OpenCV:图像检索
OpenCV可以检测图像的主要特征,然后提取图像的特征,使其成为图像描述符。
这些图像特征,也就是图像描述符,可以作为图像搜索的数据库。
个人感觉就是,和「以图搜图」有点像。

看了下面这个视频,或许你就能够明白了。
https://v.qq.com/x/page/y0880pe6kdc.html
也是一个很搞笑的片段...
/ 01 / 特征检测算法
这里简单介绍一下OpenCV常用的几种特征检测和提取算法。
Harris、FAST:用于检测角点的。
SIFT、SURF、BRIEF:用于检测斑点的。
ORB:FAST算法和BRIEF算法的结合体。
检测和提取的工作做完了,就是特征匹配。
主要是「暴力匹配法」和「FLANN匹配法」。
提了好几次特征了,那么什么是图像的特征呢?
图像特征就是指有意义的图像区域,具有独特性或易于识别性,比如角点、斑点以及高密度区。
角点可以通过OpenCV的cornerHarris来识别。
「SIFT」则是一种与图像比例无关的角点检测方法,尺度不变特征变换。
采用DoG和SIFT来检测关键点并提取关键点周围的特征。
「SURF」特征检测算法,则是采用Hessian算法检测关键点,使用SURF提取特征。
剩下的太难了,以后慢慢了解~
/ 02 / 图像检索
N匹配,近似最近邻的快速库。
原始图片如下,为微博的Logo。

目标图片如下,包含新浪微博的名称。

代码如下。
import cv2
good = []
# 原始图片
queryImage = cv2.imread('wb1.jpg', 0)
# 目标图片
trainingImage = cv2.imread('wb2.jpg', 0)
# 创建SIFT对象(特征检测器),并计算灰度图像(描述符)
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(queryImage, None)
kp2, des2 = sift.detectAndCompute(trainingImage, None)
# 设置FLANN匹配器参数
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
searchParams = dict(checks=50)
# FLANN匹配器
flann = cv2.FlannBasedMatcher(indexParams, searchParams)
# K-最近邻匹配
matches = flann.knnMatch(des1, des2, k=2)
# 绘制一个空白图片
matchesMask = [[0, 0] for i in range(len(matches))]
# 绘制图像
for i, (m, n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i] = [1, 0]
good.append(m)
# 图像参数
drawParams = dict(matchColor=(0, 255, 0),
singlePointColor=(255, 0, 0),
matchesMask=matchesMask,
flags=0)
# 最终结果
resultImage = cv2.drawMatchesKnn(queryImage, kp1, trainingImage, kp2, matches, None, **drawParams)
# 检测是否匹配
if len(good) > 10:
print('It is a match!')
# 设置显示窗口
cv2.namedWindow('img', 0)
cv2.resizeWindow('img', 840, 480)
cv2.imshow('img', resultImage)
while True:
if cv2.waitKey(0) & 0xff == ord('q'):
break
cv2.destroyAllWindows()
输出下图。
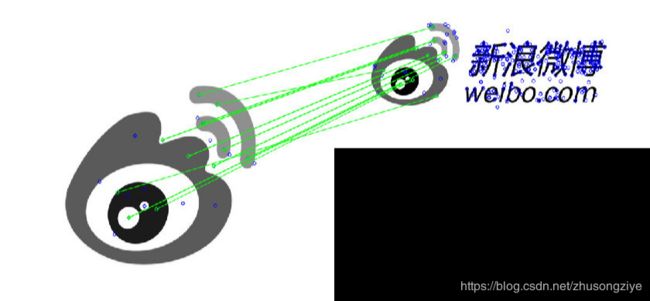
可以看到原始图片上的logo和目标图片上的logo匹配上了。
也就意味着,我们能够利用原始图片(微博logo)从一个包含目标图片的图片库里检索到目标图片(包含微博logo)。
以图搜图,这还是很相似的。
当然,我并不知道以图搜图到底是通过何种办法实现的。
毕竟弱鸡~
/ 03 / 总结
最开头放的视频是一部电影——疯狂的外星人。