy.boxplot(grouped[, ...])


-
如果你希望使用自己的聚合函数,只需要将其传入
.aggregate(func, *args, **kwargs)或者.agg()方法即可。其中func接受一维数组,返回一个标量值。- 注意:自定义聚合函数会慢得多。这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)
- 你可以将前面介绍的
GroupBy的统计函数名以字符串的形式传入。 - 如果你传入了一组函数或者函数名,则得到的结果中,相应的列就用对应的函数名命名。如果你希望提供一个自己的名字,则使用
(name,function)元组的序列。其中name用作结果列的列名。 - 如果你希望对不同的列采用不同的聚合函数,则向
agg()传入一个字典。字典的键就是列名,值就是你希望对该列采用的函数。

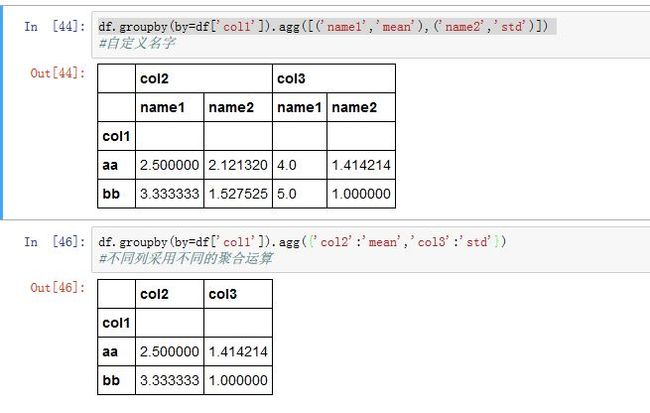
-
.get_group(key)可以获取分组键对应的数据。key:不同的分组就是依靠它来区分的
-
GroupBy的下标操作将获得一个只包含源数据中指定列的新GroupBy对象 -
GroupBy类定义了__getattr__()方法,当获取GroupBy中未定义的属性时:- 如果属性名是源数据对象的某列的名称则,相当于
GroupBy[name],即获取针对该列的GroupBy对象 - 如果属性名是源数据对象的方法,则相当于通过
.apply(name)对每个分组调用该方法。
- 如果属性名是源数据对象的某列的名称则,相当于
3. 分组级运算
-
agg/aggregate只是分组级运算其中的一种。它接受一维数组,返回一个标量值。 -
transform是另一个分组级运算。它也接受一维数组。只能返回两种结果:要么是一个标量值(该标量值将被广播),或者一个相同大小的结果数组。- 你无法通过字典来对不同的列进行不同的
transform
GroupBy.transform(func, *args, **kwargs)
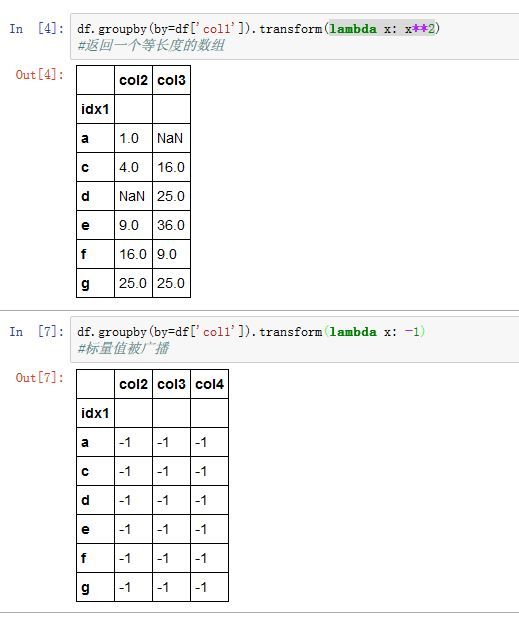
- 你无法通过字典来对不同的列进行不同的
-
apply是另一个分组级运算。它是最一般化的分组级运算。它将待处理的对象拆分成多个片段,然后对各个片段调用传入的函数,最后尝试将各个片段组合到一起。GroupBy.apply(func, *args, **kwargs)
func:运算函数。其第一个位置参数为待处理对象。其返回值是一个标量值或者pandas对象。args/kwargs是传递给func的额外的位置参数与关键字参数。
对于
DataFrame的.groupby时,传递给func的第一个参数是DataFrame;对于Series的.groupby,传递给func的第一个参数是Series。
-
pd.cut()/qcut()函数返回的是Categorical对象。我们可以用它作为.groupby()的by参数的值。这样可以实现桶分析。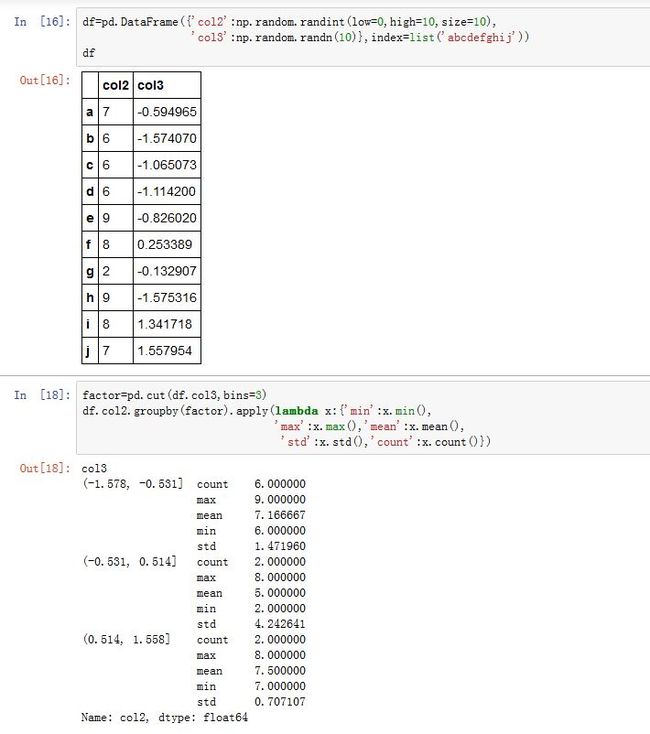
4. 透视表和交叉表
-
透视表
pivot table是一种数据汇总工具。它根据一个或者多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个单元格中。- 你可以通过
.groupby功能以及索引的变换来手工实现这种功能
- 你可以通过
-
DataFrame.pivot_table()方法,以及pandas.pivot_table()函数都可以实现这种功能pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean',
fill_value=None, margins=False, dropna=True, margins_name='All')
data:一个DataFrame对象values:指定哪些列将被聚合。默认聚合所有的数值列。index:一个index label、一个Grouper、一个数组,或者前面这些类型的一个列表。它指定关于分组的列名或者其他分组键,出现在结果透视表的行columns:一个column label、一个Grouper、一个数组,或者前面这些类型的一个列表。它指定关于分组的列名或者其他分组键,出现在结果透视表的列aggfunc:一个函数或者函数的列表。默认为numpy.mean。它作为聚合函数。如果为函数的列表,则结果中会出现多级索引,函数名就是最外层的索引名。fill_value:一个标量,用于替换NaNmargins:一个布尔值。如果为True,则添加行/列的总计。dropna:一个布尔值。如果为True,则结果不包含这样的列:该列所有元素都是NaNmargins_name:一个字符串。当margins=True时,margin列的列名。
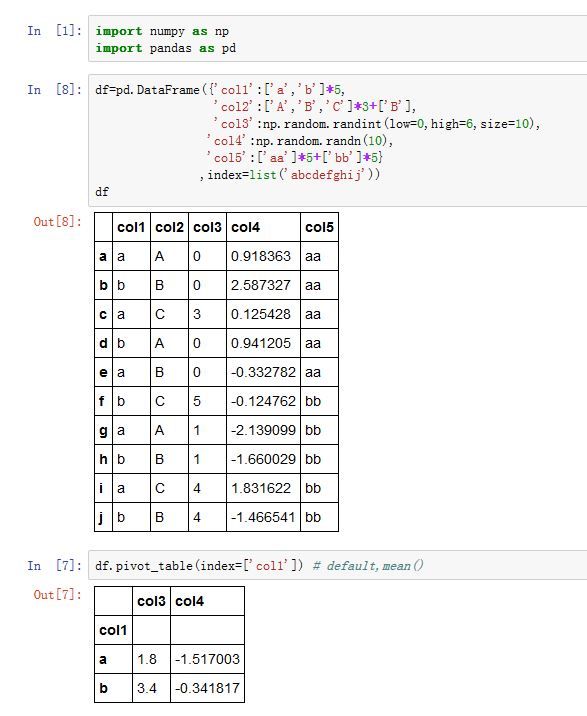
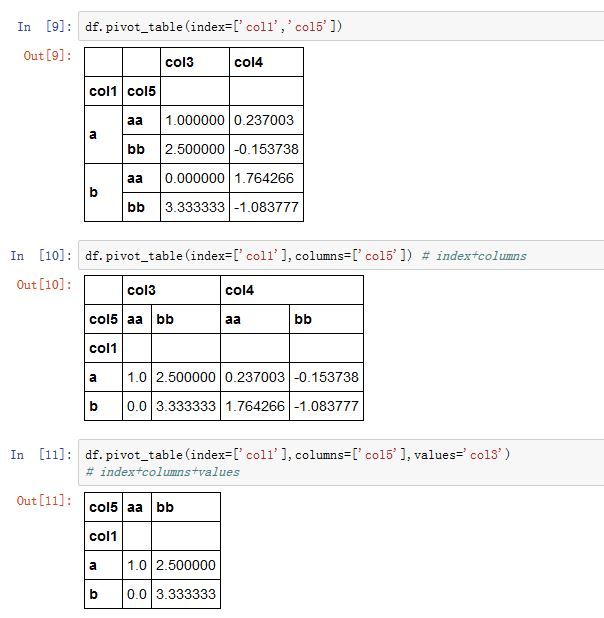

-
交叉表
cross-tabulation:crosstab是一种用于计算分组频率的特殊透视表。我们可以使用pivot_table()函数实现透视表的功能,但是直接使用更方便:pandas.crosstab(index, columns, values=None, rownames=None, colnames=None,
aggfunc=None, margins=False, dropna=True, normalize=False)
-
index:一个array-like、Series或者前两种的列表。它给出了行的计算频数的数据。 -
columns:一个array-like、Series或者前两种的列表。它给出了列的计算频数的数据。 -
values:一个array-like,该数据用于聚合。如果出现了values,则必须提供aggfunc。 -
aggfunc:一个函数对象,是聚合函数。如果出现了aggfunc,则必须提供values。 -
rownames:一个序列。如果非空,则必须和结果的row index的level数量相等 -
colnames:一个序列。如果非空,则必须和结果的column index的level数量相等 -
margins:一个布尔值。如果为True,则添加行/列的总计。 -
dropna:一个布尔值。如果为True,则结果不包含这样的列:该列所有元素都是NaN -
normalize:一个布尔值、字符串('all'/'index'/'columns')、或者整数0/1。它指定是否进行归一化处理(归一化为频率),否则就是频数。- 如果
'all'/True,则对所有数据进行归一化 - 如果为
'index':则对每一行归一化 - 如果为
'columns':则对每一列归一化 - 如果
margins为True,则对margins也归一化。
- 如果
values的作用是这样的:首先根据index-columns建立坐标。行坐标来自index,列坐标来自columns。在index-columns-values中,同一个坐标下的values组成Series。这个Series被aggfunc进行聚合,aggfunc接受一个Series,返回一个标量。此时就不再是对坐标点进行计数了,而是对values进行聚合。


