Python每日一练(21)-抓取异步数据
目录
- 1. 异步加载与AJAX
- 2. 基本原理
- 2.1 发送请求
- 2.2 解析响应
- 2.3 渲染页面
- 2.4 Flask框架模拟实现异步加载页面
- 3. 逆向工程
- 4. 项目实战:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
在 Python每日一练(15)-爬取网页中动态加载的数据 一文中笔者已经讲过如何爬取动态加载的数据,本文在对其进行详细的讲解。在我们平时浏览网页的过程中,可以发现有很多网站显示在页面上的数据并不是一次性从服务端获取的,有一些网站,如图像搜索网站,当滚动条向下拉时,会随着滚动条向下移动,有更多的图片显示出来。其实这些图片都是通过异步的方式不断从服务端获取的,这就是异步数据,如京东。
1. 异步加载与AJAX
传统的网页如果要更新动态的内容,必须重新加载整个网页,因为不管是动态内容,还是静态内容,都是通过服务端以同步的方式按顺序发送给客户端的,一旦某些动态内容出现异常,如死循环,或完成非常耗时的操作,就会导致页面加载非常缓慢,即使动态部分不发生异常,如果动态部分的内容非常多,也会出现页面加载缓慢的现象,尤其是在网速不快的地方,非常让人抓狂。为了解决这个问题,有人提出了异步加载解决方案,也就是让静态部分(HTML、CSS、JavaScript等)先以同步的方式装载,然后动态的部分再另外向服务端发送一个或多个异步请求,从服务端接收到数据后,再将数据显示在页面上。这种技术就是常说的 AJAX,英文全称是 Asynchronous JavaScript and XML,中文可以称为 异步JavaScript和XML。

