第十章-HMM模型以及相关推导
隐马尔可夫模型(Hidden Markov Model, HMM)是可用于标注问题的统计学习模型,描述由隐藏的马尔科夫链随机生成的观测序列的过程,属于生成模型,是概率模型的一种。本章主要是总结HMM模型的概率计算算法、学习算法以及预测算法。HMM在语音识别、自然语言处理NLP等领域有着广泛的应用。
概率图模型常常是为了描述随机变量之间的关系(是不是独立的),分为有向图和无向图,而HMM主要用有向图。
概率图模型
在有向图中,用圆圈⭕表示随机变量,可以是一维的,也可以是多维的,既可以是离散随机变量,也可以是连续的,⭕叫做结点,图是由结点和边构成的,在有向图中就是有向边,要描述Y受X影响的,就将X和Y连接起来,并用箭头描述从X指向Y的方向。
随机变量之间的关系
一个箭头可以表示两个随机变量之间的关系,引入条件独立的概念,在概率图模型中,假设有三个随机变量X,Y,Z,一般来说,隐变量在图模型中用⭕表示,如果能观察到一个变量取值的时候,用带阴影的圆\bullet表示。在掷硬币的例子中,第1个结果是观察不到的,用空心圆⭕表示,第2个结果是可以观察到的,用带阴影的圆●表示。为什么要强调隐变量和观测变量,圆是空心⭕还是阴影●会影响到随机变量的依赖性。
第一种情况
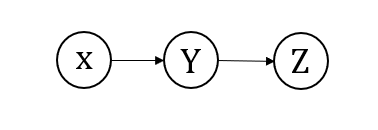
随机变量都是空心圆,三个随机变量都是观测不到的。即:
P ( X , Z ) ≠ P ( X ) ( Z ) P(X,Z) \neq P(X)(Z) P(X,Z)=P(X)(Z)
第二种情况

Y是带阴影的圆,随机变量Y是可以观测到的,可得P(X,Z|Y)=P(X|Y)P(Z|Y),从箭头的指向看,信息是从X传到Y,Y传到Z,一旦将Y固定了,信息的流通相当于被Y观察到的值堵住了,所以当观察到Y时,X和Z就是独立的。
第三种情况

Y指向了两边,这个时候单看X和Z是不独立的,满足P(X,Z) ≠ P(X)P(Z),如果给定Y,X和Z是独立的,满足
P ( X , Z ∣ Y ) = P ( X ∣ Y ) P ( Z ∣ Y ) P(X,Z|Y)=P(X|Y)P(Z|Y) P(X,Z∣Y)=P(X∣Y)P(Z∣Y)
第四种情况
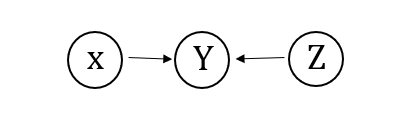
随机变量满足:
P ( X , Z ) = P ( X ) P ( Z ) , P ( X , Z ∣ Y ) ≠ P ( X ∣ Y ) P ( Z ∣ Y ) P(X,Z)=P(X)P(Z),P(X,Z|Y)\neq P(X|Y)P(Z|Y) P(X,Z)=P(X)P(Z),P(X,Z∣Y)=P(X∣Y)P(Z∣Y)
HMM模型
定义
隐马尔科夫模型是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔科夫链随机生成的状态序列称为状态序列(state sequence),每个状态生成一个观测值,而由此生成的观测的随机序列称为观测序列(observation sequence).