-
九、时间序列
Pandas提供了表示时间点、时间段、时间间隔等三种与时间有关的类型,以及元素为这些类型的索引对象。pandas还提供了许多与时间序列相关的函数。
1. Python 中的时间
Python中,关于时间、日期处理的库有三个:time、datetime、Calendar。其中:datetime又有datetime.date/datetime.time/datetime.datetime三个类
1.1 时区
- 所有的时间都有一个时区。同样一个时间戳,根据不同的时区,它可以转换成不同的时间。
pytz模块的common_timezones可以获取常用的表示时区的字符串。你可以通过pytz.timezone('timezone_str')来创建时区对象。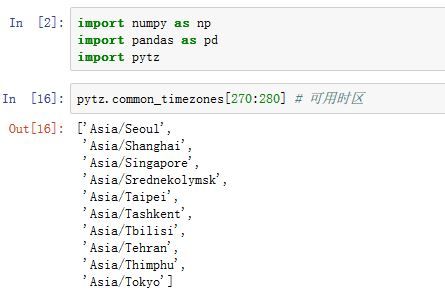
1.2 time 模块
-
time模块中,时间有三种表现形式:Unix时间戳。指的是从1970年以来的秒数- 本地时间的
struct_time形式:一个命名元组,第一位为年、第二位为月.... UTC时间的struct_time的形式:类似于上面的,只是为UTC时间。区别在于:前者是本地时间local time,后者是UTC时间
-
查看当前时间的三种表现形式:
Unix时间戳:time.time()local struct_time:time.localtime()utc struct_time:time.gmtime()

-
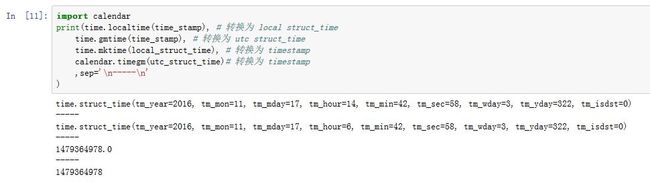
三种格式之间的转换:
timestamp--->local time:time.localtime(time_stamp)timestamp--->utc time:time.gmtime(time_stamp)local time--->timestamp:time.mktime(local_time)utc time---> timestamp:calendar.timegm(utc_time)
-
三种格式的时间转换为字符串:
timestamp:time.ctime(time_stamp)local struct_time time/utc struct_time time:time.asctime(struct_time)- 对于
local struct_time time/utc struct_time time:你也可以使用time.strftime(format_str,struct_time)来自定义格式化串。其中format_str为格式化串。
字符串转换为
struct_time:time.strptime(time_str,format_str)。其中format_str为格式化串。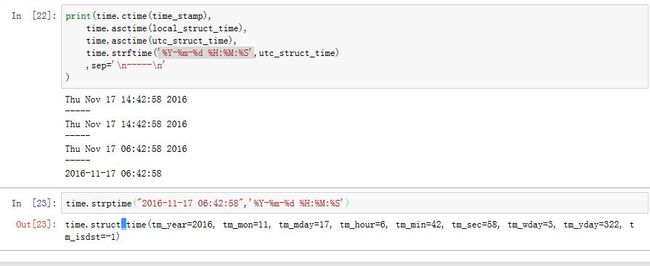
-
查看当前时区:
time.timezone。它返回的是距离UTC时间的距离(单位为秒)(>0,在美洲;<=0,在大多数欧洲,亚洲,非洲)。你无法通过修改它的值来修改时区。time模块使用的是系统的时区。
1.3 datetime 模块
-
datetime模块中主要包含四个类:datetime.time:时间类。只包含时、分、秒、微秒等时间信息datetime.date:日期类。值包含年月日星期等日期信息datetime.datetime:日期时间类。包含上述两者的全部信息datetime.timedelta:日期时间间隔类,用来表示两个datetime之间的差值。
-
datetime.time的构造函数为:time([hour[, minute[, second[, microsecond[, tzinfo]]]]])
其中
tzinfo就是时区对象。0<=hour<24,0<=minute<60,0<=second<60,0<=microsecond<1000000,否则抛出异常。tzinfo默认为None
属性有:
hour/minute/second/microsecond/tzinfo
方法有:
time.replace([hour[, minute[, second[, microsecond[, tzinfo]]]]]):替换对应的值,返回一个新的对象time.isoformat():返回一个ISO 8601格式的字符串。time.strftime(format):格式化datetime.time对象time.tzname():如果时区为为None,则返回None。否则返回时区名称
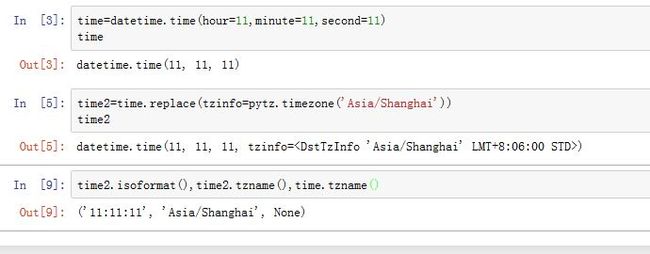
-
datetime.date的构造函数为:datetime.date(year, month, day)
month取值为[1,12];day取值为[1,num],num取决于指定的年和月有多少天
类方法有:
date.today()/date.fromtimestamp(timestamp)属性有:
year/month/day方法有:
- 运算:
date1-date2、date1+timedelta、date1-timedelta、date1 date.replace(year,month,day):替换掉对应值,返回新对象date.timetuple():返回一个time.struct_time类型的元组date.weekday():返回代表星期几的数字。0为周日date.isoweekday():返回代表星期几的数字。7为周日date.isocalendar():返回一个元组(ISO year,IOS week num,ISO weekday)date.isoformat():返回一个ISO 8601格式的字符串。date.ctime():等价于time.ctime(time.mktime(d.timetuple()))date.strftime(format):格式化datetime.date对象

-
datetime.datetime的构造函数为:datetime.datetime(year, month, day, hour=0, minute=0,
second=0, microsecond=0, tzinfo=None)
类方法有:
datetime.today():返回当前的时间日期datetime.now(tz=None):返回指定时区当前的时间日期。如果tz=None,则等价于datetime.today()datetime.utcnow():返回当前的UTC时间日期datetime.fromtimestamp(timestamp, tz=None):根据时间戳,创建指定时区下的时间日期。datetime.utcfromtimestamp(timestamp):根据时间戳,创建UTC下的时间日期。datetime.combine(date, time):从date和time对象中创建datetimedatetime.strptime(date_string, format):从字符串中创建datetime
属性有:
year/month/day/hour/minute/second/microsecond/tzinfo方法有:
- 运算:
datetime1-datetime2、datetime1+timedelta、datetime1-timedelta、datetime1 datetime.date():返回一个date对象datetime.time():返回一个time对象(该time的tzinfo=None)datetime.timetz():返回一个time对象(该time的tzinfo为datetime的tzinfo)datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]]):替换掉指定值,返回新对象datetime.astimezone(tz=None):调整时区。如果tz=None,则默认采用系统时区。注意,调整前后的UTC时间是相同的。datetime.tzname():返回时区名字datetime.timetuple():返回一个time.struct_time这样的命名元组datetime.utctimetuple():返回一个time.struct_time这样的命名元组,注意它是在UTC时间下的,而不是local time下的datetime.timestamp():返回一个时间戳datetime.weekday():返回代表星期几的数字。0为周日datetime.isoweekday():返回代表星期几的数字。7为周日datetime.isocalendar():返回一个元组(ISO year,IOS week num,ISO weekday)datetime.isoformat(sep='T'):返回一个ISO 8601格式的字符串。datetime.ctime():等价于time.ctime(time.mktime(d.timetuple()))datetime.strftime(format):格式化datetime.datetime对象。
注意:不能将
tzinfo=None和tzinfo!=None的两个datetime进行运算。 -
下面是常用的格式化字符串的定义:
'%Y':4位数的年'%y':2位数的年'%m':2位数的月[01,12]'%d':2位数的日[01,31]'%H':小时(24小时制)[00,23]'%I':小时(12小时制)[01,12]'%M':2位数的分[00,59]'%S':秒[00,61],61秒用于闰秒'%w':用整数表示的星期几[0,6],0 表示星期日'%U':每年的第几周[00,53]。星期天表示每周的第一天。每年的第一个星期天之前的那几天被认为是第 0 周'%W':每年的第几周[00,53]。星期一表示每周的第一天。每年的第一个星期一之前的那几天被认为是第 0 周'%z':以+HHMM或者-HHMM表示的UTC时区偏移量。如果未指定时区,则返回空字符串。'%F':以%Y-%m-%d简写的形式'%D':以%m/%d/%y简写的形式'%a':星期几的简称'%A':星期几的全称'%b':月份的简称'%B':月份的全称'%c':完整的日期和时间'%q':季度[01,04]
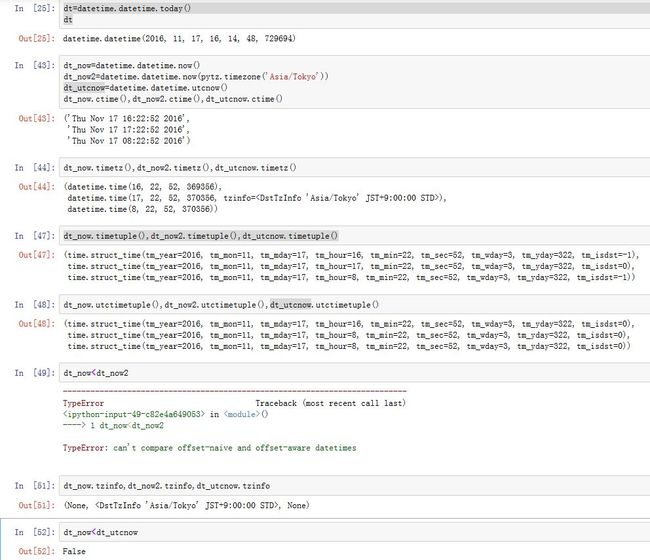
-
timedelta代表一段时间。其构造:datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0,
minutes=0, hours=0, weeks=0)
在内部,只存储秒、微秒。其他时间单位都转换为秒和微秒。
实例属性(只读):
days/seconds/microseconds
实例方法:
timedelta.total_seconds():返回总秒数。

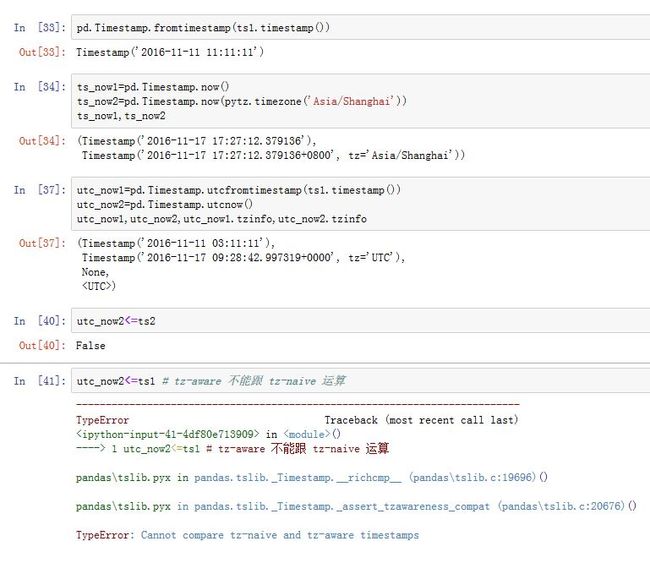
2. 时间点 Timestamp
-
时间点:
Timestamp对象从Python的datetime类继承,它表示时间轴上的一个点。pd.Timestamp(ts_input=
unit=None, year=None, month=None, day=None, hour=None, minute=None,
second=None, microsecond=None, tzinfo=None, offset=None)
参数:
ts_input:一个datetime-like/str/int/float,该值将被转换成Timestampfreq:一个字符串或者DateOffset,给出了偏移量tz:一个字符串或者pytz.timezone对象,给出了时区unit:一个字符串。当ts_input为整数或者浮点数时,给出了转换单位offset:废弃的,推荐使用freq- 其他的参数来自于
datetime.datetime。它们要么使用位置参数,要么使用关键字参数,但是不能混用