其实 AJAX 有两层含义,一层含义是异步(Asynchronous),这是指请求和下载数据的方式是异步的,也就是不占用主线程,即使加载数据缓慢,也不会出现页面卡顿的现象,顶多是该内容没显示出来(不过可以用默认数据填充),另一层含义是指传输数据的格式,AJAX 刚出现时,习惯使用 XML 格式进行数据传输,不过现在已经很少有人使用 XML 格式进行数据传输,因为 XML 格式会出现很多数据冗余,目前经常使用的数据传输格式是 JSON。不过由于 AJAX 的名字已经广为人知,所以一直沿用。
2. 基本原理
AJAX 的实现分为3步:
- 发送请求(通常是指HTTP请求)
- 解析响应(通常是指JSON格式的数据)
- 渲染页面(通常是指将JSON格式的数据显示在Web页面的某些元素上)。
2.1 发送请求
为了考虑浏览器的兼容性,建议使用 jQuery 发送请求,因为 jQuery 已经考虑到了不同浏览器平台的差异性。jQuery 是用 JavaScript 编写的函数库,可以到 官网 进行下载。使用方法如下:
<script src="./jquery-3.5.1.js">script>
<script>
$.get('/service', function (result) {
console.log(result)
});
script>
发送请求是异步的,所以需要通过第2个参数指定回调函数,一旦服务端返回响应数据,可以通过回调函数的参数 (result) 获取响应。通常在这个回调函数中利用服务端返回的数据渲染页面。
2.2 解析响应
这里的响应数据主要是指 JSON 格式的数据。可以使用下面的代码将字符串形式的数据转换为 JavaScript 对象形式的 JSON 数据。
JSON.parse(result)
其中 result 是 get 函数的回调函数的参数。得到JavaScript 对象形式的 JSON 数据,就可以任意访问数据了。
2.3 渲染页面
渲染页面主要是指将从服务端获取的响应数据以某种形式显示在Web页面的某些元素上,如下面的代码将数据以 li 节点的形式添加到 ul 节点的后面。
