机器学习——条件随机场(CRF)原理
机器学习——条件随机场(CRF)原理
1. 条件随机场(CRF)引入
1.1 数学基础
1.1.0 无向概率图
在一个无向图中,任意两个具有边连接的节点x,y,如果从x节点走的y节点是具有一定概率数值的,则这种图被称为无向概率图。马尔科夫随机场就是一种无向的概率图。
1.1.1 团与极大团
在无向图中,任意两个节点之间具有边连接的各个节点集合构成了一个团。在各个团中,如果再加入一个节点,就不能再构成团的节点集合被称为极大团。
例如:在下图中

其中,团为{1,2},{1,3},{2,3},{2,4},{3,4},{3,5},{1,2,3},{2,3,4},{3,5}
极大团为{1,2,3},{2,3,4},{3,5}
1.1.2 势函数
势函数是一个非负的函数,主要用于定义一个概率分布。在马尔科夫随机场的无向图中,多个变量之间的联合概率分布可以基于团分解成多个势函数的乘积,每一个势函数仅仅与一个随机变量相关。
1.1.3 Hammersley-cllifford定理
对于n个变量的马尔科夫随机场,其变量为 X = X 1 , X 2 , X 3 , . . . . . . . X n X={X_1,X_2,X_3,.......X_n} X=X1,X2,X3,.......Xn,在该无向图中,所有的团构成了集合C,团Q∈C,Q对应的X的集合为Q(X),则联合概率分布为:
P ( X ) = 1 Z ∗ ∏ Q ∈ C φ Q ( Q ( X ) ) P(X) = \frac{1}{Z} * ∏_{Q∈C} φ_Q(Q(X)) P(X)=Z1∗Q∈C∏φQ(Q(X))
其中 φ Q φ_Q φQ是函数,Z为规范化因子。
为了进一步的化简运算,只需要计算极大团Q*(X),就可以简化对对于上面式子的运算。即
P ( X ) = 1 Z ∗ ∏ Q ∗ ∈ C ∗ φ Q ( Q ∗ ( X ) ) P(X) = \frac{1}{Z} * ∏_{Q^*∈C^*} φ_{Q}(Q^*(X)) P(X)=Z1∗Q∗∈C∗∏φQ(Q∗(X))
其中 C ∗ C^* C∗表示极大团的集合, Q ∗ Q^* Q∗表示一个极大团。
1.1.4 分离
设A,B,C分别是无向图马尔科夫随机场的的三个节点集合,如果A中的任意节点想要到B中任意节点(假设可以到达),都需要经过集合C的定点。则称C为A、B的分离集合。我们用图来表示一下:

在上图中,集合A中的节点想要到达集合B中的节点就必须要经过集合C中的节点,所以集合C称为集合A,集合B的分离集。
1.1.5 马尔科夫性
先给出如下实例图:

如图所示的是一个无向图G,其中集合A包括{1,2}两个节点,集合C包括{3,4,5}三个节点,集合B包括{6,7}三个节点。显然,集合C是集合A,B的分离节点。
全局马尔科夫性,集合A,B,C,C是分离集,在给定随机变量 Y c Y_c Yc的条件下, Y a Y_a Ya, Y b Y_b Yb条件独立。例如上图所示的在集合C给定的条件下,A,B独立,也就是1,2⊥6,7|3,4,5。
局部马尔科夫性 V是整个无向图G中的任意一点,W是无向图上所有和V相连接的节点集合,O是G上非V和W的节点。则在给定 Y w Y_w Yw的条件下, Y v Y_v Yv和 Y o Y_o Yo条件独立。在上图中如果V取节点1,W则为{2,3},则在W给定的条件下,1和4,5,6,7独立。
成对马尔科夫性 U,V是无向概率图G中的任意两个没有边连接的节点。O是除了U,V以外的其他节点,则在 Y O Y_O YO给定的条件下, Y U Y_U YU和 Y V Y_V YV独立。比如U,V分别取1和7,那么在2,3,4,5,6给定的条件下,1和7条件独立。
满足上面任何的一个特性,该无向概率图就可以成为马尔科夫随机场
1.1.6 特征函数
特征函数是一种实值函数,是用来刻画数据的特征成立的时的函数。例如:
