(人脸属性迁移)分类属性约束:AttGAN、StarGAN
前言
介绍这两篇论文之前先说点新手感悟,本来觉得梳理论文的博客就是把论文的关键要点收纳一下,但当我回顾之前写的博客时,发现有很多遗漏之处,这也反映出了自己看论文时思考得不全面,之前看论文只关注别人的模型是如何搭建的,自以为是地忽略课题发展的来龙去脉,这对于小白寻找创新是不利的。为了让学习更加呈体系,以后的梳理工作我会尽可能把相似的思想进行对比介绍,尽可能输出一些自己的思考,而不是单纯地搬运翻译。
在以往的方法中,由于属性间具有较强的关联的缘故,生成结果会存在许多不理想的结果。例如,因为训练集中大部分金发对象都是女性,即“金发”和“女性”高度关联,所以“添加金发”的操作会顺带把男性转换成女性,如下图所示。这两篇在处理image2image迁移方面的做法十分相似,尽管术语表示不同,但共同点都是引入了一个分类器,通过分类回馈把关联性较强的属性区分开。

AttGAN
文献全称:AttGAN: Facial Attribute Editing by Only Changing What You Want
文献出处:IEEE Transactions on Image Processing, 2019, 28(11): 5464-5478.(arXiv: Computer Vision and Pattern Recognition, 2017.)
数据集:CelebA
论文贡献(亮点)
- 引入了属性分类约束
- 通过消融实验,验证了特征不变性(attribute-indenpent constraint)会限制编码器的编码能力,造成信息损失。
实验效果图