$('#practice_list').append('' + data[i].name + '')
其中 practice_list 是 ul 节点的 id 属性值,data 是 JSON 对象。append 函数用于将 HTML 代码追加到 practice_list 指定节点的内部 HTML 代码的最后。
2.4 Flask框架模拟实现异步加载页面
本例使用 Flask 框架模拟实现一个异步加载的页面。页面使用模板显示,并且通过 jQuery 向服务端发送请求,获取数据后,将数据显示在页面上。目录结构如下:
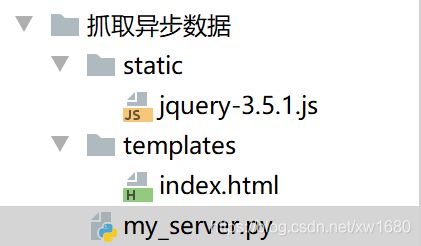
按照本文之前提到过的方式下载 jQuery 文件,然后将其复制到当前目录下的 static 子目录中。然后新建一个静态页面 (index.html) ,并将该页面放在当前目录的 templates 子目录下,作为 Flask 的模板文件。index.html 中的代码如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>异步加载页面title>
head>
<body>
<h2>阿莫的Python每日一练h2>
<ul id="practice_list">
<li>Python每日一练(20)-用Python制作mini翻译器li>
<li>Python每日一练(19)-通过爬虫实现GitHub网页的模拟登录li>
<li>Python每日一练(18)-抓取小说目录和全文li>
<li>Python每日一练(17)-通过正则表达式快速获取电影的下载地址li>
ul>
body>
html>
<script src="../static/jquery-3.5.1.js">script>
<script>