f ( x , y ) = { 1 i f y = 性 别 a n d x = 男 或 者 女 0 e l s e f(x,y)=\begin{cases} 1&&if &y=性别 & and&x=男或者女\\ 0&&else \end{cases} f(x,y)={10ifelsey=性别andx=男或者女
上面是一个简单的特征函数,目的使用来对性别进行判断,当标签Y为性别,输入值X为男或者女的时候函数值为1,否则为0。
2 条件随机场
2.1 条件随机场概述
CRF是一种无向图,判别式的模型。而HMM模型是生成式模型,简单的解释一下,对于HMM模型,我们是利用前一个状态转移的当前的状态,可以理解成是用前一个状态“生成”了当前的状态。而CRF是根据周围节点的状态来“判别”当前状态的概率。
其具体的概念为设X,Y是随机变量,P(Y|X)是在X的条件下Y的概率分布,如果随机变量的Y构成的无向图G(V,E)是一个马尔科夫随机场,则称该无向概率图是条件随机场(CRF)。
这个概念有些抽象,我具体的解释一下,X,Y是两个随机变量,随机变量Y的各个时刻的状态构成了一个无向的概率图G=
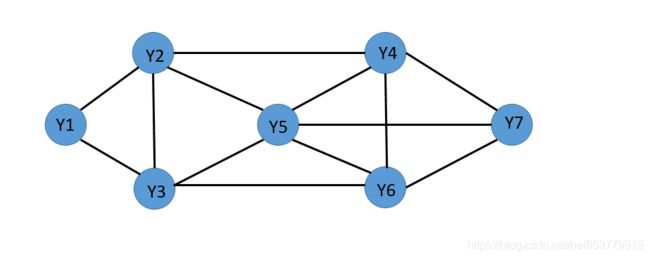
如上图所示,假设随机变量Y的所有取值构成上面的无向图,我们可以看出 P ( Y 1 ∣ X , Y Z ) = P ( Y 1 ∣ X , Y 2 , Y 3 ) P(Y_1|X,Y_Z)=P(Y_1|X,Y_2,Y_3) P(Y1∣X,YZ)=P(Y1∣X,Y2,Y3),也就是上面的图构成一个条件随机场。
2.2 线性CRF形式
线性的CRF是最为常用的结构,如下图所示:
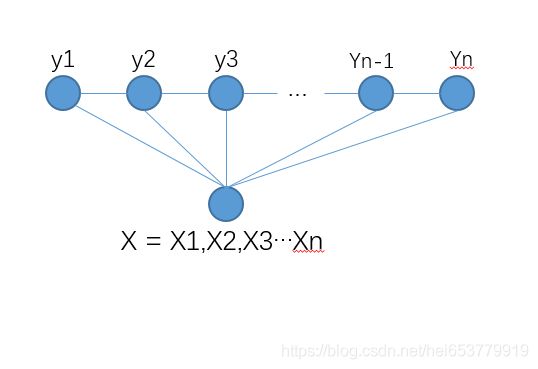
如上所示,在CRF随机场中,如果每一个状态只和前一个状态和后一个状态相关关联,那么我们就可以将无向的概率图结构伸展成线性链条的结构。如上面的 Y 1 , Y 2 , . . . Y n Y_1,Y_2,...Y_n Y1,Y2,...Yn所示。由于在CRF中,基本形式是 P ( Y ∣ X ) P(Y|X) P(Y∣X),也就是说随机场中的每一个节点都与X相关。所以总的结构如上图所示。
进一步,我们将随机变量X的各种取值展开,就有了下面的结构:

在上面的结构中,我们将随机变量X按照时刻进行展开,也就是说 X i X_i Xi都代表着X在第i个时刻的状态值。
举一个例子来说,下面要进行的命名实体识别的过程中,对于一个实体而言,B表示实体的开始的字,E表示实体结束的字。M表示实体的中间的字,S表示单独一个字构成一个实体,O表示其他非实体的字。“EMSO”就代表了随机变量Y的四种取值:“北京市是中国的首都”,这些字对应的就是随机变量X的所有取值,第i个时刻,我们选择一个X的取值 X i X_i Xi,与此对应的是一个Y的取值状态,也就是某一个标签值。
Y 1 , Y 2 , Y 3 , . . . Y n Y_1,Y_2,Y_3,...Y_n Y1,Y2,Y3,...Yn称之为状态序列, X 1 , X 2 , X 3 . . . X n X_1,X_2,X_3...X_n X1,X2,X3...Xn称之为观察序列。在给定观察序列X的条件下,若随机状态序列Y的条件概率分布P(Y|X)满足随机变量Y满足马尔科夫性,即:
P ( Y i ∣ X , Y 1 , Y 2 , Y 3 , . . . . Y n ) = P ( Y i ∣ X , Y i − 1 ) P(Y_i|X,Y_1,Y_2,Y_3,....Y_n) = P(Y_i|X,Y_{i-1}) P(Yi∣X,Y1,Y2,Y3,....Yn)=P(Yi∣X,Yi−1)
也就是说,当前状态 Y i Y_i Yi仅仅和其相连接的状态 Y i − 1 Y_{i-1} Yi−1和输入X相关。
2.3 CRF的数学描述
2.3.1 特征函数的定义
