python进阶-12.pandas-索引操作-算术运算
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
文章目录
- 3.1索引
- 索引的删除
- 索引的选取与过滤
- Series 支持 bool 序列读取
- 3.2 算数运算与数据对齐
- DataFrame 算术运算
- df1.add(df2,fill_value=xxx)
- 其他几个运算符的函数
- DataFrame 与 Series 运算
3.1索引
s1=Series(range(1,5),index=list('ABCD'))
s1
A 1
B 2
C 3
D 4
dtype: int64
s1.index
Index(['A', 'B', 'C', 'D'], dtype='object')
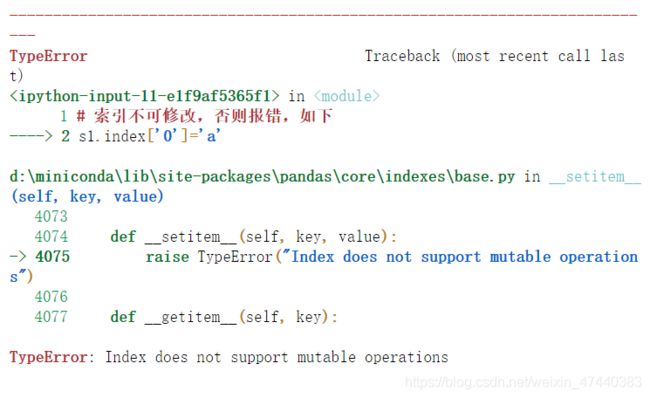
- 索引不可修改,否则报错,如下
s1.index['0']='a'
- #但是可以整体换掉
s1.index=list('abcd')
s1
a 1
b 2
c 3
d 4
dtype: int64
索引的删除
-
obj.drop(‘index’,axis=0,inplace=False)默认删除行索引
-
obj.drop(‘column’,axis=1,inplace=False)删除索引列
-
默认都是返回新值,除非 inplace=True
df1 = DataFrame(
np.arange(16).reshape(4,4),
index = list('abcd'),
columns = 'one/two/three/four'.split('/')
)
df1
one two three four
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
df1.drop('a')
one two three four
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
df1.drop(['d','c'])
one two three four
a 0 1 2 3
b 4 5 6 7
df1.drop(['two','four'],axis=1)
one three
a 0 2
b 4 6
c 8 10
d 12 14
索引的选取与过滤
- 选取就是读取
- 过滤就是选取想要的数据
list2=list(range(6,13))
np.random.shuffle(list2)
s2=Series(list2,index=list('abcdefg'))
s2
a 9
b 10
c 12
d 6
e 11
f 7
g 8
dtype: int64
for each in s2.index:
print(f'index:{each},value:{s2[each]}')
index:a,value:9
index:b,value:10
index:c,value:12
index:d,value:6
index:e,value:11
index:f,value:7
index:g,value:8
- #找出小于9的
for each in s2.index:
if s2[each]<9:
print(f'index:{each},value:{s2[each]}')
index:d,value:6
index:f,value:7
index:g,value:8
Series 支持 bool 序列读取
s2<9
a False
b False
c False
d True
e False
f True
g True
dtype: bool
s2[s2<9]
d 6
f 7
g 8
dtype: int64
s2[s2%2==0]
b 10
c 12
d 6
g 8
dtype: int64
- 重置 索引,会匹配,匹配不上则 NAN
s2.reindex(list('AbcdEfg'))
A NaN
b 10.0
c 12.0
d 6.0
E NaN
f 7.0
g 8.0
dtype: float64
- #fill_value =xxx, 填充nan的位置为 xxx
s2.reindex(list('AbcdEfg'),fill_value=0)
A 0
b 10
c 12
d 6
E 0
f 7
g 8
dtype: int64
3.2 算数运算与数据对齐
- 准备 俩 Series
s1 = Series([1,2,3,4],index=list('abcd'))
s2 = Series([5,6,7,8],index=list('abef'))
- 算数 加法
s1+s2
a 6.0
b 8.0
c NaN
d NaN
e NaN
f NaN
dtype: float64
s1.add(s2)
a 6.0
b 8.0
c NaN
d NaN
e NaN
f NaN
dtype: float64
- #执行 加法前 把匹配不上得位置 换成 指定值,如0 然后再执行加法
s1.add(s2,fill_value=0)
a 6.0
b 8.0