$(document).ready(function () {
//使用get函数向服务端发送请求
$.get('/data', function (result) {
// 将字符串形式的JSON数据转换为JSON对象(其实是一个JSON数组)
data = JSON.parse(result)
// 对JSON数组进行迭代 然后将每一个元素的name属性值作为li节点的内容
// 添加到 ul节点的最后
for (let i = 0; i < data.length; i++) {
$('#practice_list').append(`${data[i].name}`)
}
});
});
script>
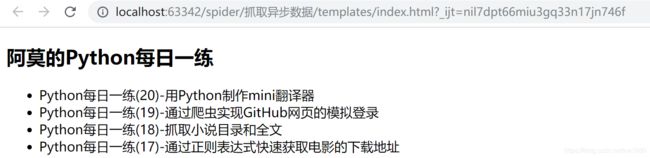
在 index.html 页面中,先放置一些静态的内容,主要是1个 h2 节点和带4个 li 节点的 ul 节点。如果直接在浏览器中显示 index.html 页面,如下图所示:
现在使用 Flask 实现 Web 服务,该服务通过根路由显示 index.html 的内容,使用 /data 响应路由客户端的请求。代码如下:
from flask import Flask, render_template
from flask import make_response
import json
app = Flask(__name__, static_folder='static', template_folder='templates')
# 根路由 用于显示index.html页面
@app.route('/')
def index():
return render_template('index.html')
# 响应客户端请求的路由
@app.route('/data')
def data():
# 定义要返回的四个数据(包含4个字典的列表)
data = [