我们首先从特征函数的定义开始,根据上面描述的线性CRF的结构特征,我们可以定义出两种特征函数,第一个特征函数是从状态 Y i Y_i Yi到输出 X i X_i Xi的特征序列,也称为节点特征函数,其数学形式为:
S l ( Y i , X , i ) = { 1 0 S_l(Y_i,X,i)=\begin{cases} 1\\ 0\end{cases} Sl(Yi,X,i)={10
在这个特征函数中,l∈[1,L]表示的是当前时刻S特征函数的第l个特征函数。i表示时刻, Y i Y_i Yi表示当前时刻的状态,X表示当前时刻的输出。当状态 Y i Y_i Yi输出X符合的期望的时候,特征值为1,否则特征值为0。举个例子来说,当前的观测 X i X_i Xi对应的汉字为“北”,如果状态 Y i Y_i Yi对应的标注为“B”,则特征函数的值为1,如果标记为M,则特征函数值为0。
第二个特征函数是关于状态转移的,也称为是边特征函数,其基本的数学形式为:
T k ( Y i − 1 , Y i , X , i ) = { 1 0 T_k(Y_{i-1},Y_i,X,i)=\begin{cases} 1\\ 0\end{cases} Tk(Yi−1,Yi,X,i)={10
在这个特征函数中,k∈[1,K]表示当前T特征函数的第k个特征函数,i表示时刻, Y i − 1 , Y i Y_{i-1},Y_i Yi−1,Yi分别表示当前时刻的状态和前一个时刻的状态。当前状态符合前一个状态的期望转移的时候特征值为1,否则特征值为0。举个例子来说,对于实体“北京市”,如果前一个时刻的状态为“北”对应的“B”,那么当前时刻如果为“M”,则特征函数值为1,否则为0。
2.3.2 CRF的公式定义
在定义完两种特征函数之后,下面我们给出CRF的基本公式的定义:
P ( Y ∣ X ) = 1 Z ( X ) e x p ( ∑ i , k λ k T k ( Y i − 1 , Y i , X , i ) + ∑ i , l μ l S l ( Y i , X , i ) ) P(Y|X)=\frac{1}{Z(X)}exp(∑_{i,k}λ_kT_k(Y_{i-1},Y_i,X,i)+∑_{i,l}μ_lS_l(Y_i,X,i)) P(Y∣X)=Z(X)1exp(i,k∑λkTk(Yi−1,Yi,X,i)+i,l∑μlSl(Yi,X,i))
其中,Z(X)表示归一化因子,Z(X)的基本形式为:
Z ( X ) = ∑ Y e x p ( ∑ i , k λ k T k ( Y i − 1 , Y i , X , i ) + ∑ i , l μ l S l ( Y i , X , i ) ) Z(X)=∑_{Y}exp(∑_{i,k}λ_kT_k(Y_{i-1},Y_i,X,i)+∑_{i,l}μ_lS_l(Y_i,X,i)) Z(X)=Y∑exp(i,k∑λkTk(Yi−1,Yi,X,i)+i,l∑μlSl(Yi,X,i))
其中 λ i 和 u i λ_i和u_i λi和ui分别表示的是边特征函数和节点特征函数的权重。
下面,我们来简单的解释一下上面的基本公式,首先是 ∑ i , k λ k T k ( Y i − 1 , Y i , X , i ) ∑_{i,k}λ_kT_k(Y_{i-1},Y_i,X,i) ∑i,kλkTk(Yi−1,Yi,X,i)这一部分主要是对于节点特征函数的求和过程,包含了每一个时刻i,以及每一个节点特征函数 T k T_k Tk。这个部分只要刻画的是在每一个时刻,状态的观测值对于状态值的“期望”。符合期望则特征值为1,不符合则特征值为0。
第二个部分,我们要介绍的是 ∑ i , l μ l S l ( Y i , X , i ) ) ∑_{i,l}μ_lS_l(Y_i,X,i)) ∑i,lμlSl(Yi,X,i))这一部分主要是对于边特征函数求和的过程,包含了每一个时刻i,以及每一个边特征函数 S l S_l Sl,其刻画的主要是当前状态标签是否符合前一个时刻状态的“期望”,如果符合,则特征值为1,否则特征值为0。
