蓝桥杯基础入门——STL之容器
蓝桥杯基础入门——STL之容器
STL(Standard Template Library),即C++的标准模板库,是一个容器和算法的类库。容器往往包含同一类型的数据。STL中常用的容器有vector、map、和set。接下来我们一起来看看这些容器的用法吧。
- vector
1)简介
一个vector类似于一个动态的一维数组,vector中可以存在重复的元素。
2)头文件
#include3)声明
vector<int>a //声明一个元素为int类型的vector容器a
vector<mytype>b //声明一个元素为自定义类型mytype的vector容器b
vector<int>c(100,0)//声明一个已经存放了100个0的整数vector
vector<int>::iterator it//声明一个vector的迭代器
上述声明中,vector a、b包含0个元素,即a.size()、b.size()的值为0,而c包含100个元素,c.size()的值为100。虽然它们初始声明时的大小不同,但是它们是动态的,其大小会随着数据的插入和删除而改变。
4)常用函数
vector<int>a; //定义一个vector
a.size(); //返回vector包含的元素个数,即vector的大小
a.pop_back(); //删除vector末尾的元素
a.push_back(); //在vector的末尾添加元素
a.back(); //返回vector末尾的元素
a.clear(); //将vector清空,vector大小变为0
a.begin(); //找到数据头的指针
a.end(); //找到数据最后一个单元+1的指针
a.at(); //得到编号位置的数据
a.erase(); //删除指针指向数据项
a.rbegin(); //返回vector翻转后的数据头指针,即原来的end-1
a.rend(); //返回vector翻转后的结束指针,即原来的begin-1
a.empty(); //判断vector是否为空
a.swap(); //与另一个vector交换数据
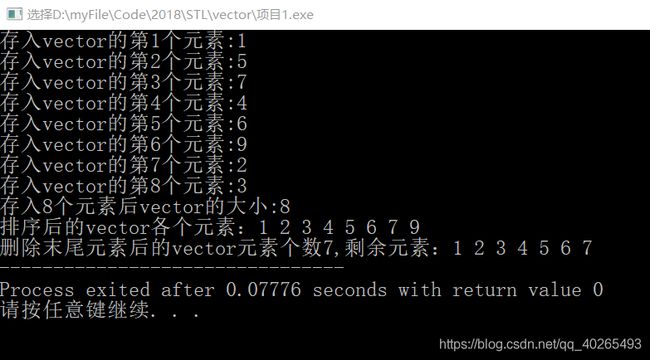
5)常用函数使用效果
程序:
#include 运行结果:
2. map
1)简介
map是STL的一个关联容器,它提供一对一的数据处理能力。(map由两个值组成,第一个值称为关键字,每个关键字只能在map中出现一次,第二个称为该关键字的值)。map内部的实现,自建一颗红黑树(一种非严格意义上的平衡二叉树),这颗树具有自动排序功能。
那么什么是一对一的数据映射呢?比如我们可以用map存放某班各科期末考试成绩及格人数,课程名语、数、英即为关键字,对应的及格人数即为关键字的一对一的映射。
2)头文件
#include
3)声明
map<int,string>a;
map<string,int>a;
map<int,string>::iterator it//定义一个map的迭代器
上述两种都是map容器的声明方式,但是效果不一样哟,放在第一位的是关键字的类型
4)数据的三种插入方法
map<int,string>a;
//第一种:insert 插入pair数据
a.insert(pair<int,string>(1,"hello"));
//第二种:insert 插入value_type数据
a.insert(map<int,string>::value_type(1,"hello"));
//第三种:数组插入数据
a[1]="hello";
a[2]="world";
map<string,int>b;
string s;
b[s]=1;//or b[s]++;
以上三种方法都可以插入数据,但是三者是有区别的。第一第二种方法在效果上是完全一样的。insert方式插入数据,涉及集合的唯一性,当map中存在这个关键字时,insert不能再插入此数据。而数组方式插入数据,可以覆盖该关键字对应的值。
5)数据的三种查找方式
方法一:count函数判断关键字是否出现,但无法定位数据出现的位置
方法二:find函数定位数据出现的位置,返回一个迭代器。map中含有该数据,则返回数据所在位置的迭代器,否则返回的迭代器等于end函数返回的迭代器(即最后一位元素的后一位)
方法三:lower_bound与up_bound的结合使用
map<int,string>a;
a.lower_bound();//返回要查找关键字的下界的迭代器,>=关键字
a.upper_bound();//返回要查找关键字的上界的迭代器,>关键字
a.equal_range();//返回一个pair,pair第一个变量是lower_bound返回的迭代器,第二个变量返回的是upper_bound返回的迭代器
//例如map中插入1,2,3,4,5,6,则lower_bound(3)返回3所在位置,upper_bound(3)返回4所在位置
//判断数据是否出现
mypair=a.equal_range(3);//这里假设3为我们要查找的数据
if(mypair.first==mypair.second)
printf("No\n");
6)数据的删除
方法一:迭代器删除法
it=a.find(1);
a.erase(it);
方法二:关键字删除法
int n=a.erase(1);//删除成功返回1,否则返回0
方法三:迭代器成片删除法
a.erase(a.begin(),a.end());//注意,成片删除的特性,也是STL的特性,删除区间前闭后开,与排序一样哟
7)其他常用函数
map<int,string>a;
a.size(); //返回map中所含元素个数
a.clear(); //数据的清空,多组数据输入时,使用map前要先进行数据清空
a.empty(); //判断map是否为空
- set
1)简介
set是集合,集合中不会包含重复的元素。set的涵义是集合,因此它是一个有序的容器,里面的元素都是排序好的,支持插入、删除、查找等操作,所有操作都在严格在O(logn)时间内完成的,效率非常高。set和multiset的区别是:set插入元素不能相同,但multiset可以。
2)头文件
#include3)声明
set<int>a;
set<int>::iterator it//声明一个set的迭代器
multiset<int>::iterator it//声明一个multiset的迭代器
4)常用函数
set<int>a; //定义一个set
a.size(); //返回set包含的元素个数,即set的大小
a.begin(); //返回指向第一个元素的迭代器
a.clear(); //清空所有数据
a.count(); //返回某个元素的个数
a.empty(); //判断集合是否为空
a.end(); //返回指向最后一个元素的迭代器
a.equal_range();//返回集合中与给定值相等的上下限的两个迭代器
a.erase(); //删除集合中的元素
a.find(); //返回一个指向被查找元素的迭代器
a.insert(); //在集合中插入数据
a.lower_bound();//指向大于或等于某值的第一个元素的迭代器
a.upper_bound();//指向大于某值的第一个元素的迭代器
a.rbegin(); //集合中最后一个元素的反向迭代器
a.rend(); //集合中第一个元素的反向迭代器
a.swap(); //交换两个集合变量