模型框架图
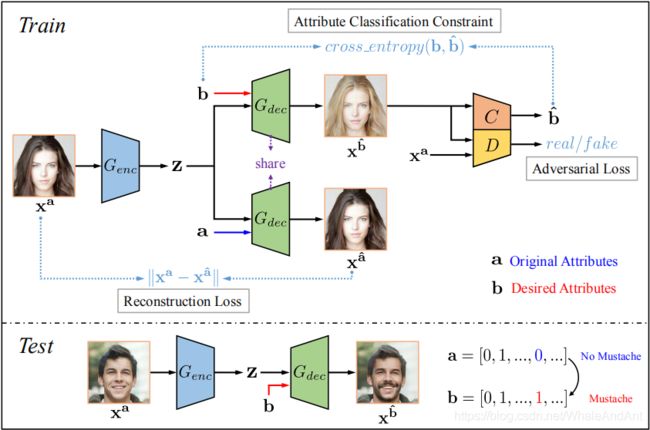
主要思想
这篇文章相当于是一个多任务学习模型,其中包括三部分:属性分类约束、重构学习和对抗学习。属性分类约束则是保证人脸属性编辑正确的关键,作者通过改变属性约束来实现人脸属性的编辑,网络架构中引入分类器来对编辑后的生成图片做出属性分类判断,使用交叉熵作为训练目标。
损失函数
重构属性向量表示为 a \bf a a=[ a 1 , . . . , a n a_{_1},...,a_{_n} a1,...,an],编辑属性向量表示为 b \bf b b=[ b 1 , . . . , b n b_{_1},...,b_{_n} b1,...,bn],其中 a i , b i a_{_i},b_{_i} ai,bi表示第i个属性的二元标签(0/1).
1.属性分类约束
(a)用新特征 b \bf b b生成新图像的属性分类约束
L c l s g = E x a ~ p d a t a , b ~ p a t t r [ l g ( x a , b ) ] L_{cls_g}=E_{x^a~p_{data}, b~p_{attr}}[l_g(x^a,b)] Lclsg=Exa~pdata,b~pattr[lg(xa,b)] l g ( x a , b ) = ∑ i = 1 n − b i l o g C i ( x b ^ ) − ( 1 − b i ) l o g ( 1 − C i ( x b ^ ) ) l_g(x^a,b)=\sum_{i=1}^n-b_ilogC_i(x^{\hat b})-(1-b_i)log(1-C_i(x^{\hat b})) lg(xa,b)=i=1∑n−bilogCi(xb^)−(1−bi)log(1−Ci(xb^)) 其中 C i C_i Ci表示为分类器对第i个属性的分类结果。
(b)用原属性 a \bf a a重构的属性分类约束
L c l s c = E x a ~ p d a t a [ l r ( x a , a ) ] L_{cls_c}=E_{x^a~p_{data}}[l_r(x^a,a)] Lclsc=Exa~pdata[lr(xa,a)] l r ( x a , a ) = ∑ i = 1 n − a i l o g C i ( x a ) − ( 1 − a i ) l o g ( 1 − C i ( x a ) ) l_r(x^a,a)=\sum_{i=1}^n-a_ilogC_i(x^a)-(1-a_i)log(1-C_i(x^a)) lr(xa,a)=i=1∑n−ailogCi(xa)−(1−ai)log(1−Ci(xa))
2.重构损失
L r e c = E x a ~ p d a t a [ ∣ ∣ x a − x a ^ ∣ ∣ 1 ] L_{rec}=E_{x^a~p_{data}}[||x^a-x^{\hat a}||_{_1}] Lrec=Exa~pdata[∣∣xa−xa^∣∣1]
重构函数使用的是L1范数来抑制模糊现象,而不是用L2范数。(存疑待解决.)
3.生成器损失
L a d v g = − E x a ~ p d a t a , b ~ p a t t r [ D ( x b ^ ) ] L_{adv_g}=-E_{x^a~p_{data},b~p_{attr}}[D(x^{\hat b})] Ladvg=−Exa~pdata,b~pattr[D(xb^)]
4.判别器损失
L a d v d = − E x a ~ p d a t a D ( x a ) + E x a ~ p d a t a , b ~ p a t t r [ D ( x b ^ ) ] L_{adv_d}=-E_{x^a~p_{data}}D(x^a)+E_{x^a~p_{data},b~p_{attr}}[D(x^{\hat b})] Ladvd=−Exa~pdataD(xa)+Exa~pdata,b~pattr[D(xb^)] 这里的对抗损失采用的是WGAN-GP.
总目标
L e n c , d e c = λ 1 L r e c + λ 2 L c l s g + L a d v g L_{enc,dec}=\lambda_1L_{rec}+\lambda_2L_{cls_g}+L_{adv_g} Lenc,dec=λ1Lrec+λ2Lclsg+Ladvg
这部分为分类约束+重构损失+对抗损失,可以编辑属性同时保留非编辑属性之外的其他细节。
L d i s , c l s = λ 3 L c l s c + L a d v d L_{dis,cls}=\lambda_3L_{cls_c}+L_{adv_d} Ldis,cls=λ3Lclsc+Ladvd这部分为判别器和分类器的损失函数,其中判别器和属性分类器共享了大部分的网络层。
实现细节
网络实现细节
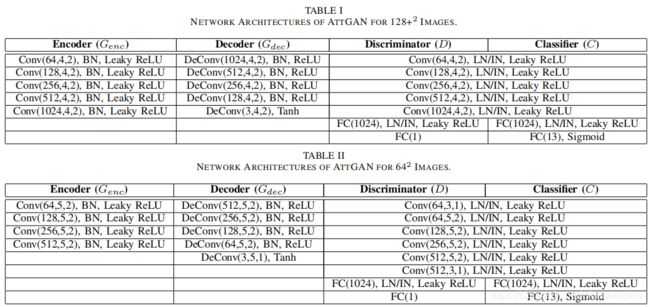
其中属性分类器 C C C和判别器共享所有的卷积层;
在encoder和decoder之间使用了U-Net的对称跳跃连接;
训练细节:
优化器:Adam,( β 1 = 0.5 , β 2 = 0.999 \beta_1=0.5,\beta_2=0.999 β1=0.5,β2=0.999, l r = 0.0002 lr=0.0002 lr=0.0002)
损失中的系数: λ 1 = 100 , λ 2 = 10 , λ 3 = 1 \lambda_1=100,\lambda_2=10,\lambda_3=1 λ1=100,λ2=10,λ3=1
部分实现细节
Q:编码向量 b b b是如何与潜在特征一块塞进解码器的?
