面试复习(查漏补缺)
数据库系统原理
索引
索引是帮助MySQL高效获取数据的排序好的数据结构
建立的索引是存储在本地磁盘中的
- 索引结构
- 二叉树
- 红黑树
- Hash表
- B—Tree
二叉树
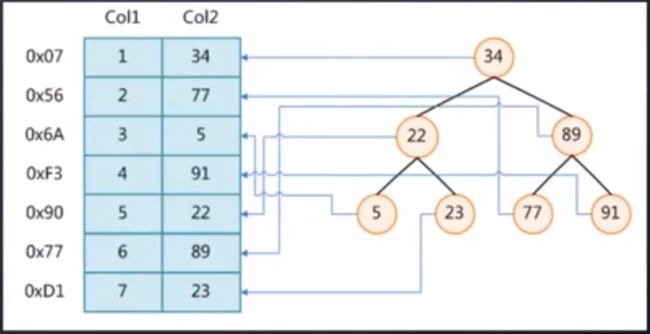
某些场景下二叉树有弊端,所以Mysql使用的是B+ 树来做索引
当索引为以下的情况时建立索引并不会加速查询速度
HashMap在JDK1.8之后将底层的链表优化成红黑树
红黑树
红黑树(平衡二叉树)演示地址:https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
红黑树的弊端
在面对大数量的时候也是需要很大的查询效率(磁盘IO)!很多层(需要解决树的高度问题)
可以使用B+树(多分几个叉)
B-Tree
每个节点上最多16K
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排序
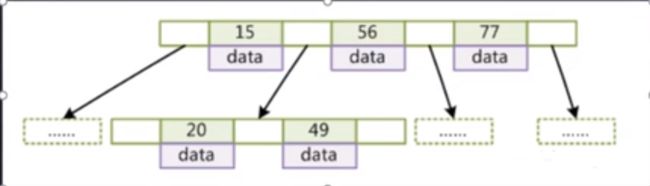
B+ Tree
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针链接,提高区间访问的性能
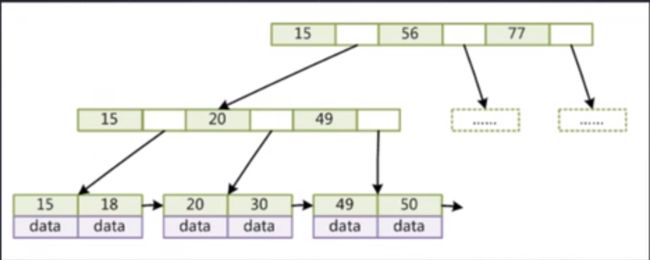
优点:
- 保证树的高度在一个可控的范围
- 尽可能的存储较多的索引
- 存储的元素为:1170 * 1170 * 16
- 对于范围查找很快,有类似链表的最下面data的区域,而B树没有。
存储引擎是来修饰表结构的
Hash
等值查找很快的。直接就能搜索到,但是不使用
原因是:对于范围查找很难。不支持
存储引擎
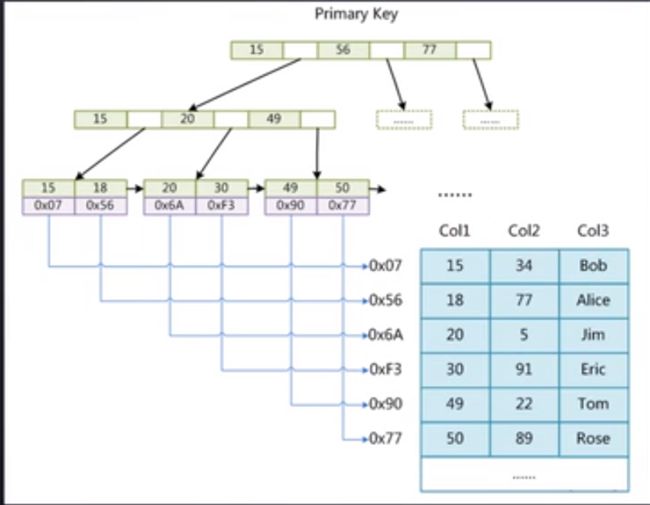
MyISAM存储引擎
MyISAM索引文件和数据文件是分离的(非聚集)
-
首先从MYI文件中查找到对应的index索引记录。
-
根据index索引去MYD文件中查找对应的data记录
InnoDB存储引擎
