条件随机场(Conditional Random Field)简介
条件随机场(CRF)由Lafferty等人于2001年提出,是一种判别式概率模型,在许多自然语言处理任务中比如分词,命名实体识别等表现尤为出色。本篇与lafferty原始论文相同,将着重介绍条件随机场的一种特殊形式——线性链条件随机场(Linear Chain CRF)。
为什么需要CRF
作为Motivation,我们考虑如下词性标注任务:
对于一段输入文字“The dog barks”,我们希望获得他的词性标注“The/D(冠词) dog/N(名词) barks/V(动词)”。也就是对于一段输入序列 x⃗ =[x1,x2,....,xn] ,我们希望获得相应的特定任务的输出序列 s⃗ =[s1,s2,...,sn] 。比如刚刚举的词性标注例子,此时 xn 将对应字典集 V 里面的词, sn 则是词性集 S 里面的元素
一个解决方案——MEMM
为了解决上述问题,一个解决思路是建立一个条件概率模型:
McCallum等人为了解决HMM模型表达能力的局限性,于2000年提出了MEMM(Maximum Entropy Markov Model),该模型如下:
MEMM做了一个假设,就是状态的转移仅仅依赖于上一状态(这里我将标注标签称为一种状态)。在这样的假设下,转移概率被定义为:
其中 f(si,si−1,x⃗ ) 是特征函数,作用是将当前状态和上一状态连同输入映射为一个数值向量:
w⃗ 是权重向量,是模型的参数。通过这样定义,可以很容易求解模型参数 w⃗ ,并用viterbi算法求出该模型下的最优序列 s⃗ 。
Label Bias Problem
MEMM虽然可以很优雅地解决上述问题,然而却存在一个重大缺点,也就是所谓的“标注偏好”问题。什么是标注偏好呢?那就是模型在为输入序列 x⃗ 打标签的时候,存在偏袒心里,会倾向于选择某些标签。且看stanford大学的一个PPT:
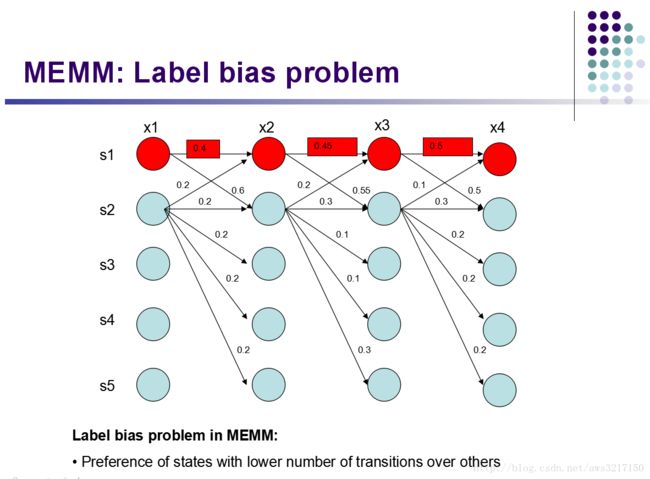
从图中可以观察,局部状态转移时, s1 倾向于转移到 s2 ,而 s2 倾向于停留在 s2 , 但是最终最好的序列却是: s1,s1,s1,s1 (0.4*0.45*0.5=0.09取得最大概率!)。为什么会这样呢?注意到 s1 只有两种转移状态: s1,s2 ,而 s2 有5种转移状态: s1,s2,s3,s4,s5 。对于 s1 的转移概率,由MEMM的定义,可得:
而对于 s2 的转移概率计算则是:
说明什么问题呢?因为 s1 的转移状态很少,所以不管实际训练观测值有多少,由于每一步的状态转移概率都要归一化,所以 s1 的转移概率都会被放大,而 s2 由于转移状态多,因此每一步转移概率归一化的时候都被平均分摊了。因此在计算最优序列的时候,MEMM会偏袒那些状态转移少的标签,而忽略了实际观察值,为了说明该现象,我们再举出原始论文的例子,如下图:
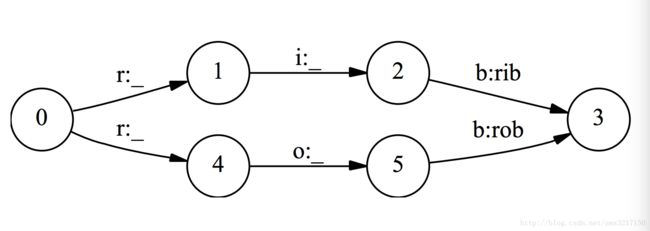
假设我们有一个辨别单词的状态机,对于单词rib和rob,从字母r出发分出两条边,经过i和o,最后到达b。对于MEMM,它对于一个单词 x 判断是rib的概率为:
判断为rob的概率为:
注意到 p(b|i,x)=p(b|o,x)=1 ,因为这些状态的转移都只有一条边,所以必然转移到下一个状态,那么只要训练数据中rob更加多,也就是 p(i|r,x)<p(o|r,x) 那么在预测阶段,预测值将始终是rob,而不管实际观测值 x 。
CRF
为了解决Label Bias Problem,CRF便诞生了。首先我们必须明确MEMM产生Label Bias的根源是什么,这是因为MEMM的状态转移概率的计算方式,为了获得转移概率,它每一步的状态转移都会进行归一化,从而导致问题的产生。CRF认清了问题的根源,只要不要在每一步状态转移进行归一化,而在全局进行归一化即可:
CRF相对于MEMM做了几个改动,首先在特征函数上面做了变动:
它将输入序列 x⃗ 和输出标注 s⃗ 映射为一个d维实数向量,而MEMM的特征函数拥有的信息只是输入序列 x⃗ 和当前状态以及上一个状态,也就是说CRF的特征函数掌握信息量更多,从而表达能力更强。第二个的改进是它不再每一次状态转移进行归一化,而是在全局进行归一化,这样完美解决Label Bias问题。
有得必有失,注意到模型的分母需要罗列所有的状态序列,对于序列长度为 n 的输入序列,状态序列的个数为 |S|n ,对于这种指数增长问题,在实际应用中一般都是intractable的,只能付诸于近似求解,比如我们之前提过的Variational Bayes或者Gibbs Sampling等等。不过有一种特殊结构的CRF,精确快速求解的方式是存在的,因此在早期得以广泛应用。
Linear Chain CRF
此处揭晓我们的主角——线性链CRF。熟悉概率图模型的同学可以一睹它的容貌:
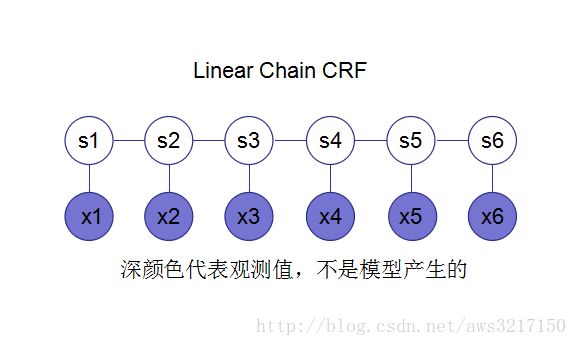
对于这样的无向图,通过定义特征函数 Φ ,可以将原来intractable的问题变为tractable。我们来看看到底是如何定义的:
对于第 k 维的特征函数值则记录为:
通过这样巧妙的定义: 全局特征等于局部特征的和,一切阻碍都迎刃而解!
参数估计
接下来我们介绍对于Linear Chain CRF如何进行参数参数估计的。假设我们有训练集 x1→,x2→,...,xN→ ,对应的标注集合 s1→,s2→,...,sN→ ,那么其对应的对数似然函数为:
对 wj 进行求导可得:
问题出现在上面减号的右半部分,我们单独讨论(为了记号方便,我们省去上标 i ):