HMM是一个三元组,由初始状态概率向量、状态转移概率矩阵和观测概率矩阵决定,即:
λ = ( A , B , π ) , 其 中 π 是 初 始 状 态 概 率 向 量 , A 是 状 态 转 移 概 率 矩 阵 , B 是 观 测 概 率 矩 阵 \lambda = (A,B,\pi),其中\pi是初始状态概率向量,A是状态转移概率矩阵,B是观测概率矩阵 λ=(A,B,π),其中π是初始状态概率向量,A是状态转移概率矩阵,B是观测概率矩阵
定义的形式如下:
设 Q 是 所 有 可 能 的 状 态 的 集 合 , V 是 所 有 可 能 观 测 的 集 合 。 Q = { q 1 , q 2 , q 3 . . . q N } , V = { v 1 , v 2 , . . v M } , 其 中 N 是 所 有 可 能 的 状 态 数 , M 是 所 有 观 测 数 。 I 是 长 度 为 T 的 状 态 序 列 , O 是 对 应 的 观 测 序 列 。 I = ( i 1 , i 2 . . . i T ) , O = ( o 1 , o 2 . . . o T ) . A 是 状 态 转 移 概 率 矩 阵 : A = [ a i j ] N × N , 其 中 a i j = P ( i t + 1 = q j ∣ i t = q t ) , i = 1 , 2 , 3... N ; j = 1 , 2 , . . . N 是 时 刻 t 处 于 状 态 q i 的 条 件 下 在 时 刻 t + 1 转 移 到 状 态 q j 的 概 率 。 B 是 观 测 概 率 矩 阵 : B = [ b j ( k ) ] N × M , 其 中 , b j ( k ) = P ( o t = v k ∣ i t = q t ) , k = 1 , 2 , . . M ; j = 1 , 2 , . . . N 是 在 时 刻 t 处 于 状 态 q j 的 条 件 下 生 成 观 测 v k 的 概 率 。 π 是 初 始 状 态 概 率 向 量 : π = ( π i ) , 其 中 , π i = P ( i j = q i ) , i = 1 , 2 , . . . N 是 在 时 刻 t = 1 处 于 状 态 q i 的 概 率 。 设Q是所有可能的状态的集合,V是所有可能观测的集合。Q=\{q_1,q_2,q_3...q_N\},V=\{v_1,v_2,..v_M\},\\ 其中N是所有可能的状态数,M是所有观测数。\\ I是长度为T的状态序列,O是对应的观测序列。I=(i_1,i_2...i_T),O=(o_1,o_2...o_T).\\ A是状态转移概率矩阵:\\ A=[a_{ij}]_{N \times N},其中a_{ij}=P(i_{t+1}=q_j|i_t=q_t),i=1,2,3...N;j=1,2,...N\\ 是时刻t处于状态q_i的条件下在时刻t+1转移到状态q_j的概率。\\ B是观测概率矩阵:\\ B=[b_j(k)]_{N \times M},其中,b_j(k)=P(o_t=v_k|i_t=q_t),k=1,2,..M;j=1,2,...N\\ 是在时刻t处于状态q_j的条件下生成观测v_k的概率。\\ \pi是初始状态概率向量:\\ \pi=(\pi_i),其中,\pi_i=P(i_j=q_i),i=1,2,...N\\ 是在时刻t=1处于状态q_i的概率。\\ 设Q是所有可能的状态的集合,V是所有可能观测的集合。Q={q1,q2,q3...qN},V={v1,v2,..vM},其中N是所有可能的状态数,M是所有观测数。I是长度为T的状态序列,O是对应的观测序列。I=(i1,i2...iT),O=(o1,o2...oT).A是状态转移概率矩阵:A=[aij]N×N,其中aij=P(it+1=qj∣it=qt),i=1,2,3...N;j=1,2,...N是时刻t处于状态qi的条件下在时刻t+1转移到状态qj的概率。B是观测概率矩阵:B=[bj(k)]N×M,其中,bj(k)=P(ot=vk∣it=qt),k=1,2,..M;j=1,2,...N是在时刻t处于状态qj的条件下生成观测vk的概率。π是初始状态概率向量:π=(πi),其中,πi=P(ij=qi),i=1,2,...N是在时刻t=1处于状态qi的概率。
从定义可知,隐马尔科夫模型做了两个基本假设:
-