- 表数据文件本身就是按B++Tree组织的一个索引结构文件
- 聚集索引 : 叶节点包含了完整的数据记录
- 为什么非索引结构子节点存储的是主键值?(一致性和节省存储空间)
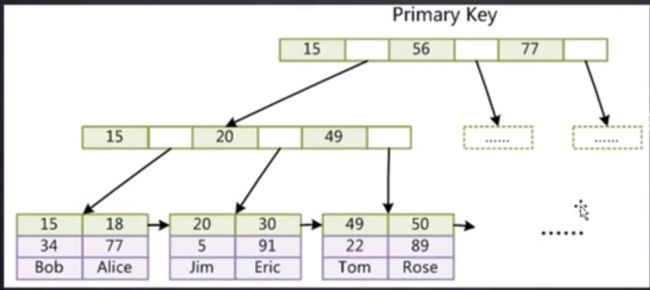
为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
解:
InnoDB是根据主键去间索引树的,当我们没有去建主键的时候,mysql会帮助我们去建一个主键(自动寻找唯一索引),如果整张表都没有唯一的数据mysql会在后台给我们生成一个唯一的rodId字段。
整型比较的速度比字符串的比较速度快多了。字符串需要转换成ASCII 码,然后再进行比较。整形存储空间个更小
联合索引的底层存储结构长什么样?
JDK体系及JVM
JVM内存区域
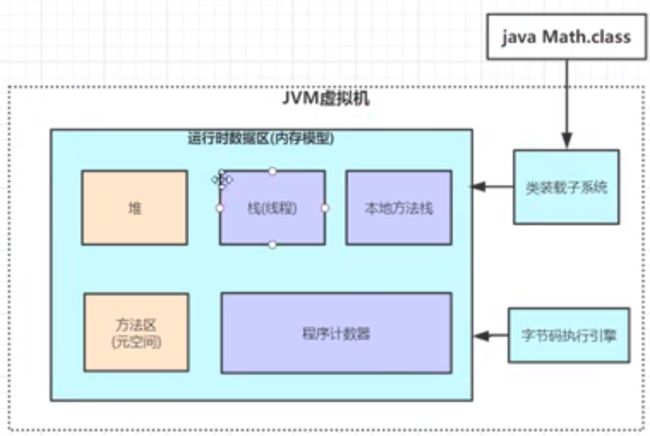
栈:放局部变量(线程栈)-> 放自己局部变量的内存区域。
当调用到方法的时候,会给对应的方法分配栈帧。分配专属的内存区域。放自己方法内部的局部变量
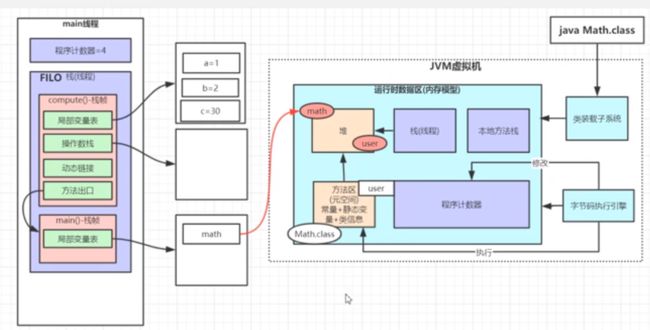
- 给每个方法在栈中分配对应的内存区域,内存区域中对应着方法内部的局部变量
- 先调用的方法后执行完成,后调用的方法先执行完成。
程序计数器(每个线程独有的):用来存放程序运行代码的位置。----> 由字节码执行引擎去记录的
作用: 当别的线程抢占资源的时候,程序计数器会保存当前执行的顺序。当其他线程执行结束后,又回来这个程序可以继续 执行。(挂起)
方法区:存放的是共有的静态变量及方法的指针。常量,类信息 —> 对应的指针指向堆内存中对应的类对象或者方法
本地方法栈:留给java系统里面来执行C语言相关的指令操作Native
堆的划分(minor gc)
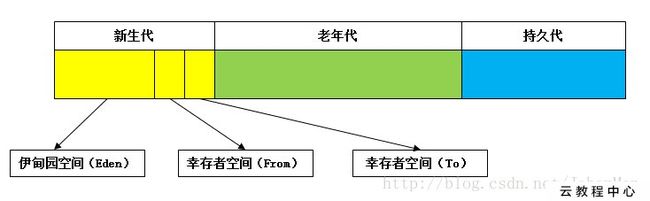
可达性分析算法