{'id': 1, 'name': 'Python每日一练(16)-使用urlretrieve实现直接远程下载图片'},
{'id': 2, 'name': 'Python每日一练(15)-爬取网页中动态加载的数据'},
{'id': 3, 'name': 'Python每日一练(14)-一行代码实现各种功能'},
{'id': 4, 'name': 'Python每日一练(13)-IQ智商判断及测试'}
]
# 将data列表转换为JSON格式的字符串 然后创建响应对象
response = make_response(json.dumps(data))
# 返回响应
return response
if __name__ == '__main__':
app.run(debug=True)
Web 服务通过 /data 路由返回4组数据,这也就意味着 Web 页面会动态显示这4组数据。现在运行 my_server 服务,在浏览器中输入 http://127.0.0.1:5000/ 访问 index.html ,会看到如下效果:
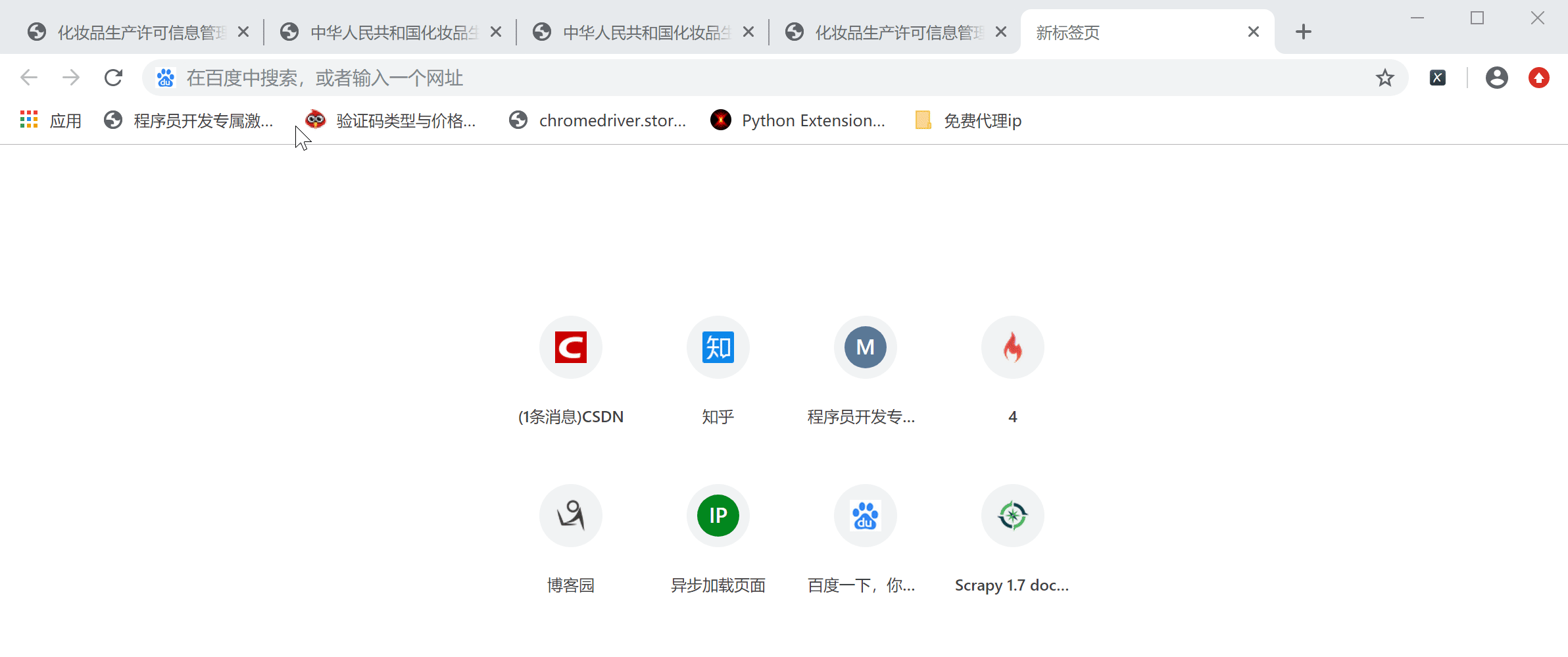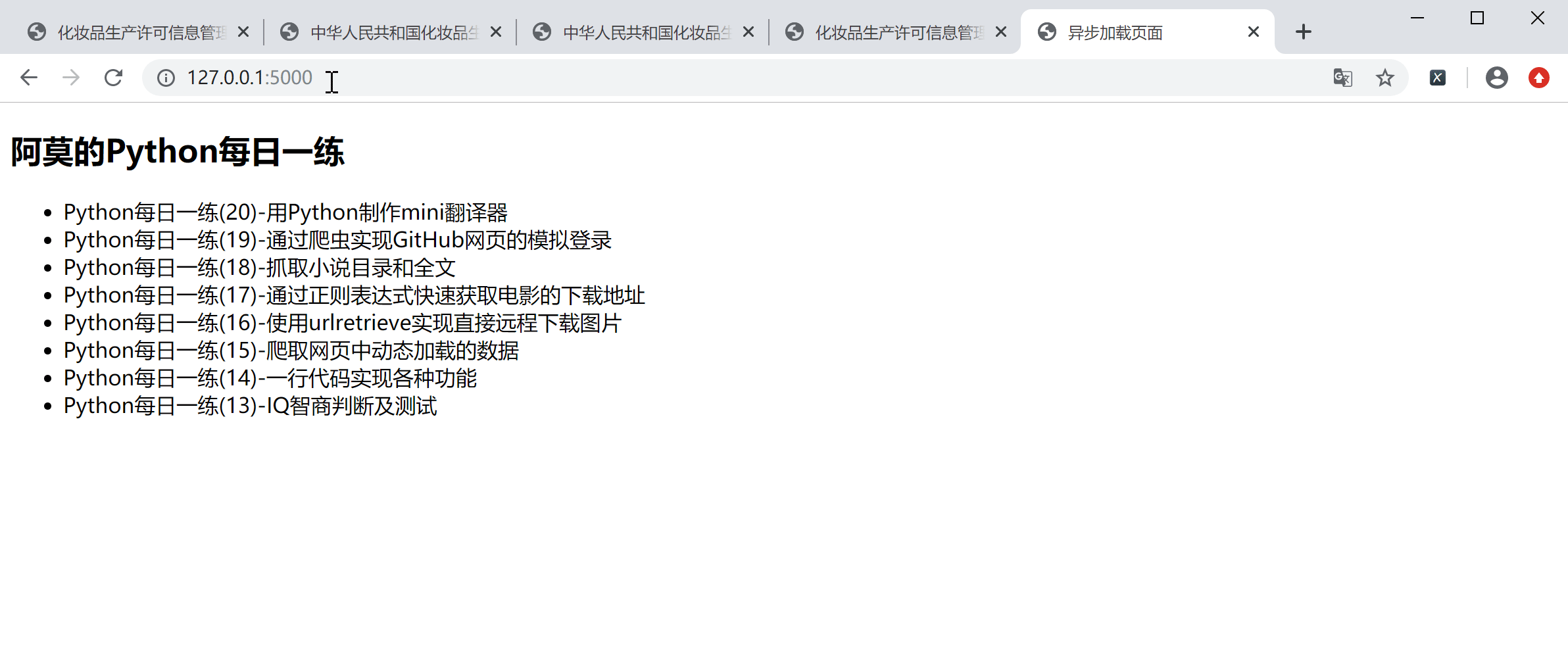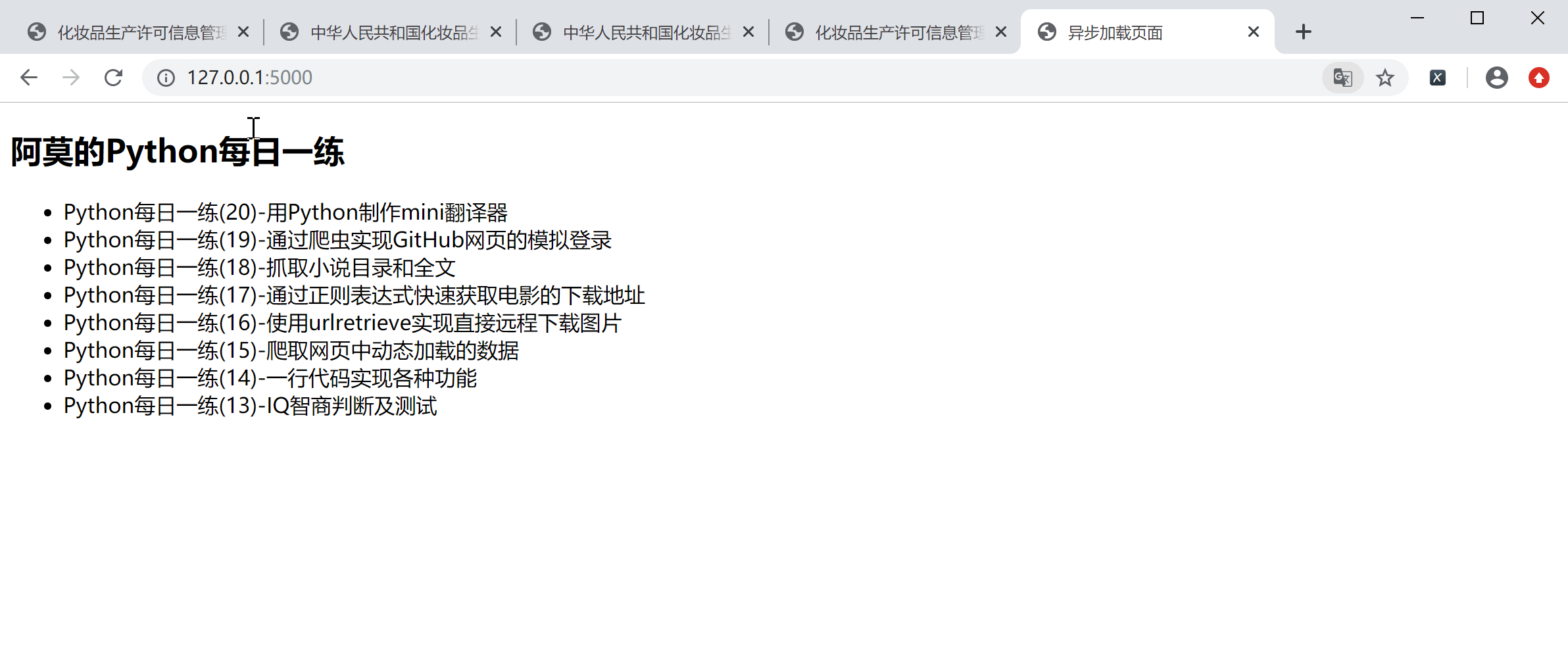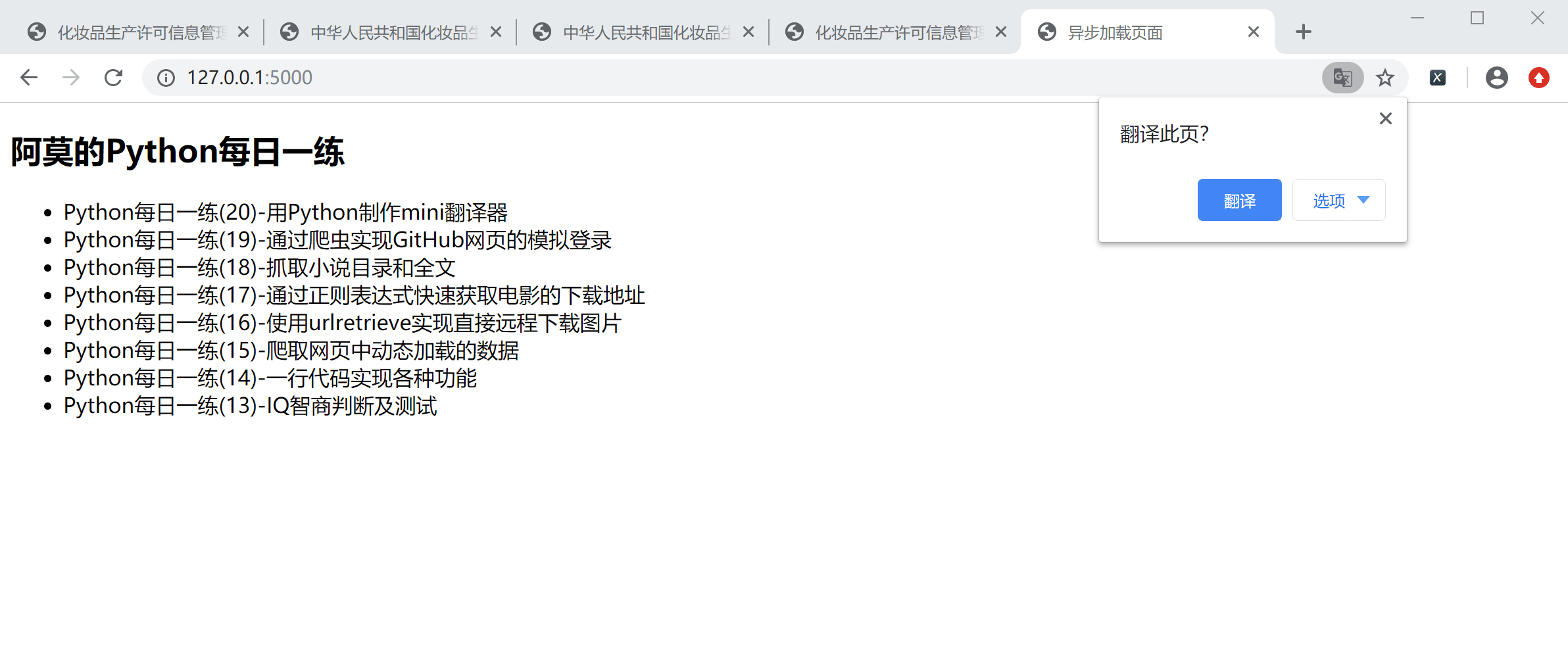
如果是第1次加载页面,会发现后4个列表项显示有一些延迟,这就充分说明,后4个列表项是通过异步方式加载的(录制的gif可能看着不太明显),再次刷新网页的时候有闪动效果。
3. 逆向工程
在上面已经模拟实现了一个异步装载的页面,这里以这个程序为例进行分析,如果对这个程序的实现原理不了解,那么应该如何得知当前页面的数据是异步加载的呢?以及如何获取异步请求的 URL 呢?