属性有:
year/month/day/hour/minute/second/microsecond/nanosecond,这些属性都为整数tzinfo:时区信息(默认为None),它是一个datetime.tzinfo对象dayofweek/dayofyear/days_in_mounth/freqstr/quarter/weekofyear/...value:保存的是UTC时间戳(自UNIX纪元1970年1月1日以来的纳秒数),该值在时区转换过程中保持不变
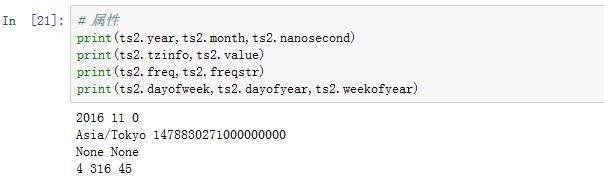
类方法有:
combine(date, time):通过datetime.date和datetime.time创建一个Timestampfromtimestamp(ts):通过时间戳创建一个Timestampnow(tz=None):创建一个指定时区的当前时间。doday(tz=None):创建一个指定时区的当前时间。utcfromtimestamp(ts):从时间戳创建一个UTC Timestamp,其tzinfo=Noneutcnow():创建一个当前的UTC Timestamp,其tzinfo=UTC
方法有:
.astimezone(tz)/.tz_convert(tz):将一个tz-aware Timestamp转换时区.isoformat(sep='T'):返回一个ISO 8601格式的字符串。.normalize():将Timestamp调整到午夜(保留tzinfo)replace(**kwds):调整对应值,返回一个新对象.to_period(self, freq=None):返回一个Period对象`.tz_localize(self, tz, ambiguous='raise', errors='raise'):将一个tz-naive Timestamp,利用tz转换为一个tz-aware Timestamp.to_pydatetime(...):转换为python datetime对象.to_datetime64(...):转换为numpy.datetime64对象- 从
datetime.date/datetime.datetime继承而来的方法
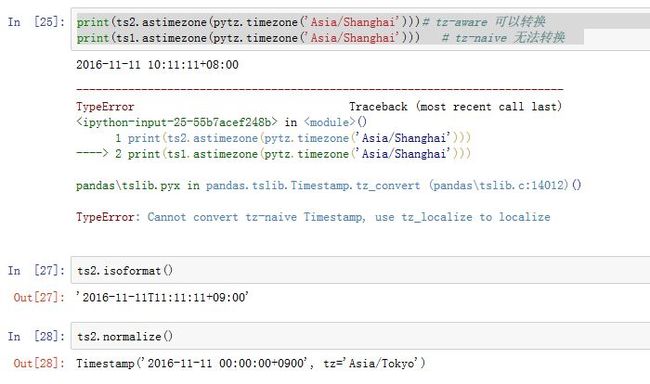

默认情况下,
pands中的Timestamp是tz-naive,即tz字段为None。Timestamp提供了方便的时区转换功能。如果tz非空,则是tz-aware Timestamp。不同时区的时间可以比较,但是naive Timestamp和localized Timestamp无法比较。Timestamp的减法,要求两个Timestamp要么都是同一个时区下,要么都是tz-naive的。 -
DateOffset对象:是一个表示日期偏移对象。Timestamp加一个日期偏移,结果还是一个Timestamp对象。其声明为:pd.DateOffset(n=1, normalize=False, **kwds)
通常我们使用的是其子类(它们位于
pandas.tseries.offsets中):Day:日历日BusinessDay:工作日Hour:小时Minute:分钟Second:秒Milli:毫秒Micro:微秒MonthEnd:每月最后一个日历日BusinessMonthEnd:每月最后一个工作日MonthBegin:每月第一个日历日BusinessMonthBegin:每月第一个工作日Week:每周几
Day(2):表示两个工作日。DateOffset对象可以加在datetime/Timestamp对象上。如果是MonthEnd这种加上Timestamp,则第一次增量会将原日期向前滚动到符合频率规则的下一个日期。- 你可以通过
DateOffset.rollforward(time_stamp)、DateOffset.rollback(time_stamp)来显式地将日期向前或者向后滚动
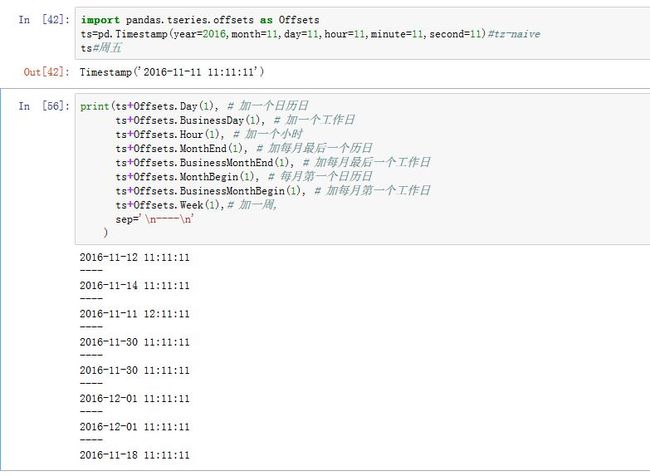
-
利用
str(dt_obj)函数或者datetime.strftime(format_str)方法,可以将datetime对象和Timestamp对象格式化为字符串。而利用datetime.strptime(dt_str,format_str)类方法,可以从字符串中创建日期。其中dt_str为日期字符串,如'2011-11-12';format_str为格式化字符串,如'%Y-%m-%d'。datetime.strptime是对已知格式进行日期解析的最佳方式。- 对于一些常见的日期格式,使用
dateutil这个第三方包中的parser.parse(dt_str),它几乎可以解析所有的日期表示形式。 pandas.to_datetime()方法可以解析多种不同的日期表示形式,将字符串转换为日期。对于标准日期格式的解析非常快。如果发现无法解析(如不是一个日期),则返回一个NaT(Not a Time),它是时间戳数据中的NA值。
-
Timedelta对象:表示时间间隔。它等价于datetime.timedelta类。pd.Timedelta(value=
参数:
value:一个Timedelta对象,或者datetime.timedelta,或者np.timedelta64、或者一个整数,或者一个字符串。指定了时间间隔unit:一个字符串,指明了当输入时整数时,其单位。可以为'D'/'h'/'m'/'s'/'ms'/'us'/'ns'days/seconds/microseconds/nanoseconds:都是数值。给出了某个时间单位下的时间间隔
方法:
to_timedelta64():返回一个numpy.timedelta64类型(按照纳秒的精度)total_seconds():返回总的时间间隔,单位秒(精度为纳秒)to_pytimedelta():返回一个datetime.timedelta对象
属性:
components:返回各成分的命名元组days/seconds/microseconds/nanoseconds:返回各个成分delta:返回总的时常(纳秒计)
一个时间间隔有天数、秒数等等属性。注意:所有的这些值与对应的单位相乘的和,才是总的时间间隔。
两个
Timestamp相减可以得到时间间隔TimedeltaDateOffset也一定程度上表示时间间隔,但是DateOffset更侧重于按照某个固定的频率的间隔,比如一天、一个月、一周等。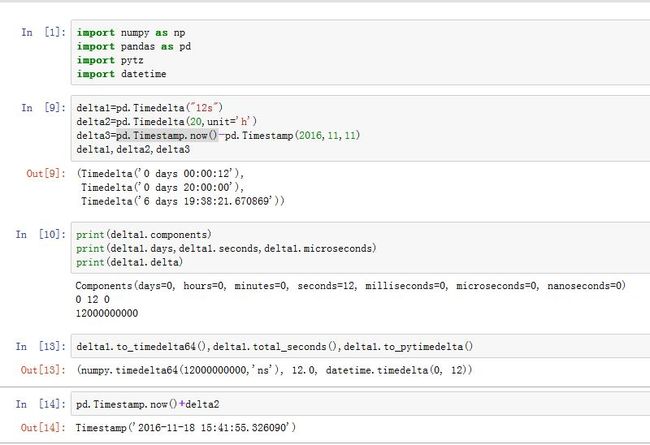
3. 时间段 Period
-
Period表示一个标准的时间段(如某年,某月)。时间段的长短由freq属性决定。pd.Period(value=None, freq=None, ordinal=None, year=None, month=None,
quarter=None, day=None, hour=None, minute=None, second=None)
参数:
value:一个Period对象或者字符串(如'4Q2016'),它表示一个时区段。默认为Nonefreq:一个字符串,表示区间长度。可选的值从下面函数获取:pandas.tseries.frequencies._period_code_map.keys()pandas.tseries.frequencies._period_alias_dictionary()- 其他的参数和前面的其他类的构造函数类似。其中
quarter表示季度。
属性:
day/dayofweek/dayofyear/hour/minute/quarter/second/year/week/weekday/weekofyear/year:对应的属性end_time:区间结束的Timestamp。start_time:区间开始的Timestampfreq
方法:
.asfreq(freq,how):转换为其他区间。其中freq为字符串。how可以为'E'/'end',表示包含区间结束;'S'/'start'表示包含区间开始。.now(freq):返回当期日期对应freq下的Periodstrftime(format):给出Period的格式化字符串表示to_timestamp(freq,how):转换为Timestamp。