A:这里的实现和Fader network有点相似,每个属性的标签是一个标量,相当于把这个标量扩展成一个张量,在这里则是扩展成和decoder中每层的特征图一样大的尺寸,即 [ N , 1 , 1 , c h a n n e l b ] → [ N , H m a p , W m a p , c h a n n e l m a p ] [N,1,1,channel_b]→[N,H_{map},W_{map},channel_{map}] [N,1,1,channelb]→[N,Hmap,Wmap,channelmap](tensorflow的4D tensor形式),然后将扩展后的标签和特征图在channel这个维度合并,即喂给decoder下一层的map张量形状为 [ N , H m a p , W m a p , c h a n n e l b + c h a n n e l m a p ] [N,H_{map},W_{map},channel_b+channel_{map}] [N,Hmap,Wmap,channelb+channelmap].
以下代码摘要:
# 利用该函数将特征map和标签进行合并
def tile_concat(a_list, b_list=[]):
# tile all elements of `b_list` and then concat `a_list + b_list` along the channel axis
# `a` shape: (N, H, W, C_a)
# `b` shape: can be (N, 1, 1, C_b) or (N, C_b)
a_list = list(a_list) if isinstance(a_list, (list, tuple)) else [a_list]
b_list = list(b_list) if isinstance(b_list, (list, tuple)) else [b_list]
for i, b in enumerate(b_list):
b = tf.reshape(b, [-1, 1, 1, b.shape[-1]])
b = tf.tile(b, [1, a_list[0].shape[1], a_list[0].shape[2], 1])
b_list[i] = b
return tf.concat(a_list + b_list, axis=-1)
# decoder中模型的实现部分
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
a = tf.to_float(a)
z = utils.tile_concat(zs[-1], a)
for i in range(n_upsamplings - 1):
d = min(dim * 2**(n_upsamplings - 1 - i), MAX_DIM)
z = dconv_norm_relu(z, d, 4, 2)
if shortcut_layers > i:
z = utils.tile_concat([z, zs[-2 - i]])
if inject_layers > i:
z = utils.tile_concat(z, a)
x = tf.nn.tanh(dconv_(z, 3, 4, 2))
# 训练中的部分代码
xa, a = train_iter.get_next()
b = tf.random_shuffle(a) # 将a打乱生成b
z = Genc(xa)
xa_ = Gdec(z, a_)
xb_ = Gdec(z, b_)
其他扩展/尝试
属性样式篡改
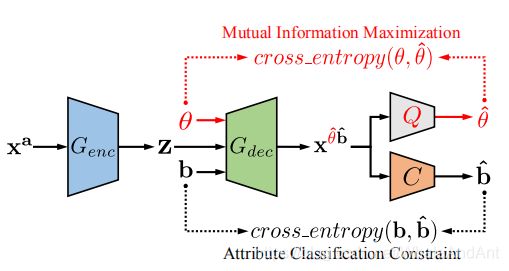
因为使用的训练集中标签是二元的,比如眼镜只有“佩戴”和“未佩戴”两种状态,而不能选择具体的眼镜样式。为了解决这个问题,引入了InfoGAN中的样式控制向量,属性的样式可表示为 θ = [ θ 1 , . . . , θ i , . . . θ n ] \theta=[\theta_1,...,\theta_i,...\theta_n] θ=[θ1,...,θi,...θn],其中 θ i \theta_i θi表示第i个属性的样式。InfoGAN中的观点为,传统的GAN模型会忽略掉直接输入的样式控制向量,因此需要在样式向量和输出图片之间建立起交互信息,通过最大化交互信息来使得两者具有较强的关联性。
所以在网络结构中将引入样式控制向量 θ \theta θ和样式预测器 Q Q Q,网络结构如下图所示,公式可表示为:
x θ ^ b ^ = G d e c ( G e n c ( x a ) , θ , b ) x^{\hat \theta \hat b}=G_{dec}(G_{enc}(x^a),\theta,b) xθ^b^=Gdec(Genc(xa),θ,b) 其中 x θ ^ b ^ x^{\hat \theta \hat b} xθ^b^表示既具有属性 b b b,又具有样式 θ \theta θ的生成图片. I ( θ , x ∗ ) = max Q E θ ~ p ( θ ) , x ∗ ~ p ( x ∗ ∣ θ ) [ l o g Q ( θ ∣ x ∗ ) ] + c o n s t I(\theta,x^*)=\max_Q E_{\theta~p(\theta),x^*~p(x^*|\theta)}[logQ(\theta|x^*)]+const I(θ,x∗)=QmaxEθ~p(θ),x∗~p(x∗∣θ)[logQ(θ∣x∗)]+const max G e n c , G d e c I ( θ ; x ∗ ) \max_{G_{enc},G_{dec}}I(\theta;x^*) Genc,GdecmaxI(θ;x∗) 其中 I ( θ , x ∗ ) I(\theta,x^*) I(θ,x∗)表示为样式向量和输出图片的交互信息。
效果图:

属性密度控制(Attribute Intensity Control)
虽然AttGAN是使用二元标签(0/1)进行训练的,但是使用连续的值 [ 0 , 1 ] [0,1] [0,1]作为输入,生成图像的逐渐变化是平滑自然的。


消融实验
行(2),(3):结果只是重构。(2)是去掉属性分类约束,没有刺激网络生成正确属性的信号;(3)是去掉对抗损失,一种可能的原因是生成了一个对抗样本,因此虽然属性分类约束还在,但不具备正确属性的对抗样本仍然可以通过噪声来愚弄分类器。
行(4):生成结果中,face id产生了一些变化。这说明重构函数可以保留非编辑属性的细节。
行(5)(6):测试independent constraint,结果中存在虚假的效果(artifacts),并且face identity有所改变。因为约束编码的表现能力会导致信息损失,近而降低了生成图的质量。

StarGAN
文献全称:StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
文献出处:[C]. computer vision and pattern recognition, 2018([J]. arXiv: Computer Vision and Pattern Recognition, 2017.)
数据集:CelebA、RaFD
论文贡献(亮点)
- 不像以往的方法只能在两个域之间做迁移,该方法使用一个生成器就可以完成多个域之间的映射。
- 使用一个掩码向量来控制可用的域标签(domain label),近而学习跨域的图像迁移任务。
实验效果图