这就和破解一个可执行程序一样,需要用二进制编辑工具一点一点跟踪,这种方式被称为 逆向工程。现在来分析这个异步加载的页面。首先用 Chrome 浏览器打开这个页面,然后在开发者工具中定位到练习列表,如下图所示。
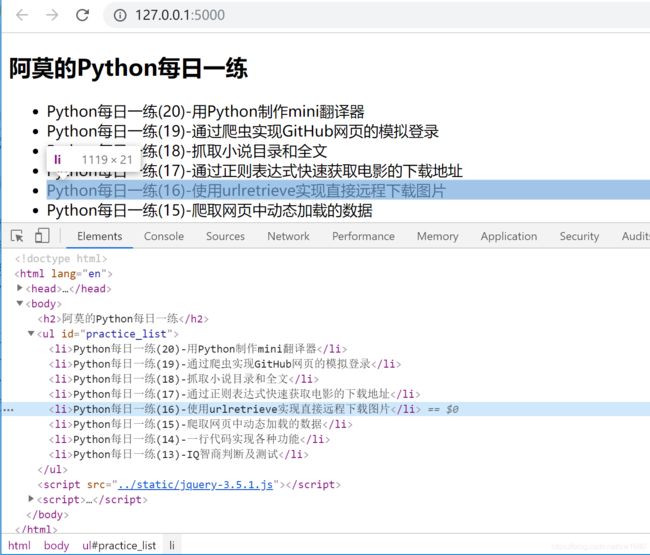
从 Elements 选项卡的代码发现,所有8个列表都实现出来了,赶紧使用网络库和分析库抓取和提取数据,代码如下:
import requests
from lxml import etree
response = requests.get('http://127.0.0.1:5000/')
html = etree.HTML(response.text)
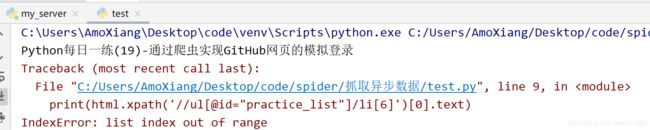
# 提取第2个列表项的文本
print(html.xpath('//ul[@id="practice_list"]/li[2]')[0].text)
# 提取第6个列表项的文本
print(html.xpath('//ul[@id="practice_list"]/li[6]')[0].text)
运行这段代码,会令人沮丧,因为会抛出异常,如下图所示:
读者可以输出 response.text ,会发现,抓取到的数据只有前4项,并没有后4项。为了进一步验证,可以切换到开发者工具的 Network 选项卡,然后在左下角选择 127.0.0.1,并且切换到右侧的 Response 选项卡,如下图所示:
 从
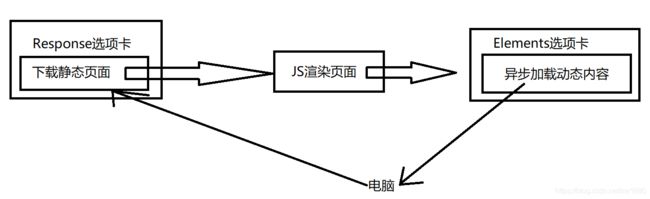
从 Response 选项卡也可以看出,下载的HTML代码只有前4个列表项。那么在这里为什么与 Elements 选项卡显示的HTML 代码不同呢?其实这两个地方显示的 HTML 代码处于不同阶段。Response 选项卡显示的 HTML 代码是在JavaScript 渲染页面前,而 Elements 选项卡显示的 HTML 代码是在 JavaScript 渲染页面后。异步加载页面以及Response 选项卡和 Elements 选项卡显示数据的过程下图所示。
还有一种简单的方式,就是鼠标右键单击页面,查看网页源代码,然后在源代码页面中进行搜索,看数据是否存在。如下图所示:
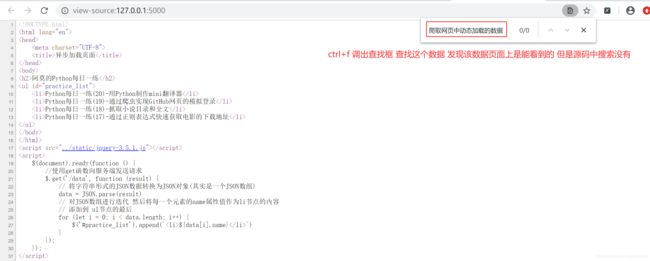
使用 requests 抓取的 HTML 代码并没有经过 JavaScript 渲染,所以是在 JavaScript 渲染前的代码,因此 requests抓取的 HTML 代码与 Response 选项卡中显示的 HTML 代码是一样的,不要被 Elements 选项卡欺骗了。
分析到这里,读者可以获得以下经验:如果数据没有在 Response 选项卡中,那么很可能是通过异步方式获取的数据,然后再利用 JavaScript 将数据显示在页面上。因为目前显示数据的方式只有两种:同步和异步。