-
pands中的频率是由一个基础频率和一个倍数组成。- 基础频率通常以一个字符串别名表示,如
'M'表示每月,'H'表示每小时。 - 对于每个基础频率,都有一个
DateOffset对象与之对应。如pandas.tseries.offsets中的Hour/Minute。Hour(4)表示日期偏移为 4小时。 - 倍数为基础频率之前的数字,如
'4H'。也可以组合多个频率4H30min
有些频率描述的时间点并不是均匀间隔的。如
'M'就取决于每个月的天数。下面是一些常用的基础频率'D':偏移量类型为Day,为每日历日'B':偏移量类型为BusinessDay,为每工作日'H':偏移量类型为Hour,为每小时'T'或者'min':偏移量类型为Minute,为每分钟'S':偏移量类型为Second,为每秒'L'或者'ms':偏移量类型为Milli,为每毫秒'U':偏移量类型为Micro,为每微秒'M':偏移量类型为MonthEnd,为每月最后一个日历日'BM':偏移量类型为BusinessMonthEnd,为每月最后一个工作日'MS':偏移量类型为MonthBegin,为每月第一个日历日'BMS':偏移量类型为BusinessMonthBegin,为每月第一个工作日'W-Mon'...'W-TUE:偏移量类型为Week,为指定星期几(MON/TUE/WED/THU/FRI/SAT/SUN)开始算起,每周
- 基础频率通常以一个字符串别名表示,如
-
调用
Timestamp对象的.to_period(freq)方法能将时间点转化为包含该时间点的时间段。
-
Period的.asfreq()方法可以实现时间段的频率转换。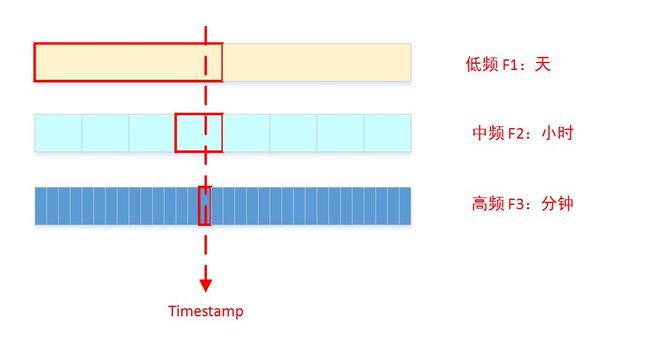
创建
Period时,我们可以传入一个Timestamp的各分量(由year/month...等提供)。创建的Period是包含该时刻,且指定频率。在使用Timestamp.to_period(freq)也是如此。给定一个频率的
Period,如果转换到更低频的Period,则非常简单:返回指定频率下的包含本Period的那个Period即可。如果想转换到更高频的Period,则由于在本Period下,对应了很多个高频的Period,则返回哪一个,由how参数指定:how=S:返回最开头的那个Periodhow=E:返回最末尾的那个Period
而
Period.to_timestamp(freq,how)方法中,我们首先进行时间段的频率转换,然后提取该频率的Period开始处的Timestamp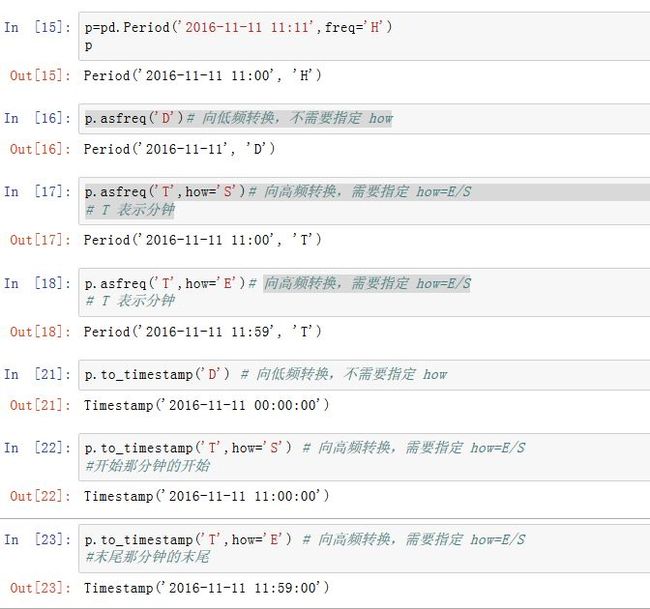
-
如果两个
Period对象有相同的频率,则它们的差就是它们之间的单位数量。
4. DatetimeIndex
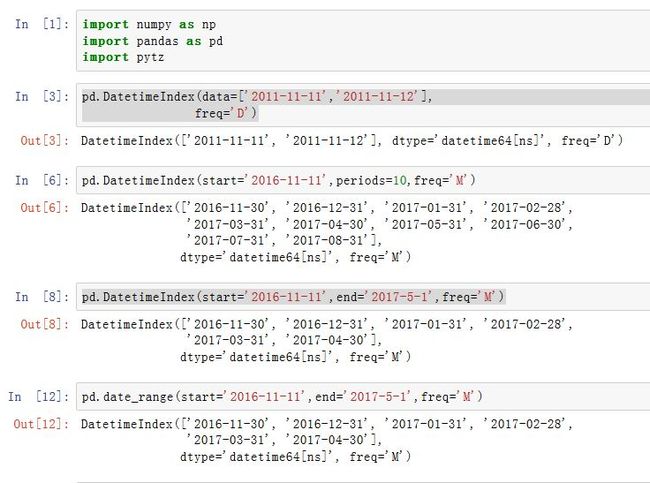
-
DatetimeIndex是一种索引,它的各个标量值是Timestamp对象,它用numpy的datetime64数据类型以纳秒形式存储时间戳。pd.DatetimeIndex(data=None, freq=None, start=None, end=None, periods=None,
copy=False, name=None, tz=None, verify_integrity=True, normalize=False,
closed=None, ambiguous='raise', dtype=None, **kwargs)
data:一个array-like对象,给出了各个时间copy:一个布尔值,如果为True则拷贝基础数据freq:一个字符串或者DateOffset对象,给出了频率start:一个datetime-like,指定了起始时间。如果data=None,则使用它来生成时间periods:一个整数(大于0),指定生成多少个时间。如果data=None,则使用它来生成时间end:一个datetime-like,指定了结束时间。如果data=None且periods=None,则使用它来生成时间closed:一个字符串或者None。用于指示区间的类型。可以为'left'(左闭右开),'right'(左开右闭),None(左闭右闭)tz: 一个字符串,指定了时区。如果非空,则返回的是localized DatetimeIndexname:指定了Index的名字
-
pandas.date_range()函数可以生成指定长度的DatetimeIndexpandas.date_range(start=None, end=None, periods=None, freq='D', tz=None,
normalize=False,name=None, closed=None, **kwargs)
各参数意义参考
DatetimeIndex的构造函数。 -
对于以
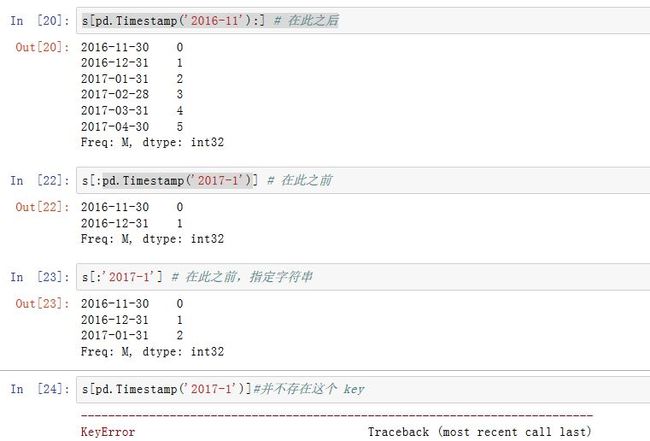
DatetimeIndex为索引的Series,我们可以通过指定Timestamp切片来截取指定时间区间的数据(也可以是对应的字符串来指定Timestamp)。注意:这里的Timestamp可以并不是DatetimeIndex的key。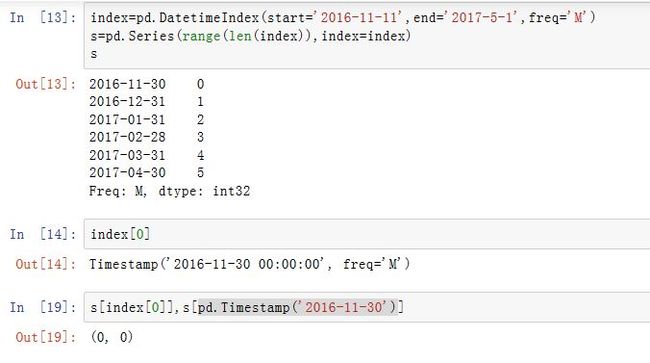
-
DatetimeIndex的方法有:(DatetimeIndex继承自Index,因此它有Index的所有方法)indexer_at_time(time, asof=False):返回指定time的位置indexer_between_time( start_time, end_time, include_start=True,include_end=True):返回指定的两个时间之间的索引的位置normalize():将时间调整到午夜to_period( freq=None):以指定freq转换到PeriodIndexto_perioddelta( freq):计算不同索引值的Timedelta,然后转换成一个TimedeldaIndexto_pydatetime/tz_convert/tz_localize:对每个时间使用Timestamp对应的方法
任何
Timestamp的属性都可以作用于DatetimeIndex。
5. PeriodIndex
-
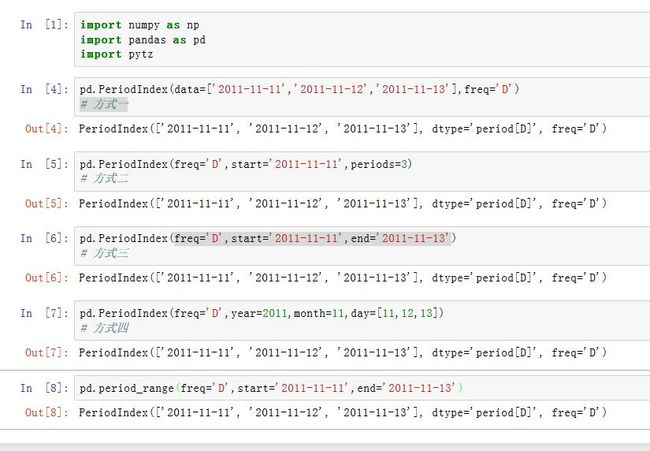
如果将一个
Period序列作为索引,则该索引就是PeriodIndex类型。其各位置的值为Period对象。pd.PeriodIndex(data=None, ordinal=None, freq=None, start=None, end=None,
periods=None, copy=False, name=None, tz=None, dtype=None, **kwargs)
data:一个array-like对象,给出了各个时间段copy:一个布尔值,如果为True则拷贝基础数据freq:一个字符串或者period对象,给出了频率start:一个period-like,指定了起始时间段。如果data=None,则使用它来生成时间段periods:一个整数(大于0),指定生成多少个时间段。如果data=None,则使用它来生成时间段end:一个period-like,指定了结束时间段。如果data=None且periods=None,则使用它来生成时间段year/month/quarter/day/hour/minute/second:一个整数、array或者Series。通过它们可以组装出一个Period序列。tz: 一个字符串,指定了时区。如果非空,则返回的是localized DatetimeIndexname:指定了Index的名字
-
pandas.period_range()函数可以生成指定长度的PeriodIndexpd.period_range(start=None, end=None, periods=None, freq='D', name=None)
参数意义参见
PeriodIndex的构造函数。 -
PeriodIndex的方法有:(PeriodIndex继承自Index,因此它有Index的所有方法)asfreq( freq=None, how='E'):转换成另一种频率的时间段to_timestamp(self, freq=None, how='start'):转成DatetimeIndextz_convert(self, tz)/tz_localize(self, tz, infer_dst=False):转成对应时区的DatetimeIndex
任何
Period的属性都可以作用于PeriodIndex。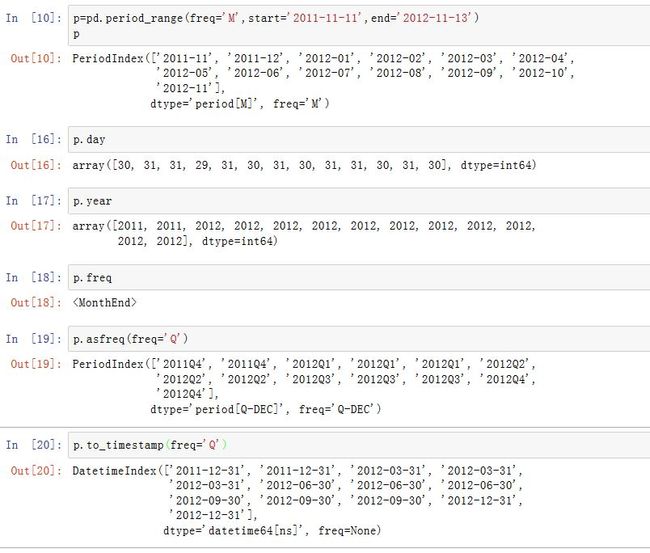
6. resample 和频率转换
-
Series/DataFrame有一个shift()方法用于执行单纯的前移或者后移操作,:Series/DataFrame.shift(periods=1, freq=None, axis=0)
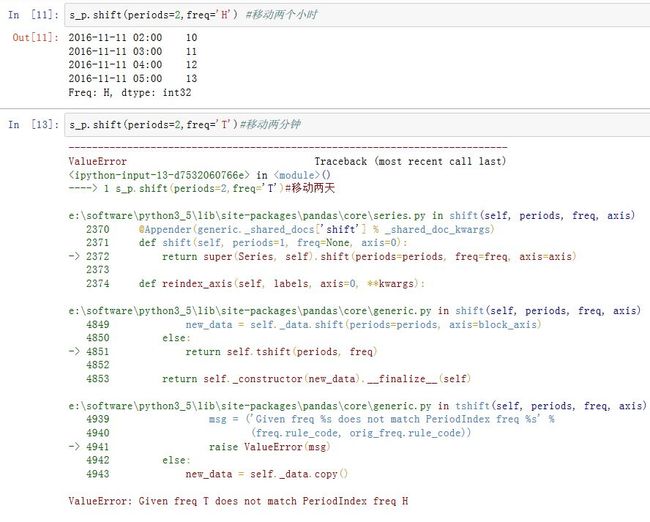
periods:一个整数(可以为负的),指定移动的数量。对于时间序列,单位由freq指定。freq:一个DateOffset/timedelta或者一个频率字符串。指定移动的单位。注意,如果为PeriodIndex,则freq必须和它匹配。axis:为0/'index'表示沿着0轴移动;为1/'columns'表示沿着1轴移动
如果为时间序列,则该方法移动并建立一个新的索引,但是
Series/DataFrame的值不变。对于非时间序列,则保持索引不变,而移动Series/DataFrame的值。本质上,时间序列和非时间序列都是
index_i-->value_i转换成index_i+n-->value_i。只是时间序列截取的都是有效值,非时间序列截取了NaN而已。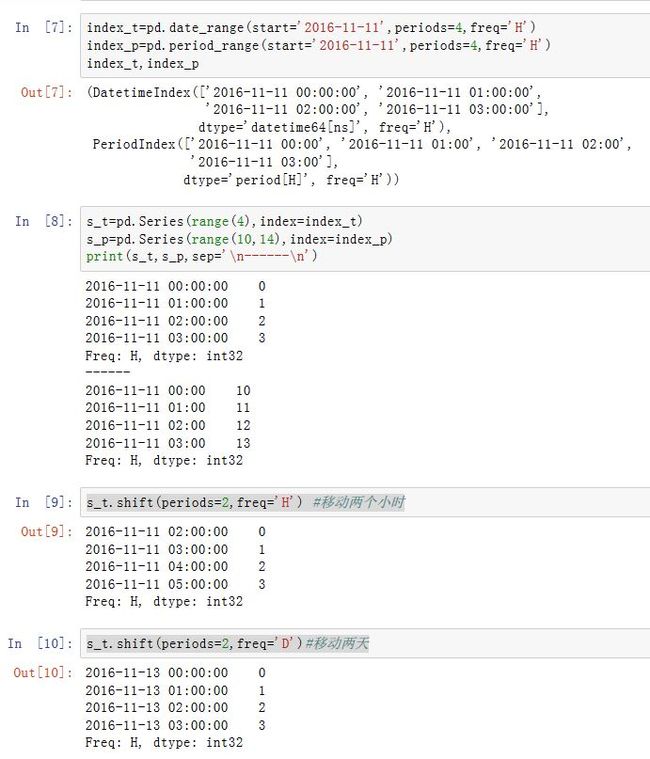