将"GC Roots"对象作为起点,从这些节点开始向下搜索引用的对象,找到的对象都标记为非垃圾对象,其余未标记的对象都是垃圾对象GC Roots根节点:线程栈的本地变量,静态变量,本地方法栈的变量等等。(即没有对象引用的变量)
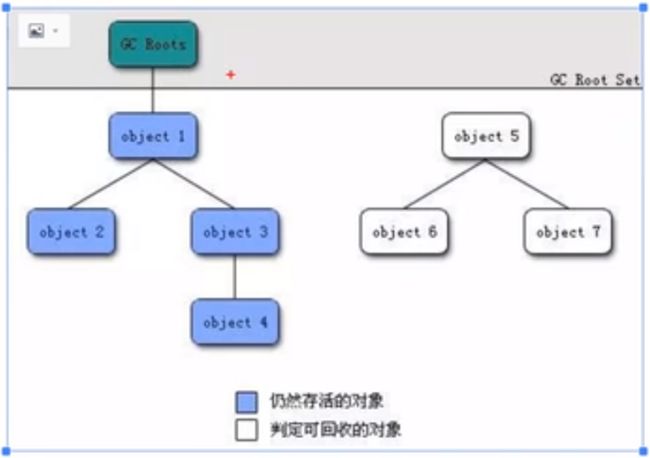
搜集完成一次GC之后,会把没有引用的变量直接回收掉(清楚)。然后将没有被回收的变量指针放入From(幸存者)中
—> 分代年龄会加1
当再次GC的时候,会把From中的对象,挪到To中,并把分代年龄+1
再次GC ----> 把To中的对象,再次挪到From中,Eden也移动进去,并且从To中移到From的年龄+1
直到 对象的分代年龄超过15 会一次性被垃圾回收放入老年代中。(因为很多次没有被移走,说明是一个永久变量)
**大对象:**直接放入到老年代中。
当老年代放满的时候:会尝试full gc。如果发现没有可以收集的化,就会出现内存溢出。
STW:Stop the world
虚拟机调优的目的是:减少STW–Full gc
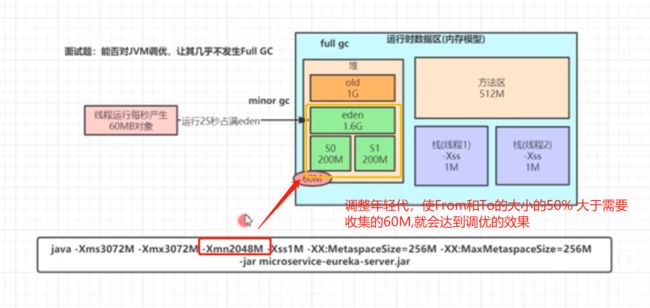
JMM
Java内存模型
- CPI多核并发缓存架构刨析
- Java线程内存模型底层的实现原理
- CPU缓存一致性协议详解
- 理解Volatile关键字
- 并发编程的可见性,原子性,有序性
Java线程内存模型根cpu缓存模型类似,是基于cpu缓存模型来建立的,Java线程内存模型是标准化的,屏蔽了底层不同计算机的区别。
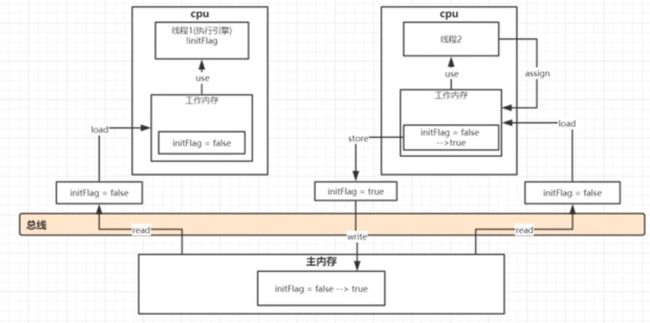
每个java线程在运行的时候会在自己的线程中存一个工作内存,存放共享变量
如果你在线程A中改变了这个变量,线程B是不会感应到的
使用volatile:可以保证共享变量之间的可见性。
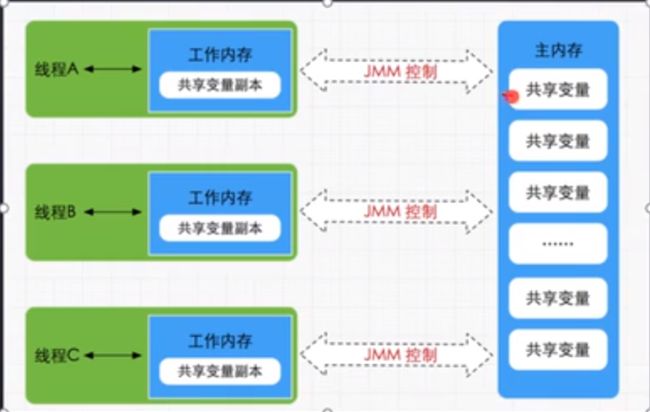
数据原子操作:
- read(读取):从主内存读取数据
- load(载入): 将主内存读取到的数据写入工作内存
- use(使用): 从内存读取数据来计算
- assign(赋值): 将计算好的值重新赋值到工作内存中
