【R-CNN系列目标检测】(4)FASTER R-CNN算法
重点参考《【目标检测】Faster RCNN算法详解》、《faster-rcnn 之 RPN网络的结构解析》
faster r-cnn【1】是Ross Girshick对 fast r-cnn 算法的改进。简单网络(ZF)目标检测速度达到17fps,在PASCAL VOC上准确率为59.9%;复杂网络(VGG-16)达到5fps,准确率78.8%。
算法思路
从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
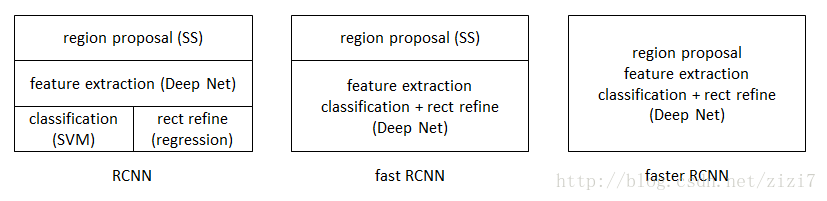
图1. rcnn -> fast r-cnn -> faster r-cnn
faster RCNN可以简单地看做“区域生成网络RPN+fast RCNN“的系统,用RPN代替fast RCNN中的Selective Search方法。本篇论文着重解决了这个系统中的三个问题:
1. 如何设计区域生成网络
2. 如何训练区域生成网络
3. 如何让区域生成网络和fast RCNN网络共享特征提取网络
RPN网络结构
该部分实现提取特征图,并对可能的候选框做判别和位置精调
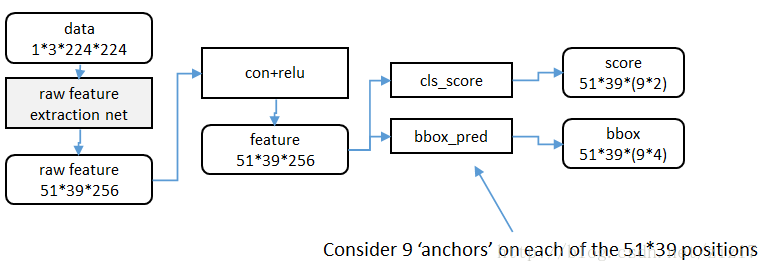
图2. RPN网络结构
特征提取
使用ImageNet上常见的网络(5层的ZF、16层的VGG-16),后面跟一个 卷积+ReLU层 将特征归为256维
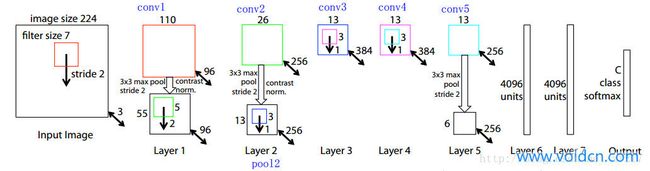
图3. ZF网络结构
如图3,以ZF为例。输入是 224*224*3,conv1卷积核大小为 7*7*3*96(7*7为核的长宽,3为像素维度,需要与上一层输出一致,96为卷积核的数目),这样输出为 110*110*96。最终取conv5的输出(13*13*256)
RPN区域生成
首先使用 3*3 的滑动窗口将 conv5 的输出卷积为256维的向量(卷积核大小为 3*3*256*256)
然后对每个位置,考虑 k=9个可能的候选窗口:3种面积 x 3种比例(1:1, 1:2, 2:1)
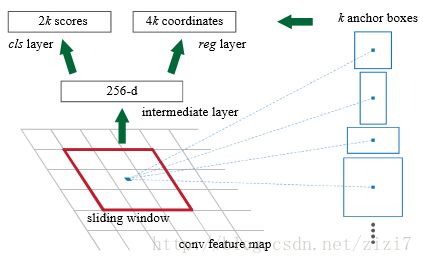
图4. RPN区域生成
cls layer 判断每个候选区域为前景还是背景,一共2*9=18个输出(使用 1*1*256*18的卷积核)
reg layer 输出相对于每个候选区域的缩放平移参数,一共4*9=36个输出(使用 1*1*256*36的卷积核)
这里有RPN网络代码的分析
faster r-cnn 网络训练
1)数据准备:
a. 对每个标定的真值候选区域,与其重叠比例最大的anchor记为前景样本
b. 对a)剩余的anchor,如果其与某个标定重叠比例大于0.7,记为前景样本;如果其与任意一个标定的重叠比例都小于0.3,记为背景样本
c. 对a),b)剩余的anchor,弃去不用
d. 跨越图像边界的anchor弃去不用
2)训练
这里的难点在于如何让两个网络(RPN和fast r-cnn)共享参数
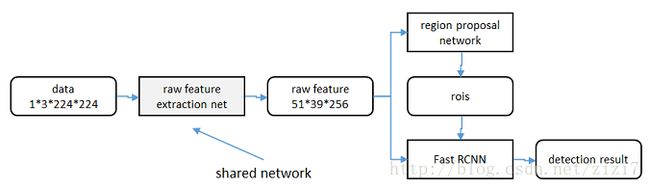
图5. faster r-cnn网络
文章介绍了3种方法,作者的代码里包含了第4种方法:
a. 轮流训练
首先从已经在ImageNet上训练过的模型开始,训练RPN;
然后以RPN的输出来训练 fast r-cnn;
不断重复
b. 近似联合训练
直接在图5上训练,反向计算梯度时,把提取的ROI当作固定值看。
该方法与上一种效果差不多,但训练时间能减少20%-25%
c. 联合训练
直接在图5上训练,反向计算梯度时,考虑ROI变化的影响
d. 4步轮流训练
首先用ImageNet初始化的网络独立训练一个RPN;
仍然用通过ImageNet初始化,但proposal以上一步RPN的输出为输入,训练一个 fast r-cnn;
使用上面的fast r-cnn训练一个新的RPN,但不更新 RPN与fast r-cnn共有的卷积层(相应的learning rate设为0);
添加进fast r-cnn一起训练,仍然不更新共有的卷积层
代码实现
Girshick在github上开源了该算法的python代码
文章《r-cnn系列代码编译及解读(2)》记录了代码的安装配置方法,以及使用自己的数据做训练和测试
参考文献
【1】 Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 39(6):1137.