我们不难发现的是,两个部分的求和的过程是在所有的可能的序列上进行的。
2.3.3 CRF的公式简化
在上面的描述中,我们采用了 S l S_l Sl表示节点的特征函数,采用 T k T_k Tk表示的边的特征函数,为了表示更加简单,我们将其整理一下:
- 首先我们假设 M 1 M_1 M1=L, M 2 M_2 M2=K,也就是说,一共的特征函数包括 M = M 1 + M 2 M=M_1+M_2 M=M1+M2个特征函数。
- 我们使用一个统一的特征函数进行表示
f m ( Y i − 1 , Y i , X , i ) = T m ( Y i , Y i − 1 , X , i ) , m ∈ [ 1 , M 1 ] f_m(Y_{i-1},Y_i,X,i)=T_m(Y_i,Y_{i-1},X,i),m∈[1,M_1] fm(Yi−1,Yi,X,i)=Tm(Yi,Yi−1,X,i),m∈[1,M1]
f m ( Y i − 1 , Y i , X , i ) = S m ( Y i , Y i − 1 , X , i ) , m ∈ [ M 1 + 1 , M ] f_m(Y_{i-1},Y_i,X,i)=S_m(Y_i,Y_{i-1},X,i),m∈[M_1+1,M] fm(Yi−1,Yi,X,i)=Sm(Yi,Yi−1,X,i),m∈[M1+1,M]
这样,我们将边的特征函数和节点的特征函数进行整理成一个特征函数。与此同时,我们在对权重进行整理有:
W m = λ m , m ∈ [ 1 , M 1 ] W_m=λ_m ,m∈[1,M_1] Wm=λm,m∈[1,M1]
W m = s m , m ∈ [ M 1 + 1 , M ] W_m=s_m ,m∈[M_1+1,M] Wm=sm,m∈[M1+1,M]
则,整理之后的条件随机场为:
P ( Y ∣ X ) = 1 Z ( X ) e x p ( ∑ m = 1 M W m f m ( Y , X ) ) P(Y|X)=\frac{1}{Z(X)}exp(∑_{m=1}^MW_mf_m(Y,X)) P(Y∣X)=Z(X)1exp(m=1∑MWmfm(Y,X))
向量化表示就是:
W = [ W 1 , W 2 , . . . W M ] T W = [W_1,W_2,...W_M]^T W=[W1,W2,...WM]T
F ( Y , X ) = [ f 1 ( Y , X ) , f 2 ( Y , X ) , . . . . . . f M ( Y , X ) ] T F(Y,X)=[f_1(Y,X),f_2(Y,X),......f_M(Y,X)]^T F(Y,X)=[f1(Y,X),f2(Y,X),......fM(Y,X)]T
则有:
P W ( Y ∣ X ) = e x p ( W F ( Y , X ) ) Z W ( X ) P_W(Y|X)=\frac{exp(WF(Y,X))}{Z_W(X)} PW(Y∣X)=ZW(X)exp(WF(Y,X))
2.3.4 条件随机场的矩阵形式
我们假设Y的取值空间为 [ y 1 , y 2 , . . . . y q ] [y_1,y_2,....y_q] [y1,y2,....yq],也就是说Y一共有q中取值,我们可以定义一个关于Y的取值的q*q的矩阵Q,其中:
Q i ( X ) = [ Q i ( Y i − 1 , Y i ∣ X ) ] Q_i(X)=[Q_i(Y_{i-1},Y_i|X)] Qi(X)=[Qi(Yi−1,Yi∣X)]
M i ( Y i − 1 , Y i ∣ X ) = e x p ( B i ( Y i − 1 , Y i ∣ X ) ) M_i(Y_{i-1},Y_i|X)=exp(B_i(Y_{i-1},Y_i|X)) Mi(Yi−1,Yi∣X)=exp(Bi(Yi−1,Yi∣X))
B i ( Y i − 1 , Y i ∣ X ) = B_i(Y_{i-1},Y_i|X)= Bi(Yi−1,Yi∣X)=
