sk-learn模型选择与评估学习笔记
文档思维导图:
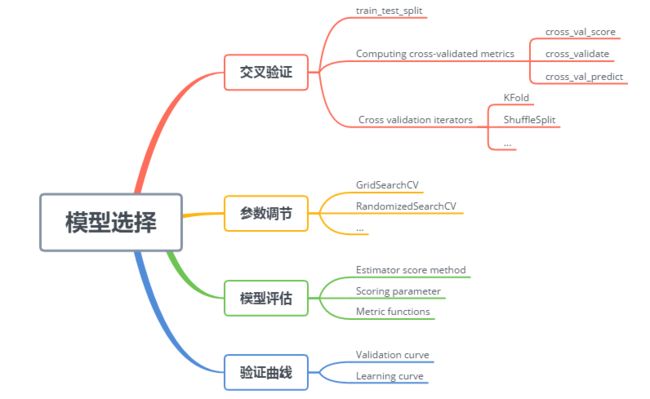
交叉验证
train_test_split: 分裂训练数据。
X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.4, random_state=0)
Computing cross-validated metrics: 交叉验证评估。主要方法有cross_val_score ,cross_validate ,cross_val_predict 。使用范例如下:
scores = cross_val_score(clf, iris.data, iris.target, cv=5) # scores = cross_validate(clf, iris.data, iris.target, scoring=scoring, cv=5, return_train_score=False) # 与cross_val_score有区别,scoring可以为多个评估标准... # cross_val_predict returns an array of the same size as `y` where each entry # is a prediction obtained by cross validation # 不是一个scores predicted = cross_val_predict(lr, boston.data, y, cv=10)
Cross validation iterators: 交叉验证迭代。产生能用于数据集分裂的索引。可作为参数 传递给cv,可以分裂数据集。
# ShuffleSplit使用范例 X = np.arange(5) ss = ShuffleSplit(n_splits=3, test_size=0.25,random_state=0) for train_index, test_index in ss.split(X): print("%s %s" % (train_index, test_index))
模型评估
Estimator score method: 各种算法自带的模型评估指标。如sklearn.tree.DecisionTreeClassifier 对象带有score(X, y, sample_weight=None) 函数。
(x为测试样本,y为真lables。返回平均准确率)
Scoring parameter:
一些内置性能度量函数具有名字 ,可以直接作为参数传递给
model_selection.GridSearchCV和model_selection.cross_val_score函数。
clf = svm.SVC(probability=True, random_state=0) cross_val_score(clf, X, y, scoring='neg_log_loss')
通过
make_scorer构建自己的性能指标,该函数将函数转换为模型评估的callables。make_scorer返回值可作为参数也可作为函数。
cross_val_score(clf, X, y, scoring=make_scorer()) # 作为参数 loss(clf, ground_truth, predictions) # 作为函数, clf为模型
使用情况:
(1) 一些内置性能度量函数没提供名字供参数使用。
ftwo_scorer = make_scorer(fbeta_score, beta=2)(2) 自己定义性能度量函数
def my_custom_loss_func(ground_truth, predictions): diff = np.abs(ground_truth - predictions).max() return np.log(1 + diff) loss = make_scorer(my_custom_loss_func, greater_is_better=False)
Metric functions:自带性能度量函数,通过真实值与预测值来计算,如f1_score :
sklearn.metrics.f1_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None) # 函数原型 f1_score(y_true, y_pred, average=None) # 调用
验证曲线
泛化误差由偏差 、方差、噪声误差组成
偏差过大:模型复杂度不高,欠拟合。加大模型复杂度
方差过大:学习程度过深,模型过于复杂,过拟合。增加训练数据,降低模型复杂度。
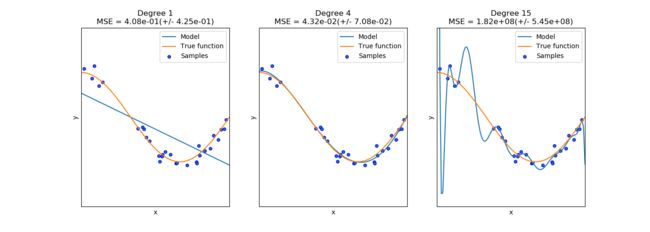
第一个高偏差,第三个高方差
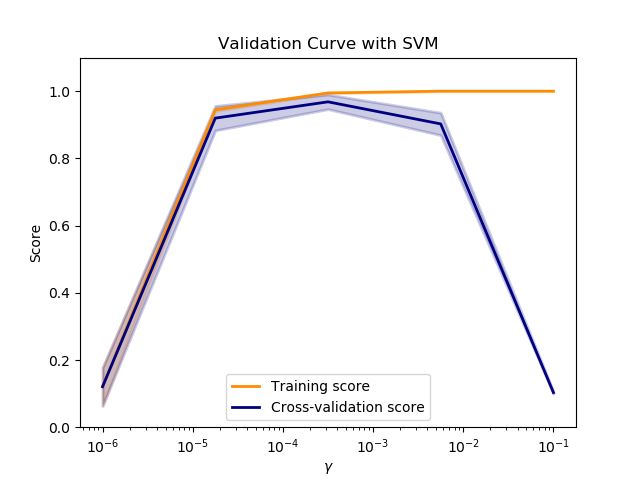
Validation curve: 验证曲线,横坐标为参数大小。通过该曲线可以选择合适的参数。
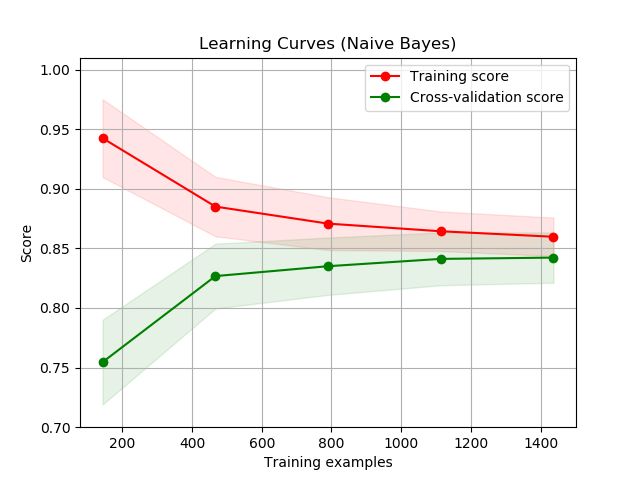
Learning curve: 学习曲线。横坐标是训练样本数量。通过观察曲线,验证数据集的大小是否有利于模型质量提高,可以观察是否存在高偏差,高方差。
参数调节
自动调节参数配置,使模型最优化。机器学习 sk-learn