pytorch自然语言处理基础模型之一:NNLM
任务描述:pytorch实现简单的神经网络语言模型NNLM
一、数据
sentences=[‘i like dog’, ‘i love coffee’, ‘i hate milk’]
二、目标
当输入[‘i’,‘like’], [‘i’,‘love’], [‘i’,‘hate’]时,分别预测下一个单词为[‘dog’], [‘coffee’],[‘milk’]
三、完整代码
1. 导入需要的库,设置数据类型
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
dtype = torch.FloatTensor
2. 分词,创建字典
sentences = ['i like dog', 'i love coffee', 'i hate milk']
words = ' '.join(sentences).split()
words_dict = list(set(words))
num2word = {index:word for index, word in enumerate(words_dict)}
word2num = {word:index for index, word in enumerate(words_dict)}
3. 准备数据
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
input = [word2num[w] for w in word[:-1]]
target = word2num[word[-1]]
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
input_batch,target_batch = make_batch(sentences)
input_batch = Variable(torch.LongTensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch))
4. 创建网络
class NNLM(nn.Module):
def __init__(self):
super().__init__()
self.emb = nn.Embedding(n_class, embedding_size)
self.H = nn.Parameter(torch.randn(n_word*embedding_size, n_hidden).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.W = nn.Parameter(torch.randn(n_word*embedding_size, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self, x):
X = self.emb(x)
X = X.view(-1, n_word*embedding_size)
tanh = torch.tanh(torch.mm(X, self.H) + self.d)
return torch.mm(tanh, self.U) + torch.mm(X, self.W) + self.b
5. 设置网络参数
n_class = len(words_dict)
embedding_size = 10
n_word = 2 #表示每句话中作为输入的单词数
n_hidden = 2 #隐藏层个数,可以自行设置
6. 定义损失函数和优化方法,训练模型
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=0.001)
for epoch in range(1, 5000):
optimizer.zero_grad()
predict = model(input_batch)
loss = loss_fn(predict, target_batch)
if epoch%500== 0:
print('epoch:%d loss:%f' % (epoch, loss))
loss.backward()
optimizer.step()
7. 训练结果如下:
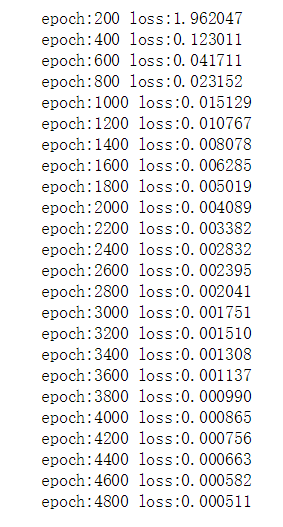
8. 训练好的模型生成预测结果
prediction = model(input_batch).data.max(1,keepdim=True)[1]
print([sen.split()[:2] for sen in sentences], '->', [num2word[n.item()] for n in prediction])
9. 结果
没有测试集,所以看看就好……
[['i', 'like'], ['i', 'love'], ['i', 'hate']] -> ['dog', 'coffee', 'milk']
参考链接
https://github.com/caijie12138/CS224n-2019