-
重采样
resampling指的是将时间序列从一个频率转换到另一个频率的处理过程。- 将高频数据转换到低频数据称作降采样。降采样时,待聚合的数据不必拥有固定的频率,期望的频率(低频的)会自动划分聚合的
bin的边界。这些bin将时间序列拆分为多个片段。这些片段都是半开放的,一个数据点只能属于一个片段,所有的片段的并集组成了整个时间帧。在对数据降采样时,只需要考虑两样: - 各个区间哪边是闭合的
- 如何标记各个聚合
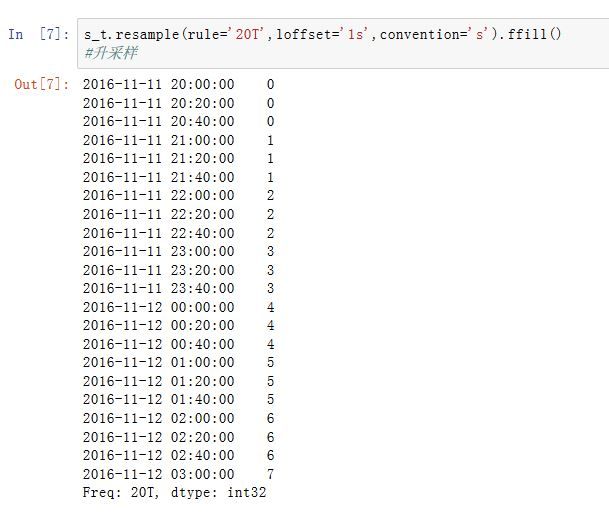
bin,用区间的开头还是结尾 - 将低频数据转换到高频数据称作升采样。将数据转换到高频时,就不需要聚合了,而是插值,默认引入缺失值。插值的填充和填充方式与
fillna/reindex的一样。 - 在对时间段
Period进行重采样时,升采样稍微麻烦点,因为你必须决定:哪个高频区间代表原区间。就像asfreq一样,convention可以设置为'end'/'start'
有些重采样并不划分到上述两者之中。比如将
W-WED(每周三)转换到W-FRI(每周五)。另外,由于Period是时间区间,所以升采样和降采样的规则就比较严格:- 降采样中,目标频率必须包含原频率。如
Day->Month,目标频率为每月,原频率为每天。 - 升采样中,原频率必须包含目标频率。如
Day->Hour,目标频率为每小时,原频率为每天。
如果不满足这些条件,则会引发异常。
- 将高频数据转换到低频数据称作降采样。降采样时,待聚合的数据不必拥有固定的频率,期望的频率(低频的)会自动划分聚合的
-
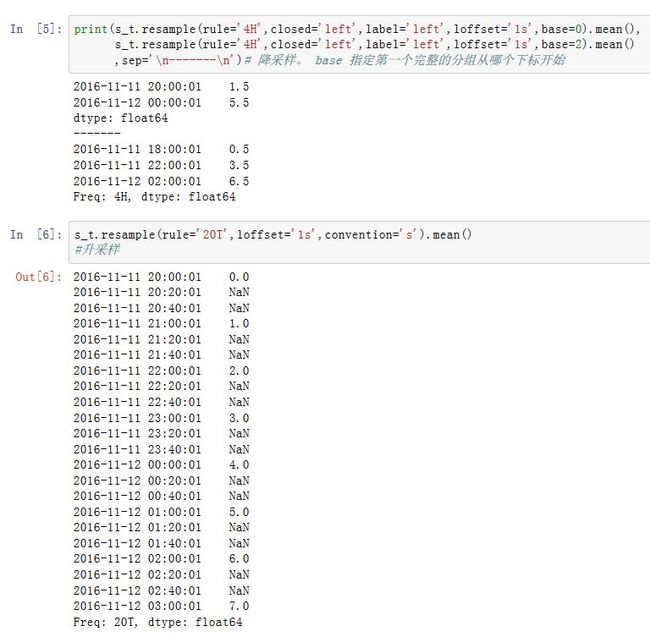
resample方法:Series/DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None,
label=None, convention='start', kind=None, loffset=None, limit=None,
base=0, on=None, level=None)
-
rule:一个字符串,指定了重采样的目标频率 -
axis:为0/'index'表示沿着0轴重采样;为1/'columns'表示沿着1轴重采样 -
closed:一个字符串,指定降采样中,各时间段的哪一端是闭合的。如果为'right',则是左开右闭区间;如果为'left',则是左闭右开区间 -
label:在降采样中,如何设置聚合值的标签。可以为'right'/'left'(面元的右边界或者左边界)。如:9:30~9:35这5分钟会被标记为9:30或者9:35 -
how:用于产生聚合值的函数名或者数组函数。可以为'mean'/'ohlc'/np.max等。默认为'mean',其他常用的有:'first'/'last'/'median'/'ohlc'/'max'/'min'。how被废弃了,而是采用.resample().mean()这种方案。 -
convention:当重采样时期时,将低频转换到高频所采用的约定。可以为's'/'start'(用第一个高频)或者'e'/'end'(用最后一个高频) -
loffset:一个timedelta,用于调整面元(bin)标签。如'-1s',会将用于将聚合的结果标签调早1秒,从而更容易表示它代表哪个区间。比如12:00:00你就难以判别是哪个区间,而11:59:59就很容易知道它是那个区间。你也可以对调用结果对象使用
.shift()方法来实现该目的,这样就不必设置loffset了 -
base:一个整数,默认为0.用于聚合过程中,当频率可以整除1D(比如4H)时,第一个完整的分组从哪个元素开始的。如rule='4H',base=2,则Series[0:1]作为一个分组,Series[2:6]....作为一个分组.... -
on:一个字符串,对于DataFrame,它指定了重采样的列。该列必须是datetime-like -
level:一个字符串或者整数。对于MultiIndex,该参数指定了被重采样的子索引 -
fill_method:一个字符串,指定升采样时,如何插值。如'ffill'/'bfill'。默认不插值该参数被废弃。推荐使用
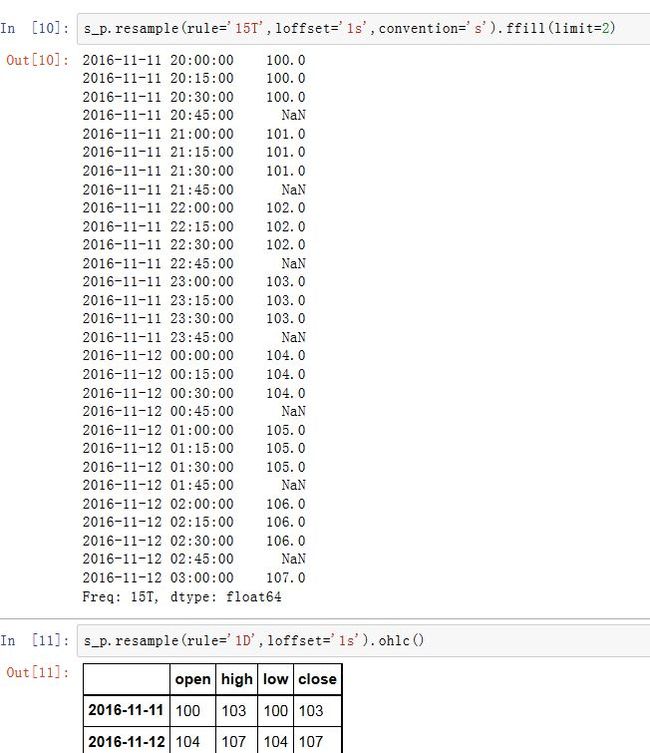
.resample().ffill()这种方案。而limit作为ffill()的参数。 -
limit:一个整数。指定向前或者向后填充时,运行连续填充的最大单元数量 -
kind:一个字符串,指定聚合到时间段Period还是时间戳Timestamp。默认聚合到时间序列的索引类型


-
-
OHLC重采样是计算bin中的四个值:开盘值(第一个值)、收盘值(最后一个值)、最高值(最大值)、最低值(最小值) -
另一种降采样的办法是:使用
groupby功能。如:series.groupby(lambda x:x.month).mean()
如果你想根据年份来聚合,则使用
x.year。