接下来的任务就是找到异步访问的 URL,对于上面的例子来说相当好找,因为 Network 选项卡左下角的列表中就3个 URL,按顺序查看就可以了。但对于非常大的网站,如京东商城、淘宝、天猫等,可能会有数百个,甚至上千个URL,而目还会不断变化,如果一个个地找,是非常累的。所以可以采用直接过滤的方式。
如果知道大概的 URL 名字,可以利用下图所示的开发者工具左上角的 Filter 文本框过滤,但是大多数时候是不知道 URL 的名字的,所以可以使用 XHR 的方式过滤。现在单击 Network 选项卡的 XHR 按钮,如下图所示:
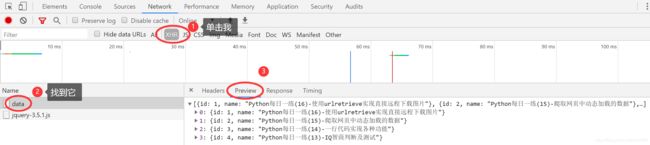
从上面很明显可以看出获取数据的路由名字,在右侧的Preview 选项卡中显示了 data 返回的数据,很显然,这是 JSON 格式的数据,其实现在已经完成了任务,找到了异步访问的 URL,并且了解了返回的数据格式。XHR 是什么呢? XHR 是XMLHttpRequest 的缩写,用于过滤通过异步方式请求的 URL,要注意的是,XHR 过滤的 URL 与返回数据的格式无关,只与发送请求的方式有关。XHR 用于过滤异步方式发送的请求。
知道了异步请求的 URL,就可以通过 requests 等网络库通过 URL 抓取数据,不过返回的数据格式不是 HTML,也不是 XML ,而是 JSON。示例代码如下:
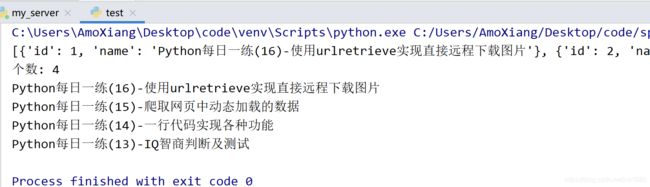
import requests
response = requests.get('http://127.0.0.1:5000/data')
data_list = response.json()
print(data_list)
print('个数:', len(data_list))
# 输出所有每日一练的名称
for data in data_list:
print(data['name'])
运行结果如下图所示:
4. 项目实战:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
本节实现爬取 爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据 相关数据。进入网站,打开开发者工具进行分析发现:
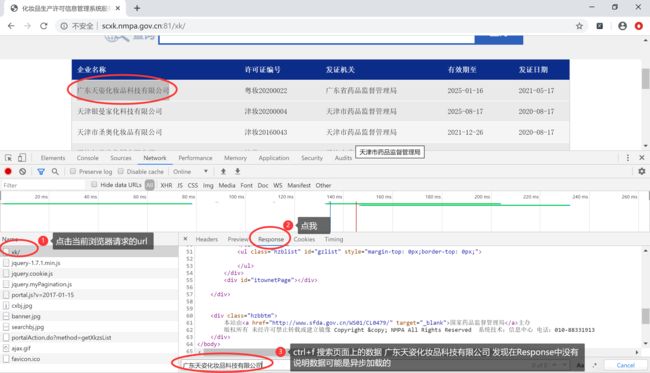
接着我们按照本文之前讲解的操作发现:
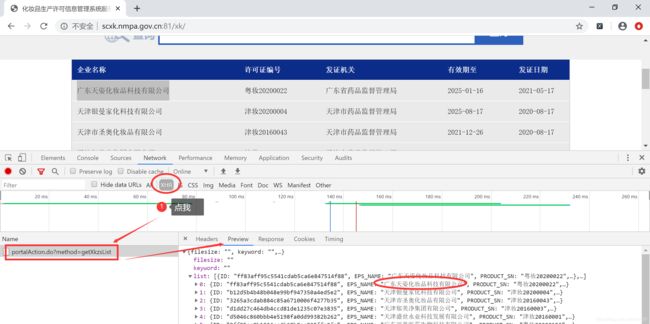 首页中对应的企业信息数据是通过
首页中对应的企业信息数据是通过 AJAX 请求到的。接下来就可以用代码完成此页信息的爬取了,但是发现,该页面的信息是较少的,所以我们要进入到详情页,进行详情页数据的爬取,这样又有一个问题诞生了?要进入到详情页,详情页的URL在哪呢?在之前AJAX 请求到的数据中吗?