齐次马尔可夫性假设。即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一个时刻的状态,与其他时刻的状态以及预测无关,也与时刻t无关。
P ( i t ∣ i t − 1 , o t − 1 , . . . i 1 , o 1 ) = P ( i t ∣ i t − 1 ) , t = 1 , 2 , . . . T P(i_t|i_{t-1},o_{t-1},...i_1,o_1)=P(i_t|i_{t-1}),t=1,2,...T P(it∣it−1,ot−1,...i1,o1)=P(it∣it−1),t=1,2,...T -
观测独立性假设。即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他时刻观测以及状态无关。
P ( o t ∣ i T , o T , o T − 1 , o T − 1 , . . . , i t + 1 , o t + 1 , i t , i t − 1 , o t − 1 , . . . , i 1 , o 1 ) = P ( o t ∣ i t ) P(o_t|i_T,o_T,o_{T-1},o_{T-1},...,i_{t+1},o_{t+1},i_{t},i_{t-1},o_{t-1},...,i_1,o_1)=P(o_t|i_t) P(ot∣iT,oT,oT−1,oT−1,...,it+1,ot+1,it,it−1,ot−1,...,i1,o1)=P(ot∣it)
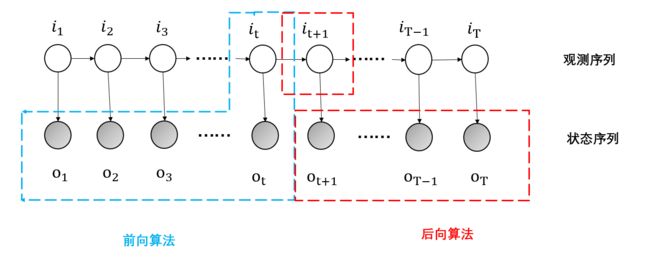
纯粹这样看定义,一堆的数学公式,可能看得不是很懂,那么可以采用概率图的方式来理解HMM模型,如图所示:
[外链图片转存失败(img-AS9wQj1D-1569397355722)(https://img2018.cnblogs.com/blog/842089/201909/842089-20190918152323147-1335165462.png)]
图中的一行⭕表示隐变量的集合,称为状态序列;●表示可观测的集合,称为观测序列,由图可看出,第一个状态变量会影响第二个状态变量,同时还会影响第一个观测变量,依次递推下去,隐马尔可夫模型从状态变量看是一个影响一个的,可以理解成时间序列模型,其适用范围为文本分析,比如标注问题。
三个基本问题
概率计算算法
给定模型和观测序列,那么计算在该模型下观测序列出现的概率的方法有三种:直接计算法、前向算法、后向算法。
直接计算法
P ( O ∣ λ ) = ∑ I P ( O ∣ I , λ ) P ( I ∣ λ ) = ∑ i 1 , i 2 , ⋯ , i T π i 1 b i 1 ( o 1 ) a i 1 i 2 b i 2 ( o 2 ) ⋯ a i T − 1 i T b i T ( o T ) 首 先 观 察 求 和 符 号 中 b 有 T 项 , a 有 T − 1 项 , π 有 1 项 , 一 共 有 2 T 项 , 求 和 是 从 i 1 , i 2 , ⋯ , i T 不 同 的 取 值 求 和 , 对 于 i 1 从 状 态 集 合 { q 1 , q 2 , . . . q N } 中 取 值 有 N 个 , i 2 取 值 有 N 个 … … i T 取 值 有 N 个 , 所 以 求 和 范 围 有 N T 项 , 要 对 N T 个 范 围 进 行 求 和 , 每 一 个 求 和 范 围 都 需 要 O ( T ) 个 计 算 量 , 所 以 计 算 复 杂 度 为 2 T × N T = 2 T N T = O ( T N T ) 。 \begin{aligned} P(O|\lambda) = \sum_I P(O|I,\lambda)P(I|\lambda) = \sum_{i_1,i_2,\cdots,i_T} \pi_{i_1}b_{i_1}(o_1)a_{i_1 i_2}b_{i_2}(o_2) \cdots a_{i_{T-1} i_T}b_{i_T}(o_T) \end{aligned}\\ 首先观察求和符号中b有T项,a有T-1项,\pi有1项,一共有2T项,求和是从i_1,i_2,\cdots,i_T不同的取值求和,\\对于i_1从状态集合\{q_1,q_2,...q_N\}中取值有N个,i_2取值有N个……i_T取值有N个,所以求和范围有N^T项,\\要对N^T个范围进行求和,每一个求和范围都需要O(T)个计算量,所以计算复杂度为\\2T \times N^T=2TN^T=O(TN^T)。 P(O∣λ)=I∑P(O∣I,λ)P(I∣λ)=i1,i2,⋯,iT∑πi1bi1(o1)ai1i2bi2(o2)⋯aiT−1iTbiT(oT)首先观察求和符号中b有T项,a有T−1项,π有1项,一共有2T项,求和是从i1,i2,⋯,iT不同的取值求和,对于i1从状态集合{q1,q2,...qN}中取值有N个,i2取值有N个……iT取值有N个,所以求和范围有NT项,要对NT个范围进行求和,每一个求和范围都需要O(T)个计算量,所以计算复杂度为2T×NT=2TNT=O(TNT)。