十、 DataFrame 绘图
-
matplotlib是一种比较低级的工具,pandas中有许多利用DataFrame对象数据组织特点来创建标准图表的高级绘图方法。 -
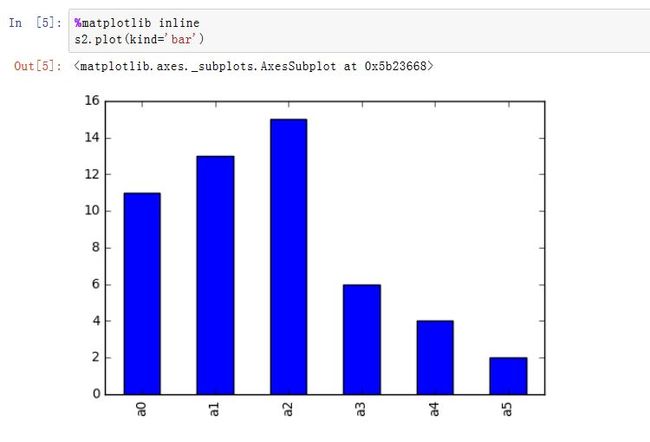
Series/DataFrame.plot():绘制图形。Series.plot(kind='line', ax=None, figsize=None, use_index=True, title=None, grid=None,
legend=False, style=None, logx=False, logy=False,loglog=False,xticks=None,yticks=None,
xlim=None, ylim=None, rot=None, fontsize=None, colormap=None, table=False, yerr=None,
xerr=None, label=None, secondary_y=False, **kwds)
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None,
sharey=False, layout=None, figsize=None, use_index=True, title=None, grid=None,
legend=True, style=None, logx=False, logy=False, loglog=False, xticks=None,
yticks=None, xlim=None, ylim=None, rot=None, fontsize=None, colormap=None,
table=False, yerr=None, xerr=None, secondary_y=False, sort_columns=False, **kwds)
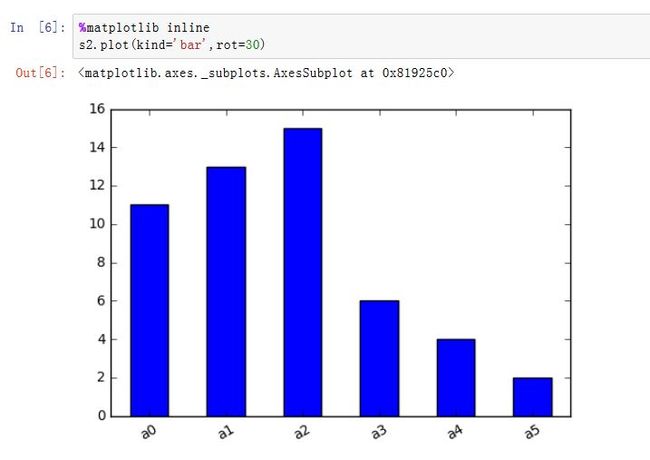
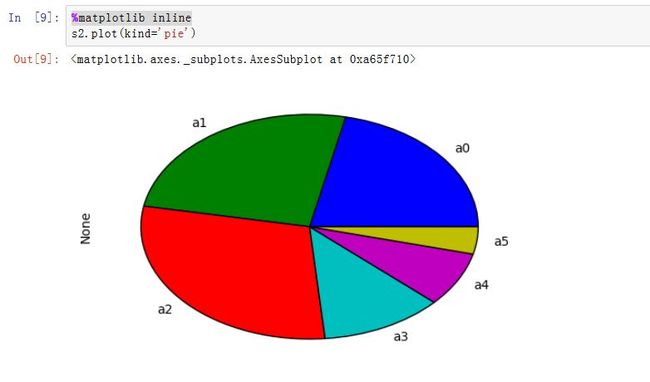
kind:绘制的类型。可以为:'line'、'bar'、'barh'(水平的bar)、'hist'、'box'、'kde'(核密度估计)、'density'(类似kde)、'area'、'pie'ax:一个Axes实例对象。如果为空,则是plt.gca()的返回值(当前Axes)figsize:一个元组,指定图片大小(单位为英寸)use_index:一个布尔值。如果为True,则使用index作为X轴。title:图形的标题grid:一个布尔值。如果为True,则开启网格legend:一个布尔值,如果为True,则放置图例style:一个列表或者字典,给出了每一列的线型logx:一个布尔值,如果为True,则x轴为对数型logy:一个布尔值,如果为True,则y轴为对数型loglog:一个布尔值,如果为True,则x轴和y轴都为对数型xticks:一个序列,用于给出xticksyticks:一个序列,用于给出yticksxlim:一个二元的元组或者序列,给出x轴范围ylim:一个二元的元组或者序列,给出y轴范围rot:一个整数,给出了x轴和y轴tick旋转角度(不是弧度)。fontsize:一个整数,给出了xtick/ytick的字体大小colormap:一个字符串或者colormap对象,给出了colormapcolorbar:一个布尔值。如果为True,则绘制colorbar(只用于scatter和hexbin图中)position:一个浮点数。给出了bar图中,各bar的对其位置(0表示bar的左侧与它的坐标 对其;1表示bar的右侧与它的坐标对其)layout:一个元组。给出了(rows,columns)table:一个布尔值或者Series/DataFrame。如果为True,则将本Series/DataFrame绘制为一个表格;如果为Series/DataFrame,则将该参数绘制为表格yerr:用于绘制Error Barxerr:用于绘制Error Barlabel:plot的label参数secondary_y:一个布尔值或者一个整数序列。如果为True,则y轴绘制在右侧mark_right:一个布尔值,如果为True且secondary_y=True,则在图例中标记为rightkwds:传递给matplotlib中的plot函数的其他关键字参数
在
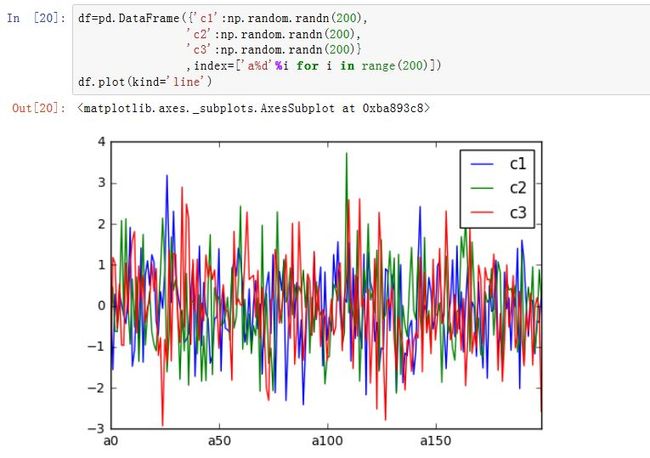
DataFrame.plot中,下面的参数意义为:x:label或者positiony:label或者positionsubplots:一个布尔值,如果为True,则将每一列作为一个子图来绘制sharex:一个布尔值。如果为True,且subplots=True,则子图共享x轴sharey:一个布尔值。如果为True,且subplots=True,则子图共享y轴stacked:一个布尔值。在bar中,如果为True,则将柱状图堆积起来sort_columns:一个布尔值。如果为True,则根据列名来决定绘制的先后顺序。
它们返回的是
AxesSubplot对象,或者AxesSubplot的ndarray



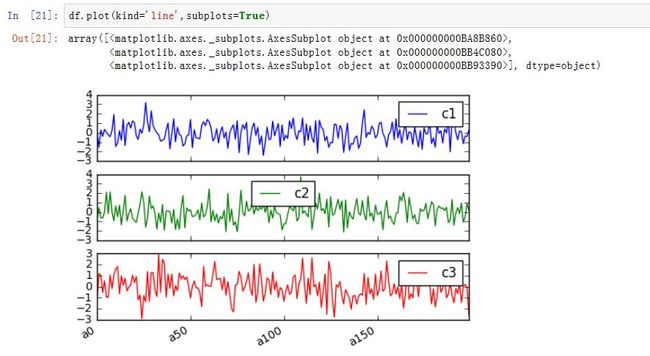
-
给出一组序列,我们可以手工绘制每个序列的散布图,以及各自的核密度估计。我们可以使用
scatter_matrix函数:pandas.tools.plotting.scatter_matrix(frame, alpha=0.5, figsize=None, ax=None,
grid=False, diagonal='hist', marker='.', density_kwds=None, hist_kwds=None,
range_padding=0.05, **kwds)
frame:为DataFrame对象diagonal:选择对角线上的图形类型。可以为'hist'/'kde'hist_kwds:绘制hist的参数density_kwds:绘制kde的参数range_padding:一个浮点数,用于延伸x/y轴的范围。如果它为0.1,表示x轴延伸x_max-xmin的0.1倍 每一个子图是这样生成的:以DataFrame中某一列为横坐标,另一列为纵坐标生成的散点图。