- store( 储存): 将工作内存数据写入主内存
- write(写入): 将store过去的变量值赋值给主内存中的变量
- unlock(解锁): 将主内存变量解锁,解锁后其他线程可以锁定该变量
只要数据开启了总线监听机制(MESI缓存一致性协议):各个线程会监听着总线的变化,当对应的值做出了修改,总线中会将对应的线程中的工作内存的值给失效掉。下次调用失效的值的时候,会再次区主内存中取值。
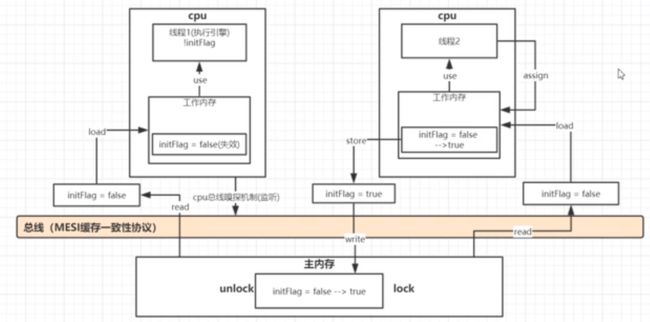
并发编程三大特性:可见性,原子性,有序性
volatile保证可见性与有序性,但是不保证原子性,保证原子性需要借助synchronized这样的锁机制
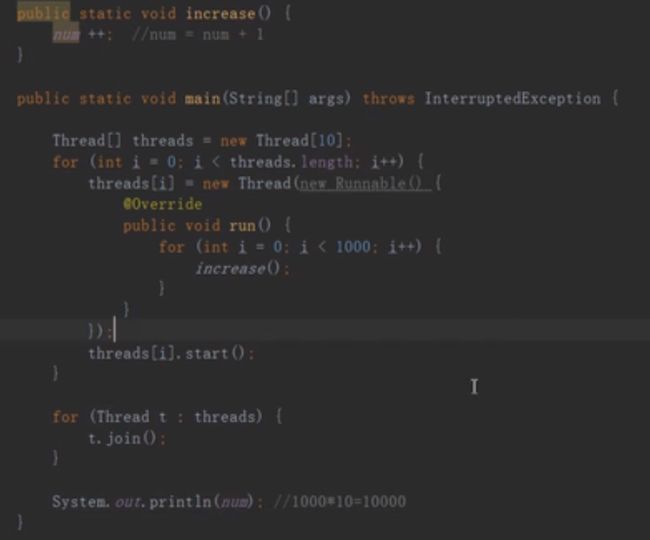
开启十个线程,每个线程都+1000 --> 并不会得到原子性的操作。
刨析spring(跳过)
ContextLoaderListener ----------------------> spring.xml -------------> 父配置: (数据源 dao service)
DispatcherServlet -----------------------------> spring-mvc.xml ------> 子配置: (controller)
通过注解也可以为我们的组件注入
@WebServlet(value={"/tulingHello"}) 注入我们的web三大组件之一 servlet (Listeninger,Filter)
@WebFilter(value={"/tulingHello"})
web容器中 web.xml @WebServlet
SPI: 通过ServiceLoader的类去读取文件目录下对应的配置类似 (properties文件)
通过这种方式 ,实现了ServletContainerInitializer之后有个方法onStartup() 我们可以在里面给容器注入新的类
----> 这样的话,对于这些对应的方法,我们也可以往容器中注入对应的类