前向算法
输 入 : 隐 马 尔 可 夫 模 型 λ , 观 测 序 列 O 。 输 出 : 观 测 序 列 概 率 P ( O ∣ λ ) 。 ( 1 ) 初 值 : α 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , ⋯ , N ( 2 ) 递 推 , 对 t = 1 , 2 , ⋯ , T − 1 , α t + 1 ( i ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) , i = 1 , 2 , ⋯ , N ( 3 ) 终 止 。 P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) 输入:隐马尔可夫模型\lambda,观测序列O。\\ 输出:观测序列概率P(O|\lambda)。\\ (1)初值:\alpha_1(i)=\pi_i b_i(o_1), \quad i=1,2,\cdots,N\\ (2)递推,对t=1,2,\cdots,T-1,\alpha_{t+1}(i)=\left[\sum_{j=1}^N \alpha_t(j) a_{ji} \right]\\ b_i(o_t+1), \quad i=1,2,\cdots,N\\(3)终止。P(O|\lambda)=\sum_{i=1}^N \alpha_T(i) 输入:隐马尔可夫模型λ,观测序列O。输出:观测序列概率P(O∣λ)。(1)初值:α1(i)=πibi(o1),i=1,2,⋯,N(2)递推,对t=1,2,⋯,T−1,αt+1(i)=[j=1∑Nαt(j)aji]bi(ot+1),i=1,2,⋯,N(3)终止。P(O∣λ)=i=1∑NαT(i)
可是为何是这样子计算的吗?从数学的角度来推导下具体的算法计算方式——
1. 首 先 最 终 终 止 的 那 个 公 式 的 推 导 : 将 α t ( i ) 的 时 刻 t 的 观 测 值 o 1 , o 2 , ⋯ , o t 及 状 态 值 q i , 记 作 α t ( i ) = P ( o 1 , o 2 , ⋯ , o t , i t = q i ) ( 忽 略 λ 的 条 件 概 率 ) 。 前 向 算 法 用 来 做 的 就 是 概 率 计 算 , 当 λ 给 定 时 , 观 测 值 o 1 , o 2 , ⋯ , o t 出 现 的 概 率 为 P ( o 1 , o 2 , ⋯ , o T ) , 这 是 边 缘 概 率 , 而 P ( o 1 , o 2 , ⋯ , o T , i T = q i ) 是 联 合 概 率 , 可 得 P ( o 1 , o 2 , ⋯ , o T ) = ∑ i = 1 N P ( o 1 , o 2 , ⋯ , o T , i T = q i ) = ∑ i = 1 N α T ( i ) 。 2. 在 递 推 过 程 中 的 公 式 推 导 : ∵ 根 据 定 义 α t + 1 ( i ) = P ( o 1 , o 2 , ⋯ , o t , o t + 1 , i t + 1 = q i ) , 对 比 α t ( i ) = P ( o 1 , ⋯ , o t , i t = q i ) 少 了 o t + 1 , i t + 1 = q i , ∴ α t + 1 ( i ) = P ( o 1 , o 2 , ⋯ , o t , o t + 1 , i t + 1 = q i ) . . . . . . . . . . . . . . . . . . . . . . 联 合 概 率 = ∑ j = 1 N P ( o 1 , o 2 , . . . o t , o t + 1 , i t + 1 = q i , i t = q j ) . . . . . . . . . . . . . . . . . . . . . 