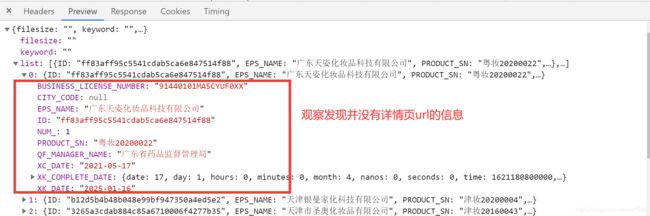
那么详情页的 URL 在哪呢?我们分别点开两个不同公司的详情页进行 URL 对比分析:天津银曼家化科技有限公司
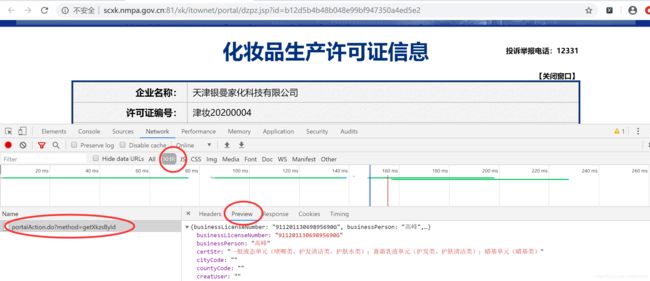
广东天姿化妆品科技有限公司:
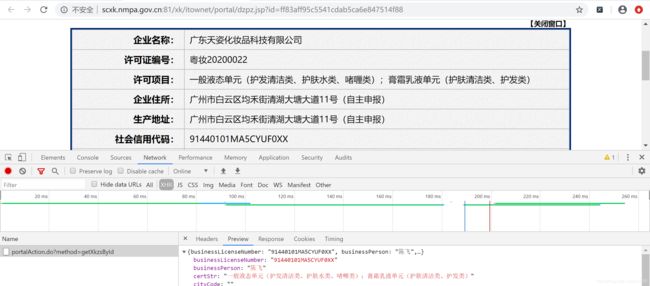
通过观察发现,详情页的企业详情数据也是动态加载出来的,该请求是 POST 请求,所有的 POST 请求的 URL 都是一样的,只有参数 id 值是不同。如果我们可以批量获取多家企业的 id 后,就可以将 id 和 URL 形成一个完整的详情页对应详情数据的 AJAX 请求的 URL。示例代码如下:
import requests
import xlsxwriter
def get_json(index):
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
form_data = {
'on': 'true',
'page': str(index),
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
}
all_data = []
try:
response = requests.post(url=url, headers=headers, data=form_data)
data_list = response.json().get('list', '')
for data in data_list:
company_id = data['ID']
detail_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
detail_response = requests.post(url=detail_url, headers=headers, data={'id': company_id})
if detail_response.status_code == 200:
all_data.append(detail_response.json())
except Exception as e:
print(e)
return all_data
def save_excel(content, index):
if content:
for num, item in enumerate(content):
# 因为Excel第一行要写入标题 所以row从1开始
row = 15 * (index - 1) + (num + 1)
# 行内容
work_sheet.write(row, 0, str(item["epsName"]))
work_sheet.write(row, 1, item["productSn"]) # 以文本的形式在Excel单元格中显示
work_sheet.write(row, 2, item["certStr"])
work_sheet.write(row, 3, item["epsAddress"])
work_sheet.write(row, 4, item["epsProductAddress"])
work_sheet.write(row, 5, item["businessLicenseNumber"])
work_sheet.write(row, 6, item["legalPerson"])
work_sheet.write(row, 7, item["businessPerson"])
work_sheet.write(row, 8, item["qualityPerson"])
work_sheet.write(row, 9, item["qfManagerName"])
work_sheet.write(row, 10, item["xkName"])
work_sheet.write(row, 11, item["rcManagerDepartName"])
work_sheet.write(row, 12, item["rcManagerUser"])
work_sheet.write(row, 13, item["xkDate"])
work_sheet.write(row, 14, item["xkDateStr"])
else:
pass
def main(index):
content = get_json(index)
save_excel(content, index)
if __name__ == '__main__':
print("*******************开始执行*******************")
work_book = xlsxwriter.Workbook("药监总局相关数据爬取.xlsx") # 创建excel文件
work_sheet = work_book.add_worksheet("first_sheet") # 创建sheet
# 行首标题
work_sheet.write(0, 0, "企业名称")
work_sheet.write(0, 1, "许可证编号")
work_sheet.write(0, 2, "许可项目")
work_sheet.write(0, 3, "企业住所")
work_sheet.write(0, 4, "生产地址")
work_sheet.write(0, 5, "社会信用代码")
work_sheet.write(0, 6, "法定代表人")
work_sheet.write(0, 7, "企业负责人")
work_sheet.write(0, 8, "质量负责人")
work_sheet.write(0, 9, "发证机关")
work_sheet.write(0, 10, "签发人")
work_sheet.write(0, 11, "日常监督管理机构")
work_sheet.write(0, 12, "日常监督管理人员")
work_sheet.write(0, 13, "有效期至")
work_sheet.write(0, 14, "发证日期")
total_page_count = 20
for i in range(total_page_count):
main(i + 1) # i+1即为页码
work_book.close() # 关闭excel写入
print("*******************执行结束*******************")
看完本篇文章,读者再也不用担心不会爬取动态加载的数据了。以上内容仅为技术交流,请勿采集数据进行商用,否则后果自负,与博主无关,如有侵权,联系博主删除,编写不易,手留余香~。