3 CRF中的三个问题以及求解过程
3.1 CRF线性链的三个问题
在之前文章机器学习——隐马尔科夫(HMM)原理中,我们提到了HMM模型有三个基本的问题,同样,CRF也存在着三个待求解的问题。值得注意的是,在HMM中,我们将观测序列按照时刻逐个的进行计算,但是在CRF中,我们无需拆开观测序列X,相比而言,CRF更加的容易。下面我们具体描述CRF的三个基本问题:
- 评估问题: 类似于HMM,CRF也具有概率计算的问题。给定观测序列O和条件随机场,求条件概率 P ( Y t = y i ∣ O ) , P ( Y t − 1 = y i − 1 , Y t = y i ∣ O ) P(Y_t = y_i|O),P(Y_{t-1}=y_{i-1},Yt=y_i|O) P(Yt=yi∣O),P(Yt−1=yi−1,Yt=yi∣O)以及相应的数学期望。
- 学习问题,也就是采用训练数据训练CRF中的权重参数。
- 解码问题,给定CRF,条件概率分布P(Y|X),观测序列X,求解条件概率最大的状态序列Y*。
3.2 估计问题求解,
所谓的给定条件随机场,指的就是给定相关的约束条件,即给定相关的特征函数和对应的特征函数的权重值。处理这个问题的基本算法仍然是HMM中的前向后向算法,其中我们定义:
给定的条件随机场: γ γ γ
前向概率:定义 α t ( i ) α_t(i) αt(i),表示在t时刻 Y = y i Y=y_i Y=yi,同时忽略前面状态取值的概率。用公式表达就是:
α t ( i ) = P ( O 1 , O 2 , . . . O t Y t = y i ∣ γ ) α_t(i)=P(O_1,O_2,...O_t Y_t=y_i|γ) αt(i)=P(O1,O2,...OtYt=yi∣γ)
后向概率:定义 β t ( i ) β_t(i) βt(i),表示表示在t时刻 Y = y i Y=y_i Y=yi,同时忽略后面状态取值的概率。用公式表达就是:
β t ( i ) = P ( O T , O T − 1 , . . . , O t , Y t = y i ∣ γ ) β_t(i)=P(O_T,O_{T-1},...,O_{t},Y_t=y_i|γ) βt(i)=P(OT,OT−1,...,Ot,Yt=yi∣γ)
通过前向和后向概率的定义,我们就可以计算出概率为:
P ( Y i = y i ∣ O ) = α t ( i ) T β t ( i ) Z ( X ) P(Y_i=y_i|O)=\frac{α_t(i)^Tβ_t(i)}{Z(X)} P(Yi=yi∣O)=Z(X)αt(i)Tβt(i)
P ( Y t − 1 = y i − 1 , Y t = y i ∣ O ) = α t ( i ) T B i ( Y t − 1 , Y t ∣ O ) β t ( i ) Z ( X ) P(Y_{t-1}=y_{i-1},Y_t=y_i|O)=\frac{α_t(i)^TB_i(Y_{t-1},Y_t|O)β_t(i)}{Z(X)} P(Yt−1=yi−1,Yt=yi∣O)=Z(X)αt(i)TBi(Yt−1,Yt∣O)βt(i)
这样,通过类似于前向和后向的推导,我们最终可以确定整个状态序列的概率。
3.3 学习问题
首先,我们再来回顾一下CRF的基本公式:
P ( Y ∣ X ) = 1 Z ( X ) e x p ( ∑ i = 1 n W i F i ( X , Y ) ) P(Y|X)=\frac{1}{Z(X)}exp(∑_{i=1}^nW_iF_i(X,Y)) P(Y∣X)=Z(X)1exp(i=1∑nWiFi(X,Y))
Z ( X ) = ∑ y e x p ( ∑ i = 1 M W i F i ( X , Y ) ) Z(X)=∑_yexp(∑_{i=1}^MW_iF_i(X,Y)) Z(X)=y∑exp(i=1∑MWiFi(X,Y))
其中有:
F ( x , y ) = { 1 , 存 在 着 某 种 关 系 0 , 否 则 F(x,y)=\begin{cases}1,存在着某种关系\\ 0,否则 \end{cases} F(x,y)={1,存在着某种关系0,否则
在CRF的学习问题中,我们给定了特征函数的定义,也就是说我们实现已经知道了 T k T_k Tk和 S l S_l Sl的函数定义,我们的目标是获取对应的权重W,为了实现这个目标,我们需要事先定义目标函数,可以采用极大似然估计,这里我们采用的时候极大似然函数作为目标函数:
我们设观测序列和对应的状态序列为 ( O 1 , Y 1 ) , ( O 2 , Y 2 ) , . . . ( O n , Y n ) (O^1,Y^1),(O^2,Y^2),...(O^n,Y^n) (O1,Y1),(O2,Y2),...(On,Yn),接下来我们设经验概率为 P ∗ ( O i , Y i ) P^*(O^i,Y^i) P∗(Oi,Yi),则对应的极大似然函数为:
L ( W ) = ∏ x , y P W ( y ∣ x ) P − ( x , y ) L(W) = ∏_{x,y}P_W(y|x)^{P^-(x,y)} L(W)=x,y∏PW(y∣x)P−(x,y)
其中 p − ( x , y ) p^-(x,y) p−(x,y)表示的是经验分布,可以从先验知识和训练集样本中得到,进一步,其对数似然函数为:
l o g ( L ( W ) ) = ∑ x , y P − ( x , y ) l o g ( P W ( y ∣ x ) ) log(L(W) )= ∑_{x,y}{P^-(x,y)}log(P_W(y|x)) log(L(W))=x,y∑P−(x,y)log(PW(y∣x))
为了使用梯度下降算法,我们令 f ( w ) = − l o g ( L ( W ) ) f(w)=-log(L(W)) f(w)=−log(L(W)),则有下面的公式为:
f ( w ) = − ∑ x , y P − ( x , y ) l o g ( P W ( y ∣ x ) ) = − ∑ x , y l o g Z w ( x ) − ∑ x , y P − ( x , y ) ∑ m = 1 M w m f m ( x , y ) = ∑ x p − ( x ) l o g ∑ y e x p ∑ m = 1 M w m f m ( x , y ) − − ∑ x , y P − ( x , y ) ∑ m = 1 M w m f m ( x , y ) f(w)=- ∑_{x,y}{P^-(x,y)}log(P_W(y|x))=- ∑_{x,y}logZ_w(x)-∑_{x,y}P^-{(x,y)}∑_{m=1}^Mw_mf_m(x,y)=\\ ∑_xp^-(x)log∑_yexp∑_{m=1}^Mw_mf_m(x,y)--∑_{x,y}P^-{(x,y)}∑_{m=1}^Mw_mf_m(x,y) f(w)=−x,y∑P−(x,y)log(PW(y∣x))=−x,y∑logZw(x)−x,y∑P−(x,y)m=1∑Mwmfm(x,y)=x∑p−(x)logy∑expm=1∑Mwmfm(x,y)−−x,y∑P−(x,y)m=1∑Mwmfm(x,y)
对W求导之后有:
∂ L ( w ) ∂ w = ∑ x , y P − ( x ) P w ( y ∣ x ) f ( x , y ) − ∑ x , y P − ( x , y ) f ( x , y ) \frac{∂L(w)}{∂w}=∑_{x,y}P^-(x)P_w(y|x)f(x,y)-∑_{x,y}P^-(x,y)f(x,y) ∂w∂L(w)=x,y∑P−(x)Pw(y∣x)f(x,y)−x,y∑P−(x,y)f(x,y)
在确定了梯度下降算法之后,就可以利用梯度下降算法来迭代求解最优的W了。
3、参考
1.刘建平 条件随机场CRF(三)模型学习与维特比算法解码