边 缘 概 率 = ∑ j = 1 N P ( o 1 , o 2 , . . . o t , i t = q j ) P ( o t + 1 ∣ i t + 1 = q i ) P ( i t + 1 = q i ∣ i t = q t ) 又 ∵ P ( o t + 1 ∣ i t + 1 = q i ) = b i ( o t + 1 ) P ( i t + 1 = q i ∣ i t = q j ) = a j i P ( o 1 , o 2 , ⋯ , o t , i t = q j ) = α t ( j ) ∴ ∑ j = 1 N P ( o 1 , o 2 , ⋯ , o t , i t = q j ) P ( o t + 1 ∣ i t + 1 = q i ) P ( i t + 1 = q i ∣ i t = q j ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) ∴ α t + 1 ( i ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) 1.首先最终终止的那个公式的推导:\\ 将\alpha_t(i)的时刻t的观测值o_1,o_2,\cdots,o_t及状态值q_i,记作\alpha_t(i)=P(o_1,o_2,\cdots,o_t,i_t=q_i)(忽略\lambda的条件概率)。\\ 前向算法用来做的就是概率计算,当\lambda给定时,观测值o_1,o_2,\cdots,o_t出现的概率为P(o_1,o_2,\cdots,o_T),\\这是边缘概率,而P(o_1,o_2,\cdots,o_T, i_T=q_i)是联合概率,可得\\\displaystyle P(o_1,o_2,\cdots,o_T) = \sum_{i=1}^N P(o_1,o_2,\cdots,o_T, i_T=q_i)=\sum_{i=1}^N \alpha_T(i)。\\ 2.在递推过程中的公式推导:\\ \because 根据定义\alpha_{t+1}(i) = P(o_1,o_2,\cdots,o_t,o_{t+1},i_{t+1}=q_i),\\对比\alpha_{t}(i)=P(o_1,\cdots,o_t,i_t=q_i)少了o_{t+1},i_{t+1}=q_i,\\ \therefore \alpha_{t+1}(i) = P(o_1,o_2,\cdots,o_t,o_{t+1},i_{t+1}=q_i) ......................联合概率\\ =\sum_{j=1}^N P(o_1,o_2,...o_t,o_{t+1},i_{t+1}=q_i,i_t=q_j) .....................边缘概率\\ =\sum_{j=1}^N P(o_1,o_2,...o_t,i_t=q_j)P(o_{t+1}|i_{t+1}=q_i)P(i_{t+1}=q_i|i_t=q_t)\\ 又 \because P(o_{t+1}|i_{t+1}=q_i)=b_i(o_{t+1}) \\ P(i_{t+1}=q_i|i_t=q_j)=a_{ji} \\ P(o_1,o_2,\cdots,o_t, i_t=q_j)=\alpha_t(j)\\ \displaystyle \therefore \sum_{j=1}^N P(o_1,o_2,\cdots,o_t, i_t=q_j)P(o_{t+1}|i_{t+1}=q_i)P(i_{t+1}=q_i|i_t=q_j) = \left[ \sum_{j=1}^N \alpha_t(j) a_{ji}\right] b_i(o_{t+1}) \\ \displaystyle \therefore \alpha_{t+1}(i) = \left[ \sum_{j=1}^N \alpha_t(j) a_{ji}\right] b_i(o_{t+1}) 1.首先最终终止的那个公式的推导:将αt(i)的时刻t的观测值o1,o2,⋯,ot及状态值qi,记作αt(i)=P(o1,o2,⋯,ot,it=qi)(忽略λ的条件概率)。前向算法用来做的就是概率计算,当λ给定时,观测值o1,o2,⋯,ot出现的概率为P(o1,o2,⋯,oT),这是边缘概率,而P(o1,o2,⋯,oT,iT=qi)是联合概率,可得P(o1,o2,⋯,oT)=i=1∑NP(o1,o2,⋯,oT,iT=qi)=i=1∑NαT(i)。