pandas部分函数简单介绍
在对数据做预处理的时候用到了pandas,整理一些用到的函数,以后查看方便。初次使用给我的感觉就是pandas是用来处理表格数据的一个工具包,尤其是对csv格式的数据。它基于DataFrame和Series两种数据类型。
1.数据读入
假设被读取的文本名为train_labels_100.csv内容如下所示:
filename,width,height,class,xmin,ymin,xmax,ymax
1IMG20180906142057.jpg,1000,1777,cat,225,503,385,658
1IMG20180906142057.jpg,1000,1777,cat,450,420,569,543
1IMG20180906142057.jpg,1000,1777,cat,563,445,681,563
20180906152036.jpg,1000,1333,cat,206,420,326,515
20180906152036.jpg,1000,1333,cat,280,408,390,516
20180906152036.jpg,1000,1333,cat,616,815,686,894
20180906152036.jpg,1000,1333,cat,652,785,693,832
20180906151027.jpg,1000,1333,cat,1088,757,1174,843
20180906151027.jpg,1000,1333,cat,1047,813,1126,892
20180906151027.jpg,1000,1333,cat,1021,911,1065,954
20180906151027.jpg,1000,1333,cat,991,871,1028,907
20180906151027.jpg,1000,1333,cat,949,922,992,964
读文件代码:
import pandas as pd
examples = pd.read_csv(‘train_labels_100.csv’)
其中,examples是DataFrame类型(我管这个叫数据框),DataFrame是一个二维的,表格型的数据结构,从csv读取的数据都会放在它里面。
2.数据查看
当导入数据完成后,有强迫症的小伙伴总想查看下读入的数据长什么样子,或者对不对。用print(examples)就能查看读入的全部数据,但是当数据量很大的时候在终端中全部显示很难看。可以采用print(examples.head(3))仅查看前三行,如下图所示,head()是按数据原来的顺序获取前几行,同样tail()是按顺序获取最后几行,len(examples)可以获取总行数。

3.行、列访问、筛选记录
在此,我把每一行就做一个记录,有时候我们只需要查看某些行、列,或者对记录进行筛选。当筛选列的时候,采用列表前就可以,如获取height这一列,代码如下:
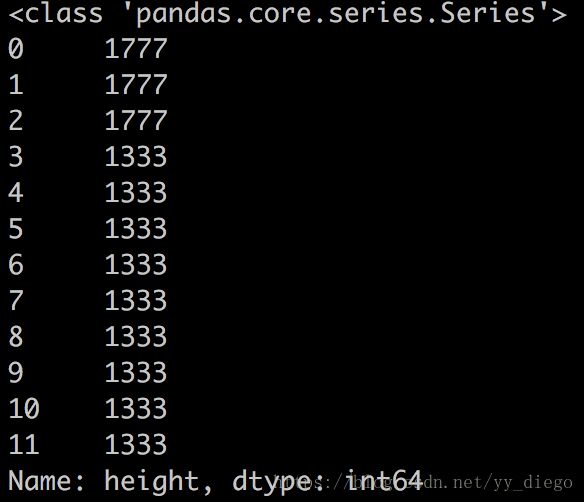
#获取height列
hg = examples['height']
print(type(hg))
print(hg)
结果如下,hg是Series类型的,这是一种一维的数据类型。
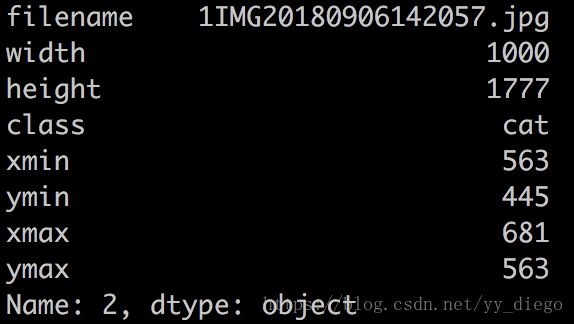
可以采用loc[index]函数对行进行访问,index就是每一行的索引,在最左边。比如访问index=2的那行数据,代码如下:
row = examples.loc[2]
print(row)
结果如下:
代码hg = examples[examples['height']<1777]可以实现筛选,结果如下:
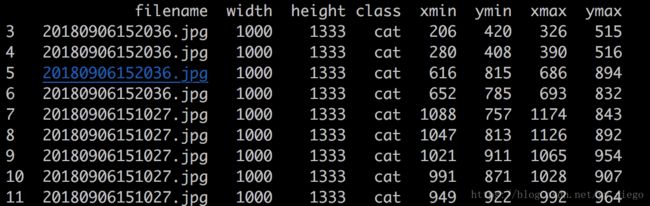
当需要筛选出满足条件的记录时,比如,我们要找出height>1333的所有记录,可以使用如下代码:
row = examples.loc[examples['height']>1333]
print(row)
结果如下:若有多个筛选条件,可以使用&符号,如examples.loc[(examples['height']>1333)&(examples['height']>1333)]

3.分组
groupby 会按照你选择的列对数据集进行分组。代码如下:
#按照filename这个列标签进行分组
gb = examples.groupby("filename")
print('------- gb.size()-------')
#获取每组有多少条记录
print(gb.size())
print('------- gb.get_group()-------')
#查看20180906152036.jpg这一组的记录
print(gb.get_group('20180906152036.jpg'))
print('------- gb.groups.keys()-------')
#获取每组的key(每组的标志)
print(gb.groups.keys())
#获取所有组的信息
print('------- gb.groups-------')
print(gb.groups)
结果如下:

我知识整理了部分函数的功能,其他的函数可以参考下面两个链接:
https://ithelp.ithome.com.tw/articles/10194027
http://codingpy.com/article/a-quick-intro-to-pandas/