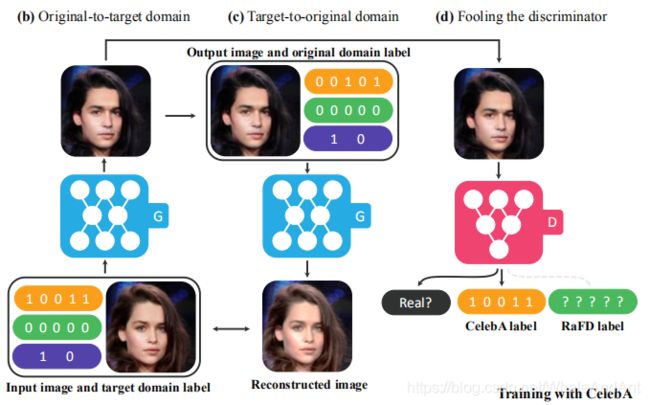
模型框架图

概念解释
刚听到“域”的概念,只能模糊地去意会,而作者在论文中对这个术语做了具体说明。
- 属性:图片中有实际意义的特征,这些特征是图片所固有的,例如发色、性别和年龄等。
- 属性值:一个属性的特定值,例如:
- 发色:黑发、金发、棕发
- 性别:男、女
- 域(domain):具有相同属性值的图像集合。
主要思想
该方法使用目标域标签向量作为条件约束,生成器的输入为目标域标签向量和源图片,通过一个辅助的分类器使得判别器能够控制多个域。使用n维的one-hot标签向量来表示特征,可以整合多个数据集,论文实验整合CelebA数据集来提供人物面容特征,整合RaFD来提供面部表情特征。
损失函数
判别器的映射可表示为 x → { D s r c ( x ) , D c l s ( x ) } x→\lbrace D_{src}(x),D_{cls}(x)\rbrace x→{Dsrc(x),Dcls(x)},其中 D s r c D_{src} Dsrc表示源图片的概率分布, D c l s D_{cls} Dcls表示域标签的概率分布。
损失函数主要分为三部分:对抗损失、域分类损失、重构损失。
对抗损失
L a d v = E x [ l o g D s r c ( x ) ] − E x , c [ l o g ( D s r c ( G ( x , c ) ) ) ] − λ g p E x ^ [ ( ∣ ∣ ∇ x ^ D s r c ( x ^ ) ∣ ∣ 2 − 1 ) 2 ] L_{adv}=E_x[logD_{src}(x)]-E_{x,c}[log(D_{src}(G(x,c)))]-\lambda_{gp}E_{\hat x}[(||\nabla_{\hat x}D_{src}(\hat x)||_{_2}-1)^2] Ladv=Ex[logDsrc(x)]−Ex,c[log(Dsrc(G(x,c)))]−λgpEx^[(∣∣∇x^Dsrc(x^)∣∣2−1)2] 这里的对抗损失使用的是带梯度惩罚的Wasserstein GAN目标函数。
域分类损失
L c l s r = E x , c ′ [ − l o g D c l s ( c ′ ∣ x ) ] L_{cls}^r=E_{x,c'}[-logD_{cls}(c'|x)] Lclsr=Ex,c′[−logDcls(c′∣x)] 真图片的域分类损失用于优化判别器D。
L c l s f = E x , c [ − l o g D c l s ( c ∣ G ( x , c ) ) ] L_{cls}^f=E_{x,c}[-logD_{cls}(c|G(x,c))] Lclsf=Ex,c[−logDcls(c∣G(x,c))] 假图片的域分类损失用于优化生成器G。
使用的损失函数为二元交叉熵。
重构损失
L r e c = E x , c , c ′ [ ∣ ∣ x − G ( G ( x , c ) , c ′ ) ∣ ∣ 1 ] L_{rec}=E_{x,c,c'}[||x-G(G(x,c),c')||_{_1}] Lrec=Ex,c,c′[∣∣x−G(G(x,c),c′)∣∣1] 为了保留输入图片的内容,这里使用循环重构函数,如框架图所示,这个过程会使用两次生成器。
总损失函数
L D = − L a d v + λ c l s L c l s r L_D=-L_{adv}+\lambda_{cls}L_{cls}^r LD=−Ladv+λclsLclsr L G = L a d v + λ c l s L c l s f + λ r e c L r e c L_G=L_{adv}+\lambda_{cls}L_{cls}^f+\lambda_{rec}L_{rec} LG=Ladv+λclsLclsf+λrecLrec
实现细节
训练策略
因为训练涉及两个数据集,所以在训练时,判别器每次只针对当前已知的标签,来最小化分类误差。例如,当训练是基于CelebA时,判别器最小化的目标只是与CelebA属性相关的分类误差,而不是RaFD。通过在CelebA和RaFD之间交替变换,判别器学到了两个数据集上的所有特征。

编码形式 c ~ = [ c 1 , . . . , c n , m ] \tilde c=[c_1,...,c_n,m] c~=[c1,...,cn,m],其中 c i c_i ci表示第i个数据集的one-hot标签向量, m m m表示当前训练的是哪个数据集的one-hot向量,文章的实现如上图所示,实现代码摘要:
def label2onehot(self, labels, dim):
"""Convert label indices to one-hot vectors."""
batch_size = labels.size(0)
out = torch.zeros(batch_size, dim)
out[np.arange(batch_size), labels.long()] = 1
return out
# CelebA数据集的标签向量,使用的是zeros
mask_celeba = self.label2onehot(torch.zeros(x_real.size(0)), 2)
c_org = torch.cat([c_org, zero, mask], dim=1)
# RaFD数据集的标签向量,使用的是ones
mask_rafd = self.label2onehot(torch.ones(x_real.size(0)), 2)
c_org = torch.cat([zero, c_org, mask], dim=1)
而在测试阶段,多数据集转换的代码只是分别在两个数据集上做转换,而没有将编码的mask部分为[1,1]来同时改变两个数据集上的属性,如果有机会复现的话,可以尝试一下。
网络实现
生成器:自编码器结构;残差块做瓶颈;使用的是InstanceNormalization;网络细节如下图所示。