十二、 数据加载和保存
1. 文本文件
-
read_csv可以读取文本文件(.csv格式):pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer',
names=None, index_col=None, usecols=None, squeeze=False, prefix=None,
mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skipinitialspace=False,skiprows=None, nrows=None,na_values=None,
keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True,
parse_dates=False, infer_datetime_format=False,keep_date_col=False,date_parser=None,
dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None,
decimal='.', lineterminator=None, quotechar='"', quoting=0, escapechar=None,
comment=None, encoding=None, dialect=None, tupleize_cols=False,
error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0,
doublequote=True, delim_whitespace=False, as_recarray=False,
compact_ints=False, use_unsigned=False, low_memory=True,
buffer_lines=None, memory_map=False, float_precision=None)
-
filepath_or_buffer:一个字符串,或者一个pathlib.Path对象,或者任何拥有.read()方法的对象。它指定了被解析的文件的位置。如果是个字符串,则必须是个URL(其中包含了协议名,如http//,ftp//,file//等) -
sep:一个字符串,指定了分隔符。默认为','。如果设定为None,则自动决议分隔符。- 如果字符串长度大于1,则自动解析为正则表达式。如
'\s+\解析为空白符
- 如果字符串长度大于1,则自动解析为正则表达式。如
-
delimiter:一个字符串,指定了分隔符。它是sep参数的另一个候选参数 -
delim_whitespace:一个布尔值。如果为True,则将空白符(连续的空白或者单个空白)作为分隔符。此时不需要提供delimiter参数。它等价于sep='\s+' -
header:一个整数或者整数列表。它指定了那些行是标题行,0表示第一行。如果你指定了header=[1,3,5],则第三行(行id=2)和第五行(行id=4)被忽略(不被解析)。- 如果
names参数为空,则header默认值为 0.如果names参数提供了,则header默认值为None
- 如果
-
- 该参数会忽略注释行。 - 如果`skip_blank_lines=True`,则该参数会忽略空白行。因此`header=0`表示第一个有效的数据行
-
names:一个array-like。它给出了列名。- 如果文件不包含标题行,则你需要显式通过
names传入列名 - 如果
mangle_dupe_cols=True,则可以传入重复的列名。否则不允许重复列名
- 如果文件不包含标题行,则你需要显式通过
-
index_col:一个整数,或者序列,或者False。它指定哪一列作为row labels。如果你指定了一个序列,则使用MultiIndex。如果为False,则不采用任何列作为row labels -
usecols:一个array-like。它指定:你将采用哪些列来组装DataFrame。该参数各元素必须要么是代表位置的整数,要么是代表列名的字符串 -
as_recarray:一个布尔值。被废弃的参数。 -
squeeze:一个布尔值。如果为True,则当解析结果只有一列数据时,返回一个Series而不是DataFrame -
prefix:一个字符串。当没有标题时,你可以提供这个参数来给列名加一个前缀。(如果不加前缀,则列名就是0,1,2...) -
mangle_dupe_cols:一个布尔值。如果为True,则重复的列名X,X...被修改为X.0,X.1,...。如果为False,则重复的列名这样处理:后面的覆盖前面的 -
dtype:一个Type name或者字典:column->type。它可以给出每个列的类型。 -
engine:一个字符串,指定用什么解析引擎。可以为'c'/'python'。c更快,但是python拥有更多特性 -
converters:一个字典,给出了每一列的转换函数。字典的键为代表列的位置的整数,或者代表列的名字的字符串。字典的值为可调用对象,参数为一个标量(就是每个元素值) -
true_values:一个列表,给出了哪些值被认为是True -
false_values:一个列表,给出了哪些值被认为是False -
skipinitialspace:一个布尔值。如果为True,则跳过分隔符之后的空白符 -
skiprows:一个array-like或者整数。如果为序列,则指定跳过哪些行(从0计数);如果为整数,则指定跳过文件开头的多少行。注意:空行和注释行也包括在内,这一点和header不同。 -
skipfooter:一个整数。指定跳过文件结尾的多少行。不支持engine='c' -
skip_footer:被废弃的参数 -
nrows:一个整数。指定读取多少行。 -
na_values:一个标量、字符串、字典、列表。指定哪些被识别为NAN。默认的NAN为列表['nan','NAN','NULL'....] -
keep_default_na:一个布尔值。如果为True,则当你指定了na_values时,默认的NAN被追加到na_values上;否则指定的na_values代替了默认的NAN -
na_filter:一个布尔值。如果为True,则不检查NaN,此时解析速度大大加快(但是要求你的数据确实没有NAN) -
verbose:一个布尔值。如果为True,输出解析日志 -
skip_blank_lines:一个布尔值。如果为True,则跳过空白行,而不是解析为NaN -
parse_dates:一个布尔值、整数列表、标签列表、或者list of list or dict。对于iso8601格式的日期字符串,解析速度很快。- 如果为布尔值:如果为
True,则解析index为日期 - 如果为整数列表或者标签列表,则解析对应的列为日期
- 如果列表的列表,如
[[1,3]],则将列1和列3组合在一起,解析成一个单独的日期列 - 如果为字典,如
{'aaa':[1,3]},则将列1和列3组合在一起,解析成一个单独的日期列,日期列的名字为'aaa'。
- 如果为布尔值:如果为
-
infer_datetime_format:一个布尔值。如果为True,且parse_dates非空,则pandas试图从数据中推断日期格式。 -
keep_date_col:一个布尔值。如果为True,并且parse_dates使用多个列合成一列日期,则保留原有的列 -
date_parser:一个函数对象。它将一列字符串转换成一列日期。 -
dayfirse:一个字符串。如果为True,则日期格式为DD/MM -
iterator:一个布尔值。如果为True,则返回一个TextFileReader对象,该对象可以用于迭代或者.get_chunk()来返回数据块 -
chunksize:一个整数。指定TextFileReader对象.get_chunk()返回的数据块的大小。 -
compression:一个字符串。可以为'infer','gzip','bz2','zip','xz',None。如果文件为压缩文件,则它用于指定解压格式 -
thousands:一个字符串。指定了数值中千位数的分隔符,如999,999,999 -
decimal:一个字符串,指定了小数点的分隔符,如9.999 -
float_precision:一个字符串。指定了C engine的转换浮点数的精度。None普通转换,'high'为高精度转换,'round_trip'为round_trip转换。 -
lineterminator:一个长度为1的字符串。指定了C engine中的换行符 -
quotechar:一个长度为1的字符串,它指定了引用字符。比如"aaa,bbb",这种数据是引用数据。如果你用,分隔,则有问题。在引用字符包围的数据中,不考虑分隔符。 -
comment:一个长度为1的字符串,指定了注释字符。如果该字符串出现在行中,则行末的字符不被解析。如果该字符串出现在行首,则本行不被就解析。 -
encoding:一个字符串,指定了编码类型 -
error_bad_lines:一个布尔值。如果为True,则如果某一行有太多字段,则函数抛出异常。如果为False,则抛弃该行,顺利解析。只用于C engine -
warn_bad_lines:一个布尔值。如果为True,且error_bad_lines=False,则对于异常的行,输出警告 -
buffer_lines/compact_ints /use_unsigned:被废弃的参数 -
memory_map:如果为True,且filepath是一个文件名,则使用内存映射,将文件映射到内存中。
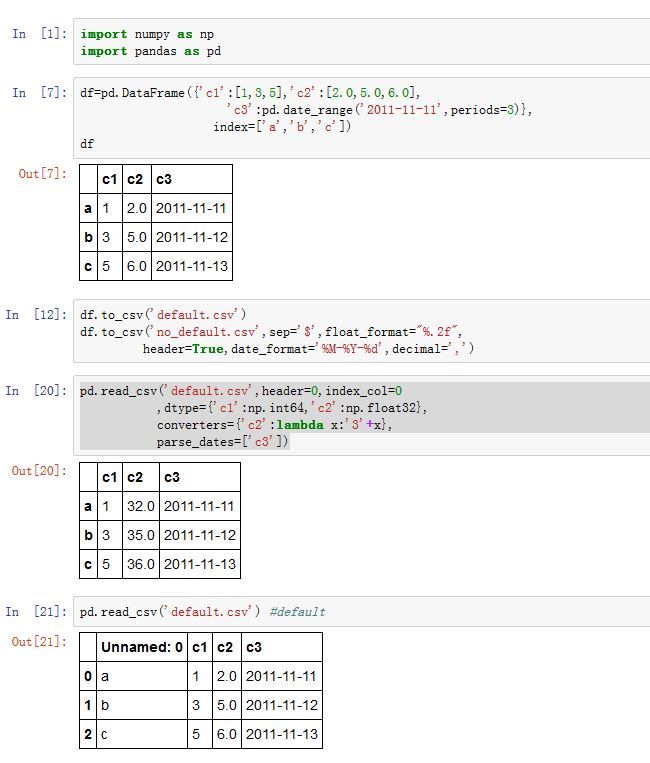
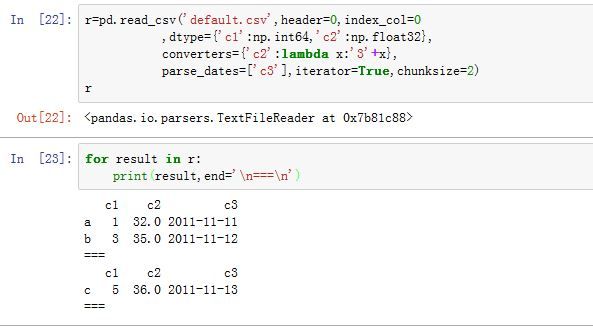
-
read_table也能完成read_csv的功能。二者接口一致。pandas.read_table(filepath_or_buffer, sep='\t', delimiter=None, header='infer',
names=None, index_col=None, usecols=None, squeeze=False, prefix=None,
mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skipinitialspace=False,skiprows=None, nrows=None, na_values=None,
keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True,
parse_dates=False,infer_datetime_format=False,keep_date_col=False, date_parser=None,
dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None,
decimal='.', lineterminator=None, quotechar='"', quoting=0, escapechar=None,
comment=None, encoding=None, dialect=None, tupleize_cols=False,
error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0,
doublequote=True, delim_whitespace=False, as_recarray=False,
compact_ints=False, use_unsigned=False, low_memory=True,
buffer_lines=None, memory_map=False, float_precision=None)
-
DataFrame/Series.to_csv方法可以将数据写入到文件中DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None,
columns=None, header=True, index=True, index_label=None, mode='w',
encoding=None, compression=None, quoting=None, quotechar='"',
line_terminator='\n', chunksize=None, tupleize_cols=False, date_format=None,
doublequote=True, escapechar=None, decimal='.')
Series.to_csv(path=None, index=True, sep=', ', na_rep='', float_format=None,
header=False, index_label=None, mode='w', encoding=None, date_format=None,
decimal='.')
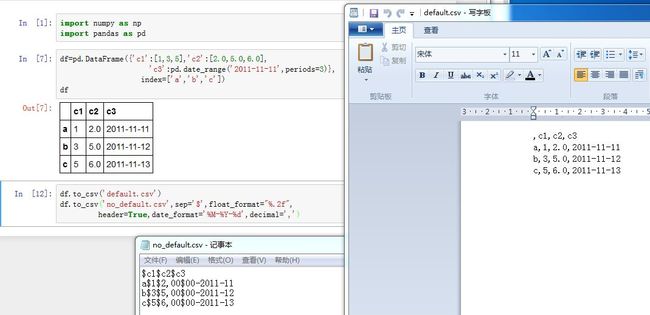
path_or_buf:一个字符串或者file对象。指定写入的文件。如果为空,则返回一个字符串而不是写入文件sep:一个字符串,指定字段的分隔符na_rep:一个字符串,指定NaN的代表字符串float_format:一个字符串,指定了浮点数的格式化字符串columns:一个序列,指定要写入哪些列header:一个布尔值或者字符串列表。如果为True,则写出列名。如果为字符串列表,则它直接指定了列名的别名index:一个布尔值。如果为True,则输出index labelmode:一个字符串,文件操作的读写模式。默认为'w'encoding:一个字符串,指定编码方式compression:一个字符串,指定压缩格式line_terminator:一个字符串,指定换行符chunksize:一个整数,指定了一次写入多少行date_format:一个字符串,给出了日期格式化字符串decimal:一个字符串,给出了小数点的格式tupleize_cols:一个布尔值。如果为True,则MultiIndex被写成list of tuples
2. Json
-
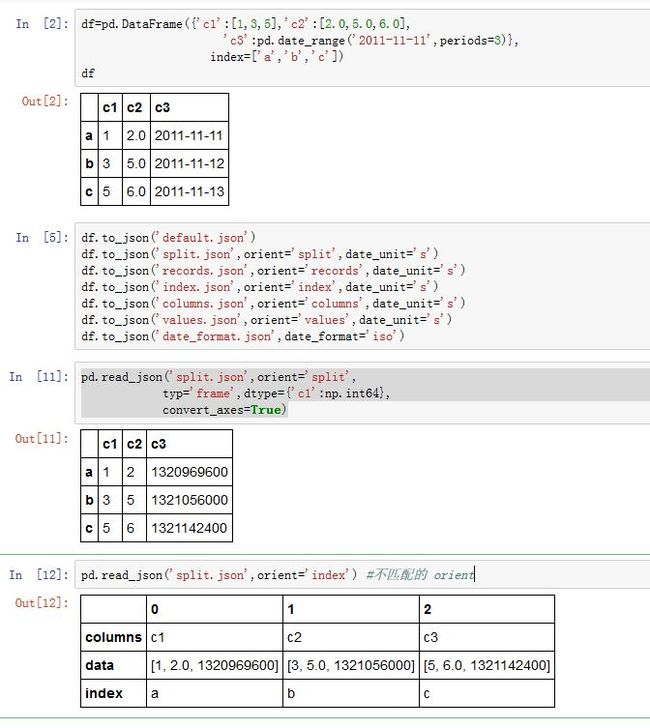
read_json能够读取Json文件:pandas.read_json(path_or_buf=None, orient=None, typ='frame', dtype=True,
convert_axes=True, convert_dates=True, keep_default_dates=True, numpy=False,
precise_float=False, date_unit=None, encoding=None, lines=False)
path_or_buf:一个字符串或者一个file-like对象。如果是个字符串,则必须是个URL(其中包含了协议名,如http//,ftp//,file//等)orient:一个字符串,指定了期望的JSON格式。可选的格式有(参考to_json的实例):'split':JSON是个类似字典的格式:{index -> [index], columns -> [columns], data -> [values]}'records':JSON是个类似列表的格式:[{column -> value}, ... , {column -> value}]'index':JSON是个类似字典的格式{index -> {column -> value}}'columns':JSON是个类似字典的格式{column -> {index -> value}}'values':JSON就是值的序列
注意:如果
type=='series',则允许的'orients= {'split','records','index'},默认为'index',且如果为'index',则要求索引为唯一的。如果type=='frame',则允许上所有的格式,默认为'columns',且如果为'index'/'columns',则要求DataFrame.index为唯一的;如果'index'/'columns'/'records',则要求DataFrame.columns为唯一的typ:一个字符串,指定将JSON转换为Series/DataFrame那一种。可以为'series','frame'dtype:一个布尔值或者字典。如果为True,则自动推断数值类型。如果为False,则不推断类型。如果为字典,则给出了每一列的数值类型convert_axes:一个布尔值,如果为True,则试图转换到合适的数值类型convert_dates:一个布尔值,如果为True,则试图转换日期列为日期。它转换下面这些列名的列:列名以'_at'/'_time'结束、列名以'timestamp'开始、列名为'mofified'/'date'keep_default_dates:一个布尔值。如果为True,则当转换日期列时,保留原列numpy:一个布尔值,如果为True,则直接转换为ndarrayprecise_float:一个布尔值,如果为True,则使用解析为更高精度的浮点数date_unit:一个字符串。用于转换时间戳到日期。它提供时间戳的单位,如's'/'ms'lines:一个布尔值。如果为True,则读取文件的每一行作为一个JSON-encoding:一个字符串,指定编码方式
-
将
pandas对象保存成JSON:Series/DataFrame.to_json(path_or_buf=None, orient=None, date_format='epoch',
double_precision=10, force_ascii=True, date_unit='ms', default_handler=None,
lines=False)
path_or_buf:指定保存的地方。如果为None,则该函数返回一个StringIO对象orient参数:参考read_json()date_format:一个字符串,指定日期转换格式。可以为'epoch'(从1970-1-1日以来的毫秒数)、'iso'double_precision:一个整数,指定了浮点数的精度force_ascii:一个布尔值,如果为True,则将encoded string转换成ASCIIdate_unit:一个字符串,参考read_jsondefault_handler:一个可调用对象。用于处理当对象无法转换成JSON的情况。它只有一个参数,就是被转换的对象lines:一个布尔值。如果orient='records'时,输出换行符。对其他格式则抛出异常