2.在递推过程中的公式推导:∵根据定义αt+1(i)=P(o1,o2,⋯,ot,ot+1,it+1=qi),对比αt(i)=P(o1,⋯,ot,it=qi)少了ot+1,it+1=qi,∴αt+1(i)=P(o1,o2,⋯,ot,ot+1,it+1=qi)......................联合概率=j=1∑NP(o1,o2,...ot,ot+1,it+1=qi,it=qj).....................边缘概率=j=1∑NP(o1,o2,...ot,it=qj)P(ot+1∣it+1=qi)P(it+1=qi∣it=qt)又∵P(ot+1∣it+1=qi)=bi(ot+1)P(it+1=qi∣it=qj)=ajiP(o1,o2,⋯,ot,it=qj)=αt(j)∴j=1∑NP(o1,o2,⋯,ot,it=qj)P(ot+1∣it+1=qi)P(it+1=qi∣it=qj)=[j=1∑Nαt(j)aji]bi(ot+1)∴αt+1(i)=[j=1∑Nαt(j)aji]bi(ot+1)
后向算法
输 入 : 隐 马 尔 可 夫 模 型 λ , 观 测 序 列 O 。 输 出 : 观 测 序 列 概 率 P ( O ∣ λ ) 。 ( 1 ) β T ( i ) = 1 , i = 1 , 2 , ⋯ , N 。 ( 2 ) 对 t = T − 1 , T − 2 , ⋯ , 1 , β t ( i ) = ∑ j = 1 N a i j b j ( o t + 1 ) β t + 1 ( j ) , i = 1 , 2 , ⋯ , N ( 3 ) P ( O ∣ λ ) = ∑ i = 1 N π i b i ( o 1 ) β 1 ( i ) 输入:隐马尔可夫模型\lambda,观测序列O。\\ 输出:观测序列概率P(O|\lambda)。\\ (1)\beta_T(i)=1,\quad i=1,2,\cdots,N。\\ (2)对t=T-1,T-2,\cdots,1,\beta_t(i)=\sum_{j=1}^N a_{ij}b_j(o_{t+1})\beta_{t+1}(j), \quad i=1,2,\cdots,N\\(3)P(O|\lambda)=\sum_{i=1}^N \pi_i b_i(o_1) \beta_1(i) 输入:隐马尔可夫模型λ,观测序列O。输出:观测序列概率P(O∣λ)。(1)βT(i)=1,i=1,2,⋯,N。(2)对t=T−1,T−2,⋯,1,βt(i)=j=1∑Naijbj(ot+1)βt+1(j),i=1,2,⋯,N(3)P(O∣λ)=i=1∑Nπibi(o1)β1(i)
学习问题
已知观测序列,需要估计参数。和之前讲过的很多模型是类似的,需要用一组训练数据集估计模型,之前可能是估计分类超平面,常用的两个方法:监督学习方法、Baum-Welch算法,这两种方法的区别在于哪个算法更贴近应用,这两个方法的学习设定是不一样的。
监督学习方法
假 设 已 给 训 练 数 据 包 含 S 个 长 度 相 同 的 观 测 序 列 和 对 应 的 状 态 序 列 ( O 1 , I 1 ) , ( O 2 , I 2 ) , ⋯ , ( O S , I S ) , 那 么 可 以 利 用 极 大 似 然 估 计 法 来 估 计 隐 马 尔 可 夫 模 型 的 参 数 。 具 体 方 法 如 下 : ( 1 ) 转 移 概 率 a i j 的 估 计 。 设 样 本 中 时 刻 t 处 于 状 态 i 时 刻 t + 1 转 移 到 状 态 j 记 为 A i j , 那 么 a i j 的 估 计 是 : a ^ i j = A i j ∑ j = 1 N A i j , i = 1 , 2 , ⋯ , N ; j = 1 , 2 , ⋯ , N ( 2 ) 观 测 概 率 b j ( k ) 的 估 计 。 设 样 本 中 状 态 为 j 观 测 为 k 的 频 数 是 B j k , 那 么 b j ( k ) 的 估 计 是 : b ^ j ( k ) = B j k ∑ k = 1 M B j k , j = 1 , 2 , ⋯ , N ; k = 1 , 2 , ⋯ , M ( 3 ) 初 始 状 态 概 率 π i 的 估 计 π ^ i 为 S 个 样 本 中 初 始 状 态 为 q i 的 频 率 。 