YOLOv4: Optimal Speed and Accuracy of Object Detection
Paper:https://arxiv.org/abs/2004.10934 Code:https://github.com/AlexeyAB/darknet
论文题目是:最优速度和精度均衡的目标检测器;文章的主要工作是把神经网络中比较有用的一些涨点 方法综合到一起,做了很多丰富的实验,并组合得出精度和速度均衡的yolo-v4。主要包括下面几个方法:
- Weighted-Residual-Connections (WRC),
- Cross-Stage-Partial-connections (CSP),
- Cross mini-Batch Normalization (CmBN),
- Self-adversarial-training (SAT),
- Mish-activation,
值得注意的是,论文的sota:43.5% mAP for the MS COCO dataset at a realtime speed of ∼65 FPS on Tesla V100。 还结合了 Mosaic data augmentation, DropBlock regularization, CIoU loss的使用。从总体效果来看,本文的模型是检测实际应用的大杀器:

一.相关工作
- 作者首先把检测模型进行了拆解,从input,backbone,neck,dense prediction,sparse prediction几个部分,并融合检测模型的发展历史,将主流的paper思想分解到对应的模块中,通过示意图以及作者的对应划分,从而对检测模型的发展有一个大致的掌握:
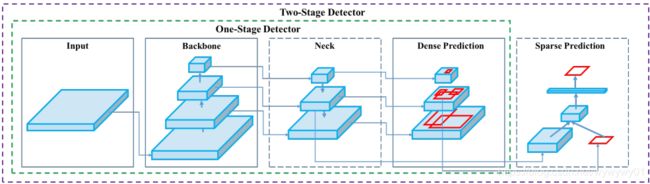
其中,对应各个模块,嵌入对应模型(竟然看到了好多陌生的模型,好惭愧。。。):

2.Bag of freebies
论文中定义“袋赠品”的概念表示一类模型:仅增加训练过程的代价或者改变训练的策略,来提升模型的性能,
主要分为三个方面内容:
(1)数据扩充;(2)数据集的语义分布偏差(例如类别不平衡问题);(3)BBox的回归损失函数演化。
(1)数据扩充
第一部分:像素级的变换,包括光度畸变(亮度,对比度,图像的色调、饱和度和噪声)和几何畸变(随机缩放、剪切、翻转和旋转);
第二部分:模拟物体遮挡问题,包括在原始图片和特征图进行区域的随机或者均匀擦除(随机插值)和断路(数值置0);
第三部分:融合不同图片进行扩充,Mixup--2张图片进行不同系数比相乘叠加(label进行对应调整),Cutmix:将裁剪的矩形区域图像覆盖到其他图片,并调整label;还有一类方法是使用GAN来生成不同风格的图片进行扩充(增加纹理不变性--通常风格反应在图片纹理上);
(2)数据集的语义分布偏差(例如类别不平衡问题,物体类别,难易样本平衡)
对于two-stage(通常是sparse prediction的)常用的解决类别不平衡方法在线难例挖掘和正样本难例挖掘等,但是这种方式不适用于dense prediction方式的one-stage检测方法,在one stage里面代表解决思路是focal loss;除此之外,label smoothing和soft label(KD)也可以通过label之间的关联来缓解不平衡问题;
(3)BBox的回归损失函数演化
bbox回归损失经历下面几个演进历程bbox的loss演进:
| 编号 | 方式 | 特点 |
| 1 | 原始的点对点的MSE loss方式 | 每个位置坐标独立计算loss,没有将物体作为一个整体进行回归 |
| 2 | IOU loss | (1)整体考虑物体框回归; (2)IOU loss计算具有尺度不变性,缓解L1和L2 loss可能随着尺度变化带来的loss偏差 |
| 3 | GIOU loss | 加入box的shape和朝向约束(例如IOU loss对于两个box没有重叠时没有梯度回传;以及不能反映box之间是如何相交的);形式:用IOU 减去(C/AUB)面积和C的比值,C为gt A和预测box B的外接矩形面积。 |
| 4 | DLOU loss | 当目标框在预测框内部时候,GIOU退化为IOU,因此作者在GIOU loss中加入了bbox中心点欧式距离的归一化约束;达到的效果:收敛精度高,收敛速度更快。 |
| 5 | CIOU loss | 在DIOU的基础上,加入gt box和预测box的长宽比约束; |
3.Bag of specials
论文作者很有意思的定义了第二个名词--“袋特价”,用来表示通过增加inference的代价,带来模型性能提升的方法;在文中主要总结了下面五个方面的内容:
(1)增大感受野;(2)注意力机制;(3)特征集成;(4)激活函数;(5)后处理(nms)。
(1)增大感受野
在这里主要介绍了SPP(空间金字塔池化,使用几组不同大小的卷积核在目标区域进行最大池化,保证不同大小的feature得到相同长度的特征向量表示,作为后续fc层的输入;这个方法起源于SPM--直接在特征图暴力划分block) ;yolov3论文中,由于原始SPP不能直接在全卷积网络中使用,因此对SPP进行了改进yolo-v3-spp,主要是使用不同大小的卷积核池化之后,继续添加卷积,是的不同感受野的特征能够concat到一起。
ASPP和yolov3中的SSP区别是,使用kernel size为3*3,膨胀率为k,stride为1的膨胀卷积(SPP是k*k卷积核,stride 1),替代池化操作。
RFB模块和ASPP的区别使用多个kernel sizek*k,膨胀率为k,stride为1的膨胀卷积(能够获取更全面的空间覆盖)。
(2)注意力机制
两种注意力方式,channel-wise attention and pointwise attention,各自的代表:SE 和SAM,SE 在gpu上会增加10%的inference的时间,更适合于移动端;SAM在SE基础上能够提升0.5%分类性能但几乎不增加inference time。
(3)特征集成
这一部分感觉翻译成特征融合更加合适,从原始的skip connection 和 hyper-column(表示没看过),到FPN(PAN),SFAM (利用SE模块对多尺度的拼接特征图进行信道级配重权), ASFF(使用softmax作为点向水平重加权,然后融合不同规模的特征图), BiFPN(提出多输入加权残差连接,执行逐级重加权,然后添加不同尺度的特征图)。
(4)激活函数
激活函数一般设计用来解决梯度消失问题--relu系列的可以根据relu的函数图和导数示意图,修改目标使两端的梯度达到预设目标;注意两个为定点网络的设计的:relu6 && hard-swish。此外,激活函数的选取除了考虑网络训练的梯度问题,更重要需要考虑工程实现的效率。激活函数近期
(5)后处理
主要是nms的相关工作,可以参考soft nms,DIOU nms,当然还有一些发展是文中没有提及的:softer nms,iou-net,
mask scoreing。
二.网络模型
作者针对运行平台给出两种网络选择达到效率的均衡:
(1)针对GPU,提供较小的组卷积(1~8),CSPResNeXt50 / CSPDarknet53;
(2)针对VPU(视觉处理单元?),则使用完全的组卷积,但是没有使用SE block;包括下面几个模型:EfficientNet-lite / MixNet / GhostNet / MobileNetV3。
1.主体架构
网络的选择主要考量几个因素:输入分辨率,卷积层数量,网络参数量(主要是卷积),输出层的数量等。在实验中,经验表明,CSPResNeXt50比CSPDarknet53的分类效果好,但是检测效果稍差。作者进一步指出了检测相较于分类任务:
- 需要更高的图片分辨率--有利于多尺度物体的检测
- 需要更多的层数--增加感受野cover住更大的输入网络,感受野--感受物体语义信息,感受上下文信息
- 需要更多的参数量--增加模型容量(单张图片多尺度多物体的检测,很复杂的)
特征融合
- 目的:增加感受野,特征加强聚集
- 主要方法:FPN,PAN,ASFF,BIFPN。
论文中给出了主要的三中架构的对比:

在基础架构(backbone)的基础上,进一步加入SPP 模块加大感受野(几乎不带来inference速度的损失),PaNet--融合特征,直接使用yolov3的head组成了yolo v4的架构。另外,所有实验均是单卡进行的,没有使用跨卡BN。
2.BOF && BOS
对于BOF和BOS中,主要参考下图:红线部分,PReLU和SELU难以训练,ReLU6主要为定点模型设计,因此不做考虑;黄色示意部分,DropBlock是性能高于其余部分的约束方法,CBN是 单卡上的迭代BN.

3.其他涨点姿势
作者加入其他的设计,主要为适应单卡的训练:
- 数据扩充:马赛克扩充(混合四幅图片,加入不同的纹理信息;cutmix只混合两张,这种设计一定程度加大了mini batch的bn统计量的样本);自对抗训练(训练过程分为两个阶段,以一个阶段bp不更新参数,而是更新图片数值,第二个阶段使用前一阶段的图片去做正常的训练)
- 超参数:使用遗传算法寻找最优超参数
- 修改现有模块:修改SAM, PAN, CBN
CBN修改示意图(每前向4次更新一次参数):

SAM修改示意图(通道级别-->点级别):

PAN修改(shortcut->concatenation)示意图:

4.yolo-v4
- yolo-v4基本组成:
- 消融实验模块
基本组成

消融模块

三.实验分析
实验主要包括在ImageNet的分类任务,COCO 2017的test-dev任务,主要结论:
- CSPResNeXt-50相较于CSPDarknet-53更适合分类任务,Mish操作涨1个点,作用突出;
- BOS实验,CSPResNeXt50-PANet-SPP-SAM 组合在检测任务性能最好:mAP42.7%;BOF消融实验:

- 分类和检测任务有各自适应特点模型,选对了backbone后续的BOS or BOF效果更好;
- 不同 的mini batch差距不大(CmBN中几次前向一次后向)。
实验设置细节
| training steps | 800万 |
| batch size && mini batchsize | 128 && 32 |
| 多项式延迟学习率策略 | 初始学习率:0.1;warm-up step:1000 |
| momentum &&weight decay | 0.9 && 0.005 |
| BoS experiments | (1)使用上述相同的超参; (2)LReLU, Swish, and Mish activation function. |
| BoF experiments | (1)增加50% 训练的step; (2)MixUp, CutMix, Mosaic, Bluring data augmentation, and |
| training steps | 500,500 |
| batch size && mini batchsize | 64&& 8 or 4,多尺度训练,动态bn时候,可以适当增大网络输入 |
| step延迟学习率策略 | 初始学习率:0.01;factor:0.1; 【400,000;450,000】分别decay |
| momentum &&weight decay | 0.9 && 0.0005 |
| 遗传算法搜索实验 | 基于YOLOv3-SPP ,GIoU loss 训练300 epochs 在min-val 5k 数个数据集上;learning rate 0.00261, momentum 0.949, IoU threshold for assigning ground truth 0.213, and loss normalizer 0.07 |
| BoS experiments |
Mish, SPP, SAM, RFB, BiFPN, and Gaussian YOLO |
| BoF experiments | grid sensitivity elimination, mosaic data augmentation, IoU threshold, genetic algorithm, cross mini-batch normalization, selfadversarial training, cosine annealing scheduler, dynamic mini-batch size, DropBlock, Optimized Anchors, different kind of IoU losses |