强化学习系列之OpenAI的入门
学习强化学习,从翻译OpenAI的教学文章开始,有意愿加入的童鞋请联系我!
强化学习系列文章
第一章 强化学习入门
第二章 翻译OpenAI用户手册(一)
第三章 翻译OpenAI用户手册(二)
第四章 翻译OpenAI用户手册(三)
目录
1.简介
2.Gym游戏环境的安装
3.Gym所含的游戏
3.1 打砖块 Breakout-v0或Breakout-v4
3.2 倒立摆游戏 CartPole-v0或CartPole-v1
3.3 小车翻沟游戏
3.4 火箭降落小游戏LunarLander-v2
3.5 所有支持的游戏如下
1.简介
安装Pycharm:https://www.shuopython.com/archives/2339
OpenAI的官网地址:https://www.openai.com/
OpenAI教学网址:https://spinningup.openai.com/en/latest/
OpenAI的强化学习源代码:https://github.com/openai/baselines

图1 2019年7月OpenAI团队和他们的合作伙伴的户外合照
大事记:


2.Gym游戏环境的安装
超简单,直接pip install gym
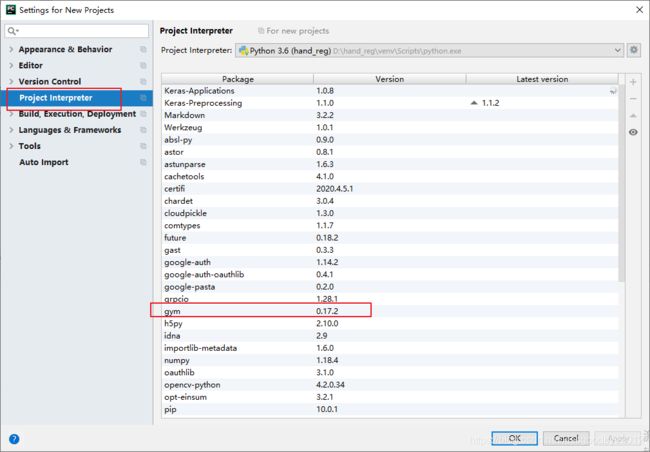
我是用pycharm,所以在project interpreter中安装了gym。整个安装过程没有遇到bug。
验证运行的代码:
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break运行如下画面:

3.Gym所含的游戏
从gym的安装目录下envs即可看出有哪些游戏,里面的py程序可以直接运行。听说还有各个游戏的排行榜,不知道在哪看。
Gym包含游戏的查看网址:https://gym.openai.com/envs/#classic_control

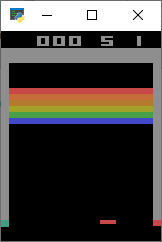
3.1 打砖块 Breakout-v0或Breakout-v4
第一步:安装
pip3 install keyboard
pip3 install atari-py第二步:开始玩游戏
import gym
import keyboard
import numpy as np
import time
total_reward = 0
env = gym.make('Breakout-v0')
state = env.reset()
action = 0
def preprocess(img):
img_temp = img.mean(axis = 2)
x = -1
y = -1
if len(np.where((img_temp[100:189,8:152])!= 0)[0]) != 0:
x = np.where((img_temp[100:189,8:152])!= 0)[0][0]
y = np.where((img_temp[100:189,8:152])!= 0)[1][0]
if len(np.where((img_temp[193:,8:152])!= 0)[0]) != 0:
x = -2
y = -2
p = int(np.where(img_temp[191:193,8:152])[1].mean() - 7.5)
#return img_temp
return (x,y,p)
# 实际按键中只检测0,1,2,3 游戏中需要的按键
# 我添加了一个按键4,用于暂停
def abc(x):
global action
if x.event_type == "down" and x.name == '0':
action = 0
elif x.event_type == "down" and x.name == '1':#发球
action = 1
elif x.event_type == "down" and x.name == '2':#左移
action = 3
elif x.event_type == "down" and x.name == '3':#右移
action = 2
elif x.event_type == "down" and (action == 4 or x.name == '4'):
action = 4
elif action != 4:
action = 0
# 添加hook,以检测用户的按键
keyboard.hook(abc)
total_reward = 0
for j in range(1000):
env.render()
while action == 4:
time.sleep(0.1)
if action == 4:
action = 0
next_state,reward,done,_ = env.step(action)
total_reward += reward
(x2,y2,p2) = preprocess(next_state)
print(action,total_reward,done,x2,y2,p2)
time.sleep(0.1)
if done:
break
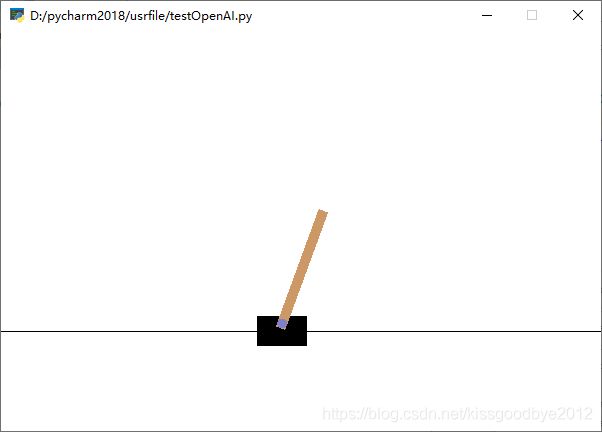
keyboard.wait()3.2 倒立摆游戏 CartPole-v0或CartPole-v1
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()3.3 小车翻沟游戏
## 基于强化学习实现小车自适应翻越小沟
import gym
import time
class BespokeAgent:
def __init__(self, env):
pass
def decide(self, observation):
position, velocity = observation
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03, 0.3 * (position + 0.9) ** 4 - 0.008)
ub = -0.07 * (position + 0.38) ** 2 + 0.06
if lb < velocity < ub:
action = 2
else:
action = 0
return action # 返回动作
def learn(self, *args): # 学习
pass
def play_ones(self, env, agent, render=False, train=False):
episode_reward = 0 # 记录回合总奖励,初始值为0
observation = env.reset() # 重置游戏环境,开始新回合
while True: # 不断循环,直到回合结束
if render: # 判断是否显示
env.render() # 显示图形界面,可以用env.close()关闭
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action) # 执行动作
episode_reward += reward # 搜集回合奖励
if train: # 判断是否训练智能体
break
observation = next_observation
return episode_reward # 返回回合总奖励
if __name__ == '__main__':
env = gym.make('MountainCar-v0')
env.seed(0) # 设置随机数种子,只是为了让结果可以精确复现,一般情况下可以删除
agent = BespokeAgent(env)
for _ in range(100):
episode_reward = agent.play_ones(env, agent, render=True)
print('回合奖励={}'.format(episode_reward))
time.sleep(10) # 停顿10s
env.close() # 关闭图形化界面3.4 火箭降落小游戏LunarLander-v2

第一步,安装box2d
pip install box2d第二步,开始玩
import gym
env = gym.make('LunarLander-v2')
# print env.observation_space
# print env.action_space
for i_episode in range(100):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t + 1))
break3.5 所有支持的游戏如下
https://blog.csdn.net/weixin_39059031/article/details/82143526?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159783587919724848344350%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159783587919724848344350&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v3~pc_rank_v2-1-82143526.first_rank_ecpm_v3_pc_rank_v2&utm_term=gym+%E6%89%80%E6%9C%89%E6%B8%B8%E6%88%8F&spm=1018.2118.3001.4187
让AI先在人类的操作下学习,然后再自行学习,效果会不会好点???