-----> SPI机制,我们也可以注册三大组件
以下这两段配置功能是一样的:
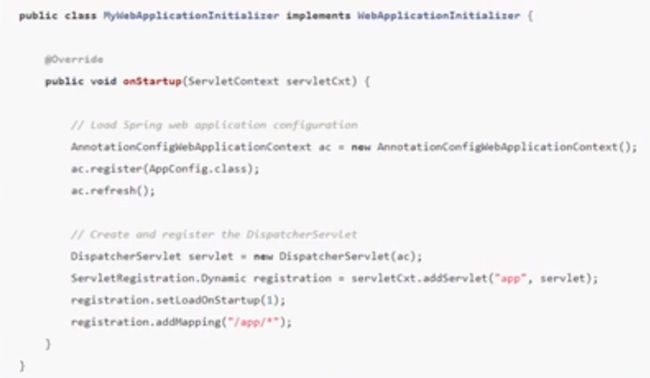
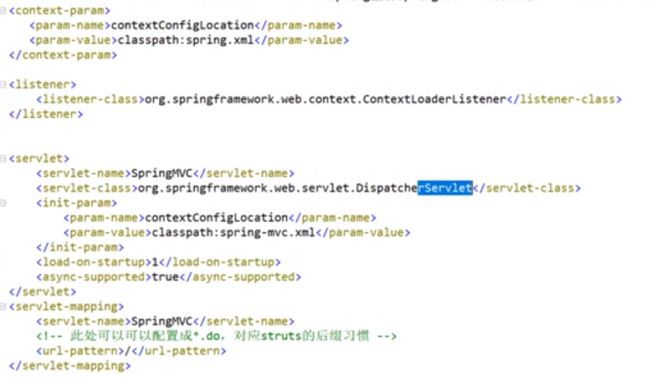
public void onStartup(ServletContext servletContext) throws ServletException{
1:创建我们的容器(****************此时根容器是空的**************)
2:new 了我们的ContextLoaderListener
3:把我们的根配置类保存到我们的根容器中
4:把我们的ContextLoaderListener注册到servletContext
super.onStartup(servletContext);
// 创建我们的子容器(********* 子容器也是空的)
// 创建我们的 DispatcherServlet
registerDispatcherServlet(servletContext);
}
Bean解析(跳过)
通过@Bean注解来注入配置类
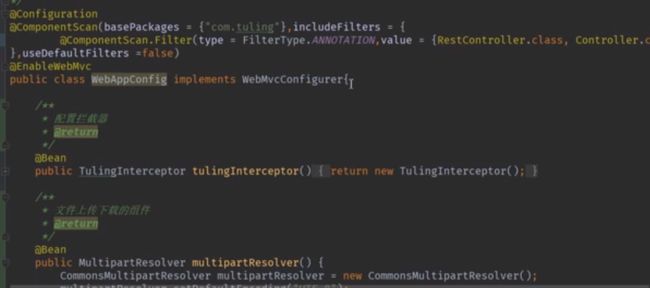
导入bean定义
@Import(TulingTmportSelector.class)
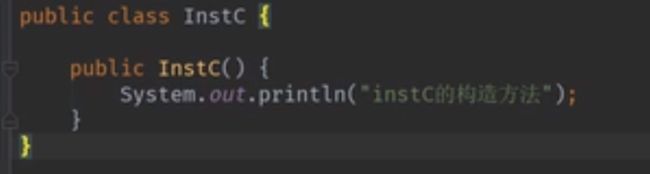
- @Import(value={InstC.class}) 导入一个普通的类
- @Import(value={TulingImportBeanDefinitionRegister.class}) 实现了TulingImportBeanDefinitionRegister接口

- @Import(value={TulingImportSelector.class}) (可以导入多个)

并发问题的解析
出现超卖的情况:
每个线程都会从共享的变量中,取到对应的值,然后把该值,在自己的线程上做一个副本.
