利用pytorch简单实现LSTM
利用pytorch简单实现LSTM
LSTM的概念
通过观看李宏毅的RNN视频 视频链接
july关于LSTM的讲解 博客链接
基本了解了LSTM的概念和原理
我觉得两张图就足以概括LSTM
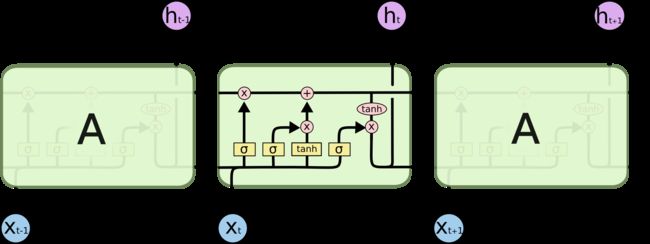
这张图完全展示了LSTM前向反向传播的全部过程, 想深入了解的可以参考july的博客
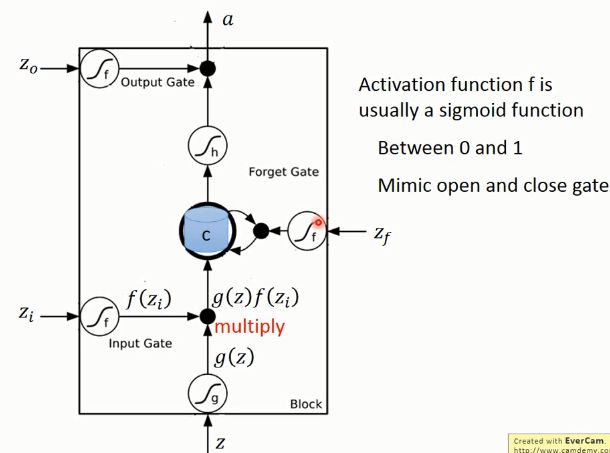
这是李宏毅老师视频里面的一张图,清晰得展示了forget Gate, inputGate, output Gate在网络中的
位置和作用,中间的圆柱体是memory cell,记忆单元,我感觉翻译成细胞单元不太贴切。Z0,Zi,Z,Zf都
是靠Xt + ht-1通过 sigmoid激活函数产生的门信号
pytorch简单实现LSTM
实现一个简单的词性标注 参考链接
#导入相应的包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
#准备数据的阶段
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
#DET 限定词, NN 名词 V 动词
training_data = [
("The dog ate the apple".split(), ["DET", "NN", "V", "DET", "NN"]),
("Everybody read that book".split(), ["NN", "V", "DET", "NN"])
]
word_to_ix = {}
for sent, tags in training_data:
for word in sent:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
print(word_to_ix)
#{'The': 0, 'dog': 1, 'ate': 2, 'the': 3, 'apple': 4, 'Everybody': 5, 'read': 6, 'that': 7, 'book': 8}
tag_to_ix = {"DET": 0, "NN": 1, "V": 2}
#词向量的维度
EMBEDDING_DIM = 6
#隐藏层的单元数
HIDDEN_DIM = 6
class LSTMTagger(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):
super(LSTMTagger, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
# The LSTM takes word embeddings as inputs, and outputs hidden states
# with dimensionality hidden_dim.
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
# The linear layer that maps from hidden state space to tag space
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
lstm_out, _ = self.lstm(embeds.view(len(sentence), 1, -1))
tag_space = self.hidden2tag(lstm_out.view(len(sentence), -1))
tag_scores = F.log_softmax(tag_space, dim=1)
return tag_scores
#定义了一个LSTM网络
#nn.Embedding(vocab_size, embedding_dim) 是pytorch内置的词嵌入工具
#第一个参数词库中的单词数,第二个参数将词向量表示成的维数
#self.lstm LSTM层,nn.LSTM(arg1, arg2) 第一个参数输入的词向量维数,第二个参数隐藏层的单元数
#self.hidden2tag, 线性层
#前向传播的过程,很简单首先词嵌入(将词表示成向量),然后通过LSTM层,线性层,最后通过一个logsoftmax函数
#输出结果,用于多分类
model = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix))
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
#训练过程
for epoch in range(300):
for sentence, tags in training_data:
#梯度清零
model.zero_grad()
#准备数据
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = prepare_sequence(tags, tag_to_ix)
#前向传播
tag_scores = model(sentence_in)
#计算损失
loss = loss_function(tag_scores, targets)
#后向传播
loss.backward()
#更新参数
optimizer.step()
#测试过程
with torch.no_grad():
inputs = prepare_sequence(training_data[0][0], word_to_ix)
tag_scores = model(inputs)