假设已给训练数据包含S个长度相同的观测序列和对应的状态序列{(O_1,I_1),(O_2,I_2),\cdots,(O_S,I_S)},\\那么可以利用极大似然估计法来估计隐马尔可夫模型的参数。具体方法如下:\\ (1)转移概率a_{ij}的估计。\\ 设样本中时刻t处于状态i时刻t+1转移到状态j记为A_{ij},那么a_{ij}的估计是:\\ \hat{a}{ij}=\frac{A{ij}}{\displaystyle \sum_{j=1}^N A_{ij}}, \quad i=1,2,\cdots,N; j=1,2,\cdots,N\\ (2)观测概率b_j(k)的估计。\\ 设样本中状态为j观测为k的频数是B_{jk},那么b_j(k)的估计是:\\\hat{b}j(k)=\frac{B{jk}}{\displaystyle \sum_{k=1}^M B_{jk}}, \quad j=1,2,\cdots,N;k=1,2,\cdots,M\\ (3)初始状态概率\pi_i的估计\hat{\pi}_i为S个样本中初始状态为q_i的频率。 假设已给训练数据包含S个长度相同的观测序列和对应的状态序列(O1,I1),(O2,I2),⋯,(OS,IS),那么可以利用极大似然估计法来估计隐马尔可夫模型的参数。具体方法如下:(1)转移概率aij的估计。设样本中时刻t处于状态i时刻t+1转移到状态j记为Aij,那么aij的估计是:a^ij=j=1∑NAijAij,i=1,2,⋯,N;j=1,2,⋯,N(2)观测概率bj(k)的估计。设样本中状态为j观测为k的频数是Bjk,那么bj(k)的估计是:b^j(k)=k=1∑MBjkBjk,j=1,2,⋯,N;k=1,2,⋯,M(3)初始状态概率πi的估计π^i为S个样本中初始状态为qi的频率。
观 测 序 列 和 状 态 序 列 都 有 S 个 样 本 , 需 要 估 计 的 参 数 : 首 先 初 始 状 态 π , 如 果 直 接 用 极 大 似 然 估 计 , 就 是 看 这 S 个 样 本 中 在 初 始 状 态 时 的 各 个 取 值 的 频 率 。 概 率 转 移 矩 阵 A , 前 一 个 状 态 i t = q i , 后 一 个 状 态 i t + 1 = q j 的 概 率 记 作 a i j , 考 察 在 S 个 观 测 序 列 中 , 每 个 观 测 序 列 都 是 有 ( i 1 , i 2 , ⋯ , i T − 1 , i T ) , 一 共 有 S 个 这 样 的 马 尔 可 夫 链 , 总 计 S ( T − 1 ) 组 , 在 这 些 序 列 组 中 有 多 少 是 观 测 序 列 为 q i , 然 后 在 这 些 组 中 , 又 有 多 少 组 后 一 项 的 状 态 取 值 为 q j , 这 样 的 比 例 就 是 a i j 的 估 计 。 观 测 概 率 b j ( k ) 的 估 计 也 是 类 似 的 。 观测序列和状态序列都有S个样本,需要估计的参数:\\ 首先初始状态\pi,如果直接用极大似然估计,就是看这S个样本中在初始状态时的各个取值的频率。\\ 概率转移矩阵A,前一个状态i_t=q_i,后一个状态i_{t+1}=q_j的概率记作a_{ij},考察在S个观测序列中,\\每个观测序列都是有(i_1,i_2,\cdots,i_{T-1},i_T),一共有S个这样的马尔可夫链,总计S(T-1)组,\\在这些序列组中有多少是观测序列为q_i,然后在这些组中,又有多少组后一项的状态取值为q_j,\\这样的比例就是a_{ij}的估计。 观测概率b_j(k)的估计也是类似的。 观测序列和状态序列都有S个样本,需要估计的参数:首先初始状态π,如果直接用极大似然估计,就是看这S个样本中在初始状态时的各个取值的频率。概率转移矩阵A,前一个状态it=qi,后一个状态it+1=qj的概率记作aij,考察在S个观测序列中,每个观测序列都是有(i1,i2,⋯,iT−1,iT),一共有S个这样的马尔可夫链,总计S(T−1)组,在这些序列组中有多少是观测序列为qi,然后在这些组中,又有多少组后一项的状态取值为qj,这样的比例就是aij的估计。观测概率bj(k)的估计也是类似的。
Baum-Welch算法(EM算法)
KaTeX parse error: Can't use function '$' in math mode at position 101: …0)},\pi_i^{(0)}$̲,得到模型$\lambda^{…