这样在秒杀系统中就会出现超卖的情况
解决方法:
- 可以在对应的操作里面加上synchronized
- 可以使用aqs的锁机制
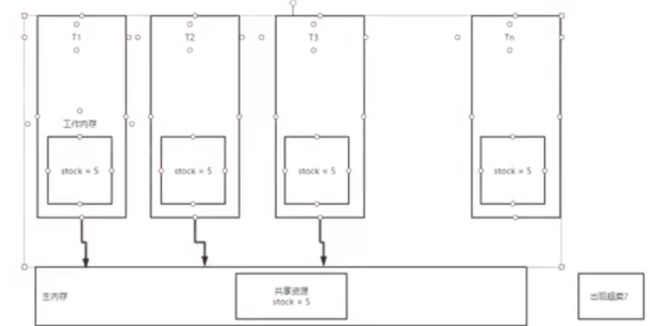
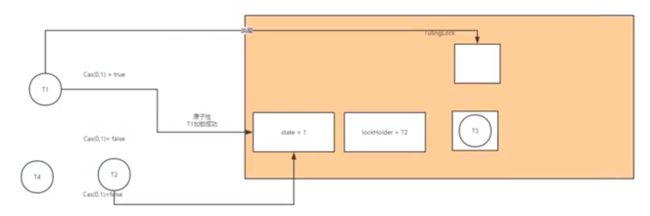
抽象队列同步器(AQS)
synchronized(底层基于C++,语言实现的同步机制)
Aqs同步器(java 实现)
—>
- 任意时刻,只能有一个线程加锁成功
Unsafe魔法类: 绕过虚拟机,直接操作底层的内存
HashMap(底层刨析)
初始化的时候默认的容量是16 (必须是2的指数此幂)
Java7 —> 数组 + 链表
Java8 ----> 数组 + 链表 + 红黑树 (性能提升10%左右)
**数组:**使用连续的一段单元存储数据。对于指定下标的查找,时间复杂度为O(1),对于一般的删除,插入操作平均复杂度为O(n)
--> 因为需要移动数组。
**线性链表:**删除操作在查找到对应要删除的位置之后,只需要处理节点的引用即可O(1)。已经来到了对应的位置
查找操作需要遍历链表为O(n)
**红黑树:**一种接近平衡搜索二叉树,在每个节点上增加一个存储位表示节点的颜色,可以是Red或Black。通过对任何一条从根到叶子的路径上各个节点着色方式的限制,红黑树确保没有一条路径会比其他路径长出两倍。接近平衡
查找,插入,删除等操作,其平均时间复杂度为O(logn) 最坏
五个特性:
- 每个节点要么是红的要么是黑的
- 根节点是黑色的
- 每个叶子节点都是黑色的
- 如果一个节点是红色的那么他的两个儿子都是黑色的
- 对于任意节点而言,其到叶节点树尾端NIL指针的每条路径都包含相同数目的黑色节点
当你给HashMap指定初始容量为13时,底层会被转换为2n ----> 16 (最接近13的最大2的指数此幂)
① 比如给定的 初始化容量为8 那么就会形成一个长度为8的数组,用来存放碰撞的hash值

② 当计算key的hash值,采用位运算(非 - > hashcode取模%8) 得到的值是一样的话会在对应数组下标形成一个链表,插入数组中
注:java7 插入的链表是头插法
位运算的效率高于取模 ----> 几乎等价于取模运算(就需要是2的整数次幂) h & (length - 1)[0 - 15]
进行扩容:扩容的时候 需要把旧的数组转移到新的数组

当数据量很大的时候,会触发多次扩容!触发多次rehash --> 位运算数量级上去,体现了位运算的好处。
HashMap 线程不安全?