判别器:使用PatchGAN结构;卷积层为(4,2,1)设置,即尺寸逐层减半;判别器和分类器共享卷积层,其中判别器结果为标量,分类器结果的形状为[batch_size,c_dim,1,1],也就是每个通道各代表一个属性的分类结果。

优化器:Adam, β 1 = 0.5 \beta_1=0.5 β1=0.5, β 2 = 0.999 \beta_2=0.999 β2=0.999
量化评价标准:Amazon Mechanical Turk(AMT);训练分类器对生成结果进行分类。
方法对比
AttGAN的实验部分展示了AttGAN和StarGAN的对比数据,分别对比了分类正确率和属性保留误差,量化实验对比如下图所示。相比起来,StarGAN的分类验证结果要优于AttGAN,但AttGAN的生成图片质量稍优于StarGAN.
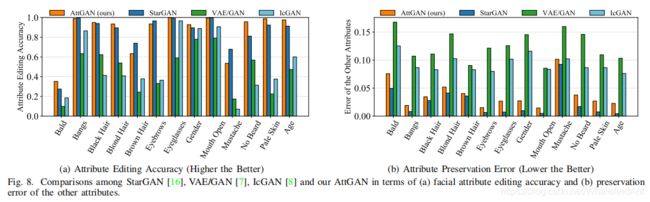

通过比较两者的模型框架图,我们可以发现,在自编码器部分,两者的差别只是标签向量的输入位置不同,AttGAN是从解码器部分传进网络,StarGAN是从编码器就传进了网络,个人推测有可能是因为标签向量在网络中传递的路径较长,使得StarGAN的分类效果要优于AttGAN.需要近一步做对比实验才能得到切实的结论。

后续更新内容
2020/03/060更新内容:
在19年的CVPR文章STGAN中,引入了属性差异向量 a t t d i f f {\bf att}_{_{diff}} attdiff,只输入需要改变的属性。 a t t d i f f = a t t t − a t t s {\bf att}_{_{diff}}={\bf att}_{_{t}}-{\bf att}_{_{s}} attdiff=attt−atts STGAN论文中对AttGAN和StarGAN做了对比实验,结果图如下所示,其中第一行的三个模型使用的是属性标签向量,第二行使用的是属性差异向量。
如先前所述,StarGAN的属性生成精度较高于AttGAN,但添加了属性差异向量之后,可以发现AttGAN的效果反超了StarGAN。目前仅发现了这个现象,但究其原因还不能给出明确的解释。
总结
- 通过在判别器结构中引入分类器,使其与标签向量建立交互信息,可以剥离属性间的关联性,生成较好的迁移效果。
- AttGAN的消融实验给出的启示是,对编码器上约束会限制其编码能力,造成信息损失,近而无法得到高质量的生成结果。
参考文献
- He Z, Zuo W, Kan M, et al. AttGAN: Facial Attribute Editing by Only Changing What You Want[J]. IEEE Transactions on Image Processing, 2019, 28(11): 5464-5478…
- Chen X, Duan Y, Houthooft R, et al. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets[J]. arXiv: Learning, 2016
- Lample G, Zeghidour N, Usunier N, et al. Fader Networks: Manipulating Images by Sliding Attributes[C]. neural information processing systems, 2017: 5967-5976
- Choi Y, Choi M, Kim M, et al. StarGAN: Unified Generative Adversarial Networks for Multi-domain Image-to-Image Translation[C]. computer vision and pattern recognition, 2018: 8789-8797.