3. 二进制文件
-
pandas.read_pickle(path)可以从pickle文件中读取数据,path为pickle文件的文件名。Series/DataFrame.to_pickle(path):将Series/DataFrame保存到pickle文件中,path为pickle文件的文件名。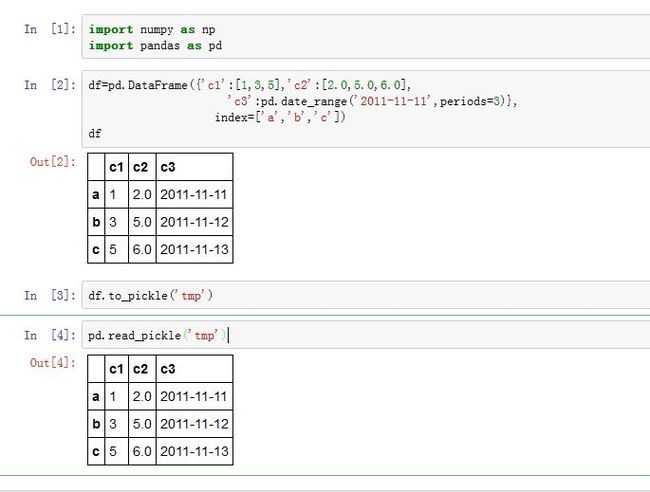
4. Excel 文件
-
read_excel读取Excel文件。需要用到第三方包xlrd/xlwt,前者读excel,后者写excelpandas.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0,
index_col=None, names=None, parse_cols=None, parse_dates=False, date_parser=None,
na_values=None, thousands=None, convert_float=True, has_index_names=None,
converters=None, true_values=None, false_values=None, engine=None,
squeeze=False, **kwds)
io:一个字符串,或者file-like对象。如果是个字符串,则必须是个URL(其中包含了协议名,如http//,ftp//,file//等)sheetname:一个字符串或者整数,或者列表。它指定选取Excel文件中哪个sheet。字符串指定的是sheet名,整数指定的是sheet的位置(0为第一个sheet)engine:一个字符串,指定了读写Excel的引擎。可以为:io.excel.xlsx.writer、io.excel.xls.writer、io.excel.xlsm.writer、- 其他参数参考
read_csv

-
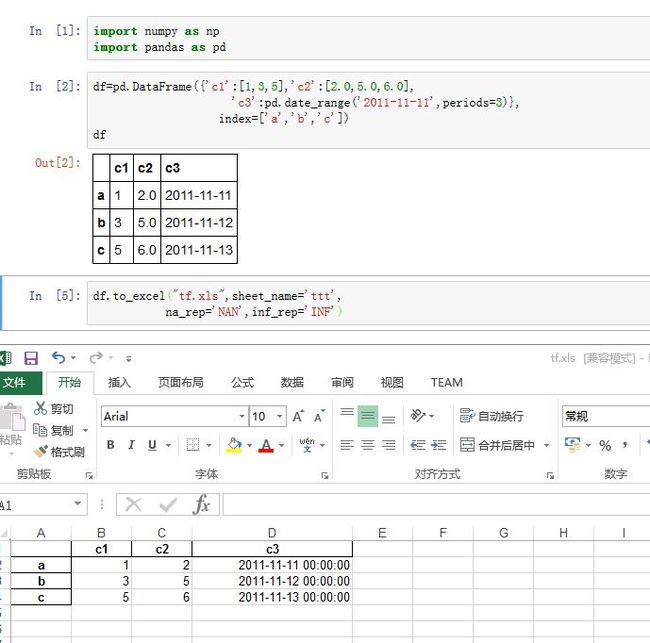
保存
DataFrame到Excel文件:DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='',
float_format=None, columns=None, header=True, index=True, index_label=None,
startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None,
inf_rep='inf', verbose=True)
excel_writer:一个字符串(文件名)或者一个ExcelWriter对象sheet_name:一个字符串,指定sheet名na_rep:一个字符串,代表NaNstartrow/startcol:指定了左上角的单元格的位置engine:一个字符串,指定了读写Excel的引擎。可以为:io.excel.xlsx.writer、io.excel.xls.writer、io.excel.xlsm.writer、merge_cells:一个布尔值。如果为True,则多级索引中,某些索引会合并单元格inf_rep:一个字符串,只代表无穷大。
5. HTML 表格
-
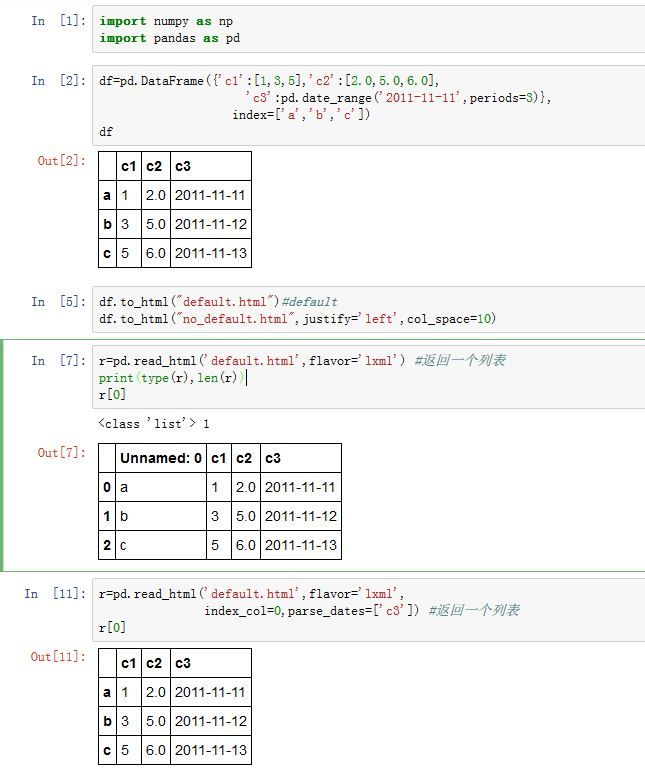
read_html可以将HTML中的DataFrame列表。pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None,
skiprows=None, attrs=None, parse_dates=False, tupleize_cols=False,
thousands=', ', encoding=None, decimal='.', converters=None,
na_values=None, keep_default_na=True)
io:为一个字符串或者一个file-like对象。match:一个字符串或者正则表达式。HTML中的flavor:一个字符串,指定了解析引擎。可以为'bs4'或者'html5lib'或者'lxml'attrs:一个字典。它筛选出你要解析哪些表格- 其他参数参考
read_csv
-
可以通过
DataFrame.to_html()转换为HTML的表格:DataFrame.to_html(buf=None, columns=None, col_space=None, header=True,
index=True, na_rep='NaN', formatters=None, float_format=None,
sparsify=None, index_names=True, justify=None, bold_rows=True,
classes=None, escape=True, max_rows=None, max_cols=None, show_dimensions=False,
notebook=False, decimal='.', border=None)
bold_rows:一个布尔值。如果为True,则让row label加粗classes:一个字符串或者列表或者元组,给出了table的css classescape:一个布尔值,如果为True,则将字符<>&为安全的HTML字符max_rows:一个整数,指定最大输出行数。默认显示全部的行decimal:一个字符串,指定了小数点的格式border:一个整数,给出了border属性的值。buf:指定将HTML写到哪里,它是一个StringIO-like对象col_space:一个整数,给出每一列最小宽度header:一个布尔值,如果为True,则打印列名columns:一个序列,指定要输出哪些列index:一个布尔值,如果为True,则打印index labelsformatters:一个一元函数的列表,或者一元函数的字典。给出了每一列的转换成字符串的函数float_format:一个一元函数,给出了浮点数转换成字符串的函数justify:左对齐还是右对齐。可以为'left'/'right'



6. SQL
-
read_sql_table从指定数据表中,提取你所需要的列。pandas.read_sql_table(table_name, con, schema=None, index_col=None,
coerce_float=True, parse_dates=None, columns=None, chunksize=None)
-
table_name:一个字符串,指定了数据库的表名 -
con:一个SQLAlchemy conectable或者一个database string URI,指定了连接对象它就是SQLAlchemy中的Engine对象。 -
schema:一个字符串,给出了SQL schema(在mysql中就是database) -
index_col:一个字符串或者字符串列表,指定哪一列或者哪些列作为index -
coerce_float:一个布尔值,如果为True,则试图转换结果到数值类型 -
parse_dates:一个列表或者字典。指定如何解析日期:- 列名的列表:这些列将被解析为日期
- 字典
{col_name:format_str}:给出了那些列被解析为日期,以及解析字符串 - 字典
{col_name:arg dict}:给出了哪些列被解析为日期,arg dict将传递给pandas.to_datetime()函数来解析日期
-
columns:一个列表,给出了将从sql中提取哪些列 -
chunksize:一个整数。如果给出了,则函数返回的是一个迭代器,每次迭代时,返回chunksize行的数据。
-
-
read_sql_query可以选择select query语句。因此你可以执行多表联合查询。pandas.read_sql_query(sql, con, index_col=None, coerce_float=True,
params=None, parse_dates=None, chunksize=None)
sql:一个SQL查询字符串,或者SQLAlchemy Selectable对象。params:一个列表,元组或者字典。用于传递给sql查询语句。比如:sql为uses %(name)s...,因此params为{'name':'xxxx'}- 其他参数见
read_sql_table

-
read_sql是前两者的一个包装,它可以根据sql参数,自由地选择使用哪个方式。pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None,
parse_dates=None, columns=None, chunksize=None)
sql:一个数据表名,或者查询字符串,或者SQLAlchemy Selectable对象。如果为表名,则使用read_sql_table;如果为后两者,则使用read_sql_query
-
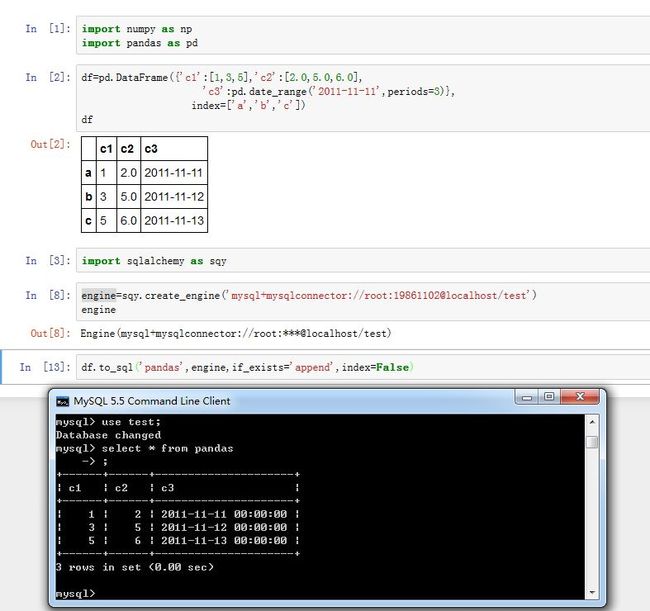
pandas对象的.to_sql()方法用于插入数据库。Series/DataFrame.to_sql(name, con, flavor=None, schema=None, if_exists='fail',
index=True, index_label=None, chunksize=None, dtype=None)
name:一个字符串,指定表名con:一个SQLAlchemy conectable或者一个database string URI,指定了连接对象。它就是SQLAlchemy中的Engine对象。flavor:被废弃的参数schema:一个字符串,指定了SQL schemaif_exists:一个字符串,指定当数据表已存在时如何。可以为:'fail':什么都不做(即不存储数据)'replace':删除数据表,创建新表,然后插入数据'append':如果数据表不存在则创建数据表然后插入数据。入股数据表已存在,则追加数据index:一个布尔值。如果为True,则将index作为一列数据插入数据库index_label:index的存储名。如果index=True,且index_label=None,则使用index.namechunksize:一个整数。 如果为None,则一次写入所有的记录。如果非空,则一次写入chunksize大小的记录dtype:一个字典。给出了各列的存储类型。