c 3.0
d 4.0
e 7.0
f 8.0
dtype: float64
- #直接对某一个对象 填充 nan xxx.fillna(yyy) 将xxx中的nan换成yyy
s1.add(s2).fillna(0)
a 6.0
b 8.0
c 0.0
d 0.0
e 0.0
f 0.0
dtype: float64
DataFrame 算术运算
df1=DataFrame(np.arange(9).reshape(3,3),
index=list('ABC'),
columns=list('abc'))
df2=DataFrame(np.arange(10,30).reshape(4,5),
index=list('BCDE'),
columns=list('axdef'))
df1
a b c
A 0 1 2
B 3 4 5
C 6 7 8
df2
a x d e f
B 10 11 12 13 14
C 15 16 17 18 19
D 20 21 22 23 24
E 25 26 27 28 29
df1+df2
a b c d e f x
A NaN NaN NaN NaN NaN NaN NaN
B 13.0 NaN NaN NaN NaN NaN NaN
C 21.0 NaN NaN NaN NaN NaN NaN
D NaN NaN NaN NaN NaN NaN NaN
E NaN NaN NaN NaN NaN NaN NaN
df1.add(df2,fill_value=xxx)
- 会在加之前 填充规则:行列组合,有一个值就填充,都没有的就不填充
df1.add(df2,fill_value=0)
a b c d e f x
A 0.0 1.0 2.0 NaN NaN NaN NaN
B 13.0 4.0 5.0 12.0 13.0 14.0 11.0
C 21.0 7.0 8.0 17.0 18.0 19.0 16.0
D 20.0 NaN NaN 22.0 23.0 24.0 21.0
E 25.0 NaN NaN 27.0 28.0 29.0 26.0
df1.add(df2,fill_value=0).fillna(0)
a b c d e f x
A 0.0 1.0 2.0 0.0 0.0 0.0 0.0
B 13.0 4.0 5.0 12.0 13.0 14.0 11.0
C 21.0 7.0 8.0 17.0 18.0 19.0 16.0
D 20.0 0.0 0.0 22.0 23.0 24.0 21.0
E 25.0 0.0 0.0 27.0 28.0 29.0 26.0
其他几个运算符的函数
- 减法
df1.sub(df2)
a b c d e f x
A NaN NaN NaN NaN NaN NaN NaN
B -7.0 NaN NaN NaN NaN NaN NaN
C -9.0 NaN NaN NaN NaN NaN NaN
D NaN NaN NaN NaN NaN NaN NaN
E NaN NaN NaN NaN NaN NaN NaN
- 乘法
df1.mul(df2)
a b c d e f x
A NaN NaN NaN NaN NaN NaN NaN
B 30.0 NaN NaN NaN NaN NaN NaN
C 90.0 NaN NaN NaN NaN NaN NaN
D NaN NaN NaN NaN NaN NaN NaN
E NaN NaN NaN NaN NaN NaN NaN
- 除法
df1.divide(df2)
a b c d e f x
A NaN NaN NaN NaN NaN NaN NaN
B 0.3 NaN NaN NaN NaN NaN NaN
C 0.4 NaN NaN NaN NaN NaN NaN
D NaN NaN NaN NaN NaN NaN NaN
E NaN NaN NaN NaN NaN NaN NaN
- 取模
df1.mod(df2)
a b c d e f x
A NaN NaN NaN NaN NaN NaN NaN
B 3.0 NaN NaN NaN NaN NaN NaN
C 6.0 NaN NaN NaN NaN NaN NaN
D NaN NaN NaN NaN NaN NaN NaN
E NaN NaN NaN NaN NaN NaN NaN
DataFrame 与 Series 运算
- df列 与 Series行索引匹配,能匹配上则运算,匹配不上则 nan
df1
a b c
A 0 1 2
B 3 4 5
C 6 7 8
s1
a 1
b 2
c 3
d 4
dtype: int64
df1.add(s1)
a b c d
A 1 3 5 NaN
B 4 6 8 NaN
C 7 9 11 NaN
df1.add(Series([10,20,30,40],index='one,two,three,c'.split(',')))
a b c one threetwo
A NaN NaN 42.0 NaN NaN NaN
B NaN NaN 45.0 NaN NaN NaN
C NaN NaN 48.0 NaN NaN NaN