- 数据丢失
- 死锁
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
以上这个方法在多线程环境下可能会造成死锁。
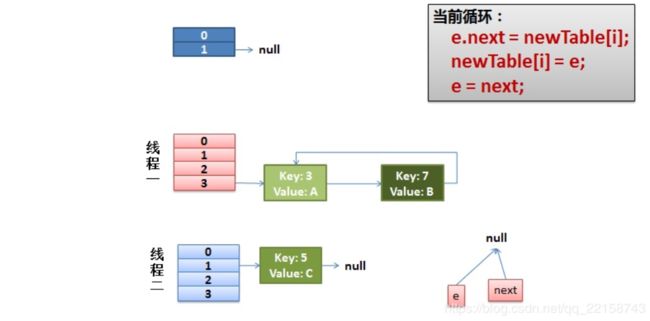
JDK8之后不会死锁
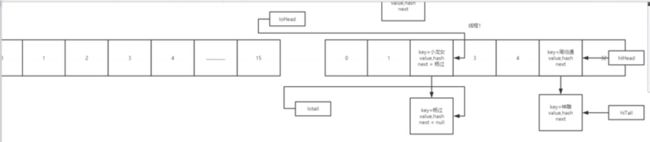
4个指针: 在一个链表上切割出50% 50% 减少,两个指针交换的顺序 (分割成两部分)
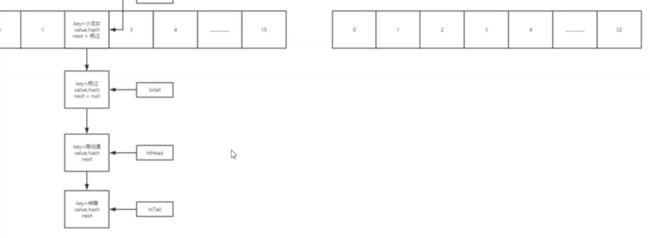
切割之后,避免了体位的转换,避免了死锁
加载因子为什么是0.75?
如果太小的话扩容因子为0.2 0.3 这样如果初始值为8的话,我们满足了2个以上就要进行扩容,浪费了很多的容量(空间上浪费了)
如果太大,为1 的话 —> hash碰撞的几率还是蛮高的,如果要填满8个位置的话,其实那个链表/红黑树会很长(效率上浪费了)
用公式推算出来的话是log2 ==> 0.693 ==> 0.75(计算方便) (超过这个扩容因子,默认会扩容两倍)
JDK8之后,链表长度达到8的时候,才会把链表转为红黑树?
-
当链表长度 < 64 (优先扩容)
-
当链表长度大于等于64之后,链表长度超过8之后,才会转换为红黑树
-
链表转红黑树,阈值=8 ,实际链表长度是9
线程操作
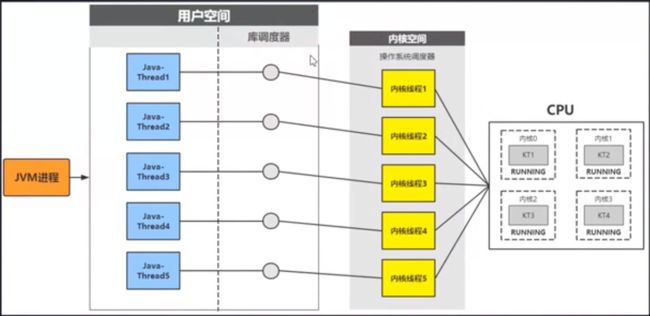
KLT(内核级线程):内核级线程。当创建多个线程的时候,任务管理器中的线程数会直接增加多个线程。(Java中使用)
ULT(用户级线程)
Java线程创建是依赖于系统内核,通过JVM调用系统库创建内线程,内核线程与Java-Thread是1:1的映射关系 (内核级线程)
线程池的底层原理 (线程创建需要消耗资源,线程池可以好好利用资源) 什么时候使用
- 创建大量线程会造成大量的上下文切换,状态切换
- 单个任务处理时间比较短
- 需要处理的任务数量比较大
线程池的优势:
- 重用存在的线程,减少线程创建,消亡的开销,提高性能
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行
- 提高线程的可管理性,可同一分配,调优和监控
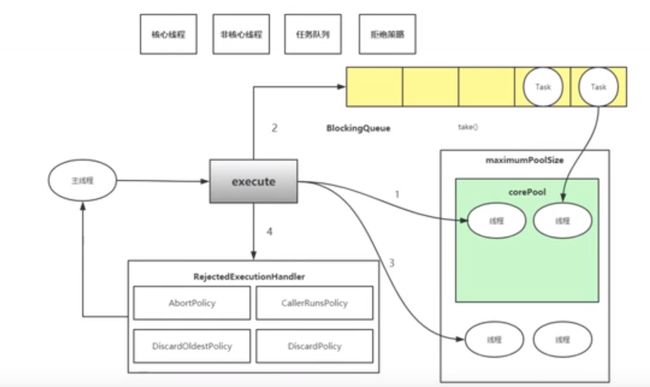
线程池的五种状态
- Running:能接收新任务以及处理已添加的任务
- Shutdown:不接受新的任务,可以处理已经添加的任务
- Stop:不接受新的任务,不处理已经添加的任务,并且中断正在处理的任务
- Tidying:所有的任务已经终止,ctl记录的“任务数量”为0,ctl负责记录线程池的运行状态与活动数量
- Terminated:线程池彻底终止,则线程池转变为terminated状态