预测问算法
该算法其实就是一个标注问题,已知观测序列和模型参数,让计算机标注每一个观测值的状态,书中提出了两个算法:近似算法(得到的结果并不是全局最优解)、维特比算法(用动态规划思想求最优路径)。但是最常用的还是维特比算法。
维特比算法
维特比算法是求解给定的观测条件下,使得概率最大的状态变量的序列预测,也就是说,求解已知观测序列的出现的概率最大。
输 入 : 模 型 λ = ( A , B , π ) 和 观 测 O = ( o 1 , o 2 , ⋯ , o T ) 。 输 出 : 最 优 路 径 I = ( i 1 , i 2 , ⋯ , i T ) 。 ( 1 ) 初 始 化 。 δ 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , ⋯ , N ψ 1 ( i ) = 0 , i = 1 , 2 , ⋯ , N ( 2 ) 递 推 , 对 t = 2 , 3 , ⋯ , T δ t ( i ) = max 1 ⩽ j ⩽ N [ δ t − 1 ( j ) a j i ] b i ( o t ) , i = 1 , 2 , ⋯ , N ψ t ( i ) = arg max 1 ⩽ j ⩽ N [ δ t − 1 ( j ) a j i ] , i = 1 , 2 , ⋯ , N 。 ( 3 ) 终 止 。 P = max 1 ⩽ i ⩽ N δ T ( i ) i T = max 1 ⩽ i ⩽ N [ δ T ( i ) ] ( 4 ) 最 优 路 径 回 溯 , 对 t = T − 1 , T − 2 , ⋯ , 1 i t = ψ t + 1 ( i t + 1 ) 求 得 最 优 路 径 I = ( i 1 , i 2 , ⋯ , i T ) . 输入:模型\lambda=(A,B,\pi)和观测O=(o_1,o_2,\cdots,o_T)。 输出:最优路径I^=(i_1^,i_2^,\cdots,i_T^)。\\ (1)初始化。\delta_1(i) = \pi_i b_i(o_1),\quad i=1,2,\cdots,N \ \psi_1(i)=0,\quad i=1,2,\cdots,N\\(2)递推,对t=2, 3,\cdots,T \delta_t(i)=\mathop{\max} \limits_{1 \leqslant j \leqslant N}\left[\delta_{t-1}(j)a_{ji} \right] b_i(o_t),\quad i=1,2,\cdots,N \\ \psi_t(i) = \mathop{\arg \max} \limits_{1 \leqslant j \leqslant N} \left[\delta_{t-1}(j)a_{ji} \right], \quad i=1,2,\cdots,N。\\(3)终止。P^=\mathop{\max} \limits_{1 \leqslant i \leqslant N} \delta_T(i) \ i_T^=\mathop{\max} \limits_{1 \leqslant i \leqslant N} \left[\delta_T(i) \right] \\(4)最优路径回溯,对t=T-1,T-2,\cdots,1 i_t^=\psi_{t+1}(i_{t+1}^)求得最优路径I^=(i_1^,i_2^,\cdots,i_T^). 输入:模型λ=(A,B,π)和观测O=(o1,o2,⋯,oT)。输出:最优路径I=(i1,i2,⋯,iT)。(1)初始化。δ1(i)=πibi(o1),i=1,2,⋯,N ψ1(i)=0,i=1,2,⋯,N(2)递推,对t=2,3,⋯,Tδt(i)=1⩽j⩽Nmax[δt−1(j)aji]bi(ot),i=1,2,⋯,Nψt(i)=1⩽j⩽Nargmax[δt−1(j)aji],i=1,2,⋯,N。(3)终止。P=1⩽i⩽NmaxδT(i) iT=1⩽i⩽Nmax[δT(i)](4)最优路径回溯,对t=T−1,T−2,⋯,1it=ψt+1(it+1)求得最优路径I=(i1,i2,⋯,iT).
具体的例子可以看书中的简单例子。但是要注意的是,在求得每个时刻的观测出现的概率的过程中,一定要记录每个概率最大路径的前一个状态,还有即使在回溯的过程中,要注意通过终点逐步逆向回溯的计算。