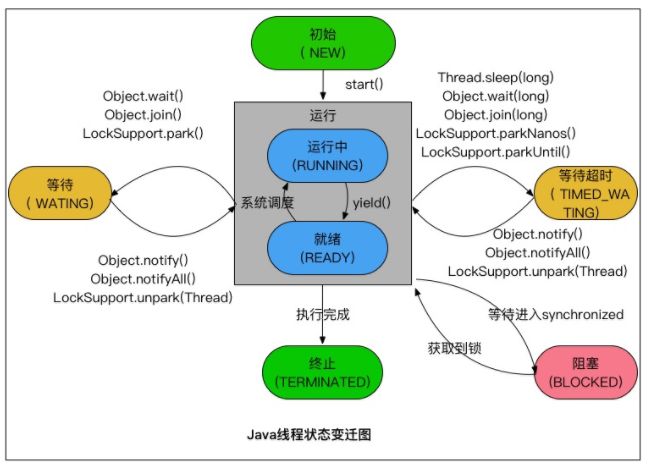
单例模式(序列化和反序列化的单例模式)—> 实现签名方法
Docker
安装
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bpvSNKSD-1597891001518)(C:\Users\晨边\AppData\Roaming\Typora\typora-user-images\image-20200802210423308.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8VvaMnJz-1597891001519)(C:\Users\晨边\AppData\Roaming\Typora\typora-user-images\image-20200802210456169.png)]
run: 下载(pull) 创建(create) 运行 start 一次性搞定
docker run --name myNginx --rm -p 80:80 nginx
- –name myNginx: 指定容器名字
- –rm : 运行结束后删除(这是一个临时容器)
- 80:80 : 主机端口,容器内部端口
docker ps #查看当前正在运行的程序
docker ps -a #查看所有的容器
docker stop `id` #关闭对应的程序
docker logs myNginx #查看容器的日志
容器其实也是一个精简版的操作系统
- 进入容器
docker exec -it myNginx bash # 进入容器的操作系统
常用参数说明:
- -p 指定端口映射
- -u 指定运行用户
- -e 设置环境变量
- -d 后台启动
- -v 设置挂载目录(通过:分割两边文件,两边都要写绝对路径)
- -h 设置hostname
- –rm 容器停止后删除
- –name 容器名称
- –ip 指定容器ip
docker pull tomcat:8 #下载tomcat
docker images #查看本地仓库的镜像
使用
新建一个文件Dockerfile
docker build -t luban_nginx ./ # 构建镜像 -----> 可以查看docker images
docker run --rm -p 80:80 luban_nginx
新建文件
echo "I love lv" > test.txt # 新建文件
echo "I very" >> test.txt # 追加

暑期在中国科学院软件应用技术研究所学习的内容。
之前用Typora写了之后上传到GitHub
现在搬运过来csdn了
Spring Cloud
https://www.bilibili.com/video/BV1QE411N7kP?p=87