Stacking思想的Python3代码再现
Stacking思想的代码再现
本文源于对Stacking思想的理解,尝试使用Python3.5,在Spyder中将其思想转化为代码实现,并将本文内容安排如下:
1.Stacking原理(宏观和微观解释)
2.使用本文Stacking代码测试Iris数据集
- Stacking原理图
1.1.网上广为接受的原理图:(宏观)
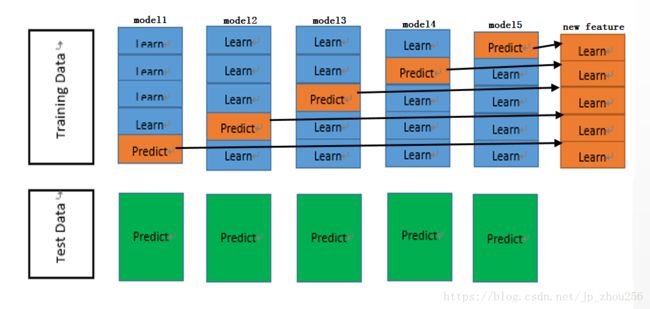
【宏观图】将训练集划分成了X_train和X_test两个集合。然后将X_train按k折交叉验证(这里k=5)来均等划分,蓝色的4折作为小的X_train’,橙色的1折作为小的X_test’,使用model1对X_train进行k=5的交叉验证,X_train’训练模型后使用,X_test’来做交叉验证的测试对模型进行调参。即:外圈循环为5个模型,内圈循环做5折交叉验证:5折中随机选定一折做小训练街,其余做测试集合,训练模型时,分别传入X_test’和整个X_test进行训练。如此重复划分和训练验证测试5次。针对每一个模型会有两个输出的label(即new feature):5组橙色的Learn和5组绿色的Predict。对于每一个模型预测出来的5组橙色的Learn沿着纵向拼接成一个列向量即;对于每一个模型预测出来的5组绿色的Predict将其取Average记为predict’;5个模型拼接出5组橙色的new feature,每组new feature由橙色的5个Learn纵向拼接成,将5组橙色的new feature沿着横向拼接起来作为新的new_feature_X_train。5个模型拼接出5组绿色的Predict,沿着横向进行拼接作为新的new_feature_X_test。
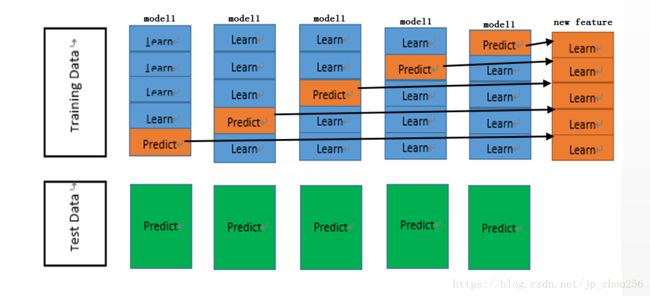
1.2.原理图剖析(微观)
为了方便读着理解如下将每个模型的内圈循环操作进行放大,方便理解,后续简称【局部图】。实质上就是一个k=5的k折交叉验证。 最后将每一次训练验证的label沿着列的方向重新拼接起来作为一整列的新特征。同步的由于每一轮交叉验证中X_test都会传入模型做预测产生了5组绿色的label列,这里对5组label列取平均记为predict’。
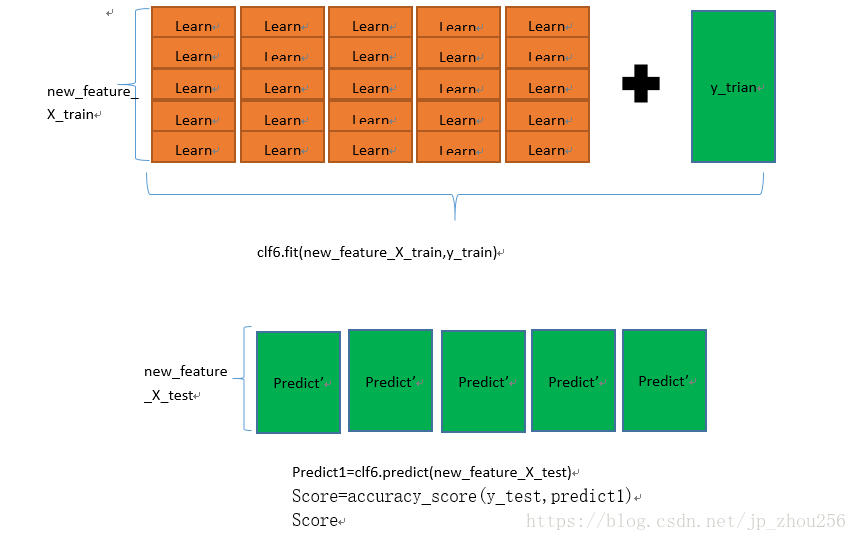
1.3.使用新的模型来训练训练集new_feature_X_train,传入标签为y_train,再将new_feature_X_test作为验证集,将验证的结果predict1与y_test做对比计算得分即可。定义第6个模型clf6来训练new_feature_X_train,并预测new_feature_X_test。详情如下图所示:
2.iris数据集上做验证测试
2.1.iris.data.shape=() #(150, 4)
即:iris.data中有150个样本,每个样本由一个4维属性构成的array数组来表示。现在现将iris.data划分数据集,均等换分为5份,即:X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=10),由此获得X_train.shape=(120,4),X_test.shape=(30,4);y_train.shape=(120,1),y_test.shape=(30,1)。按照局部图中的原理将X_train做k=5折交叉验证:将X_train,y_train都划分为5等份,每份120/5=24,随机选出一折作为小测试集X_test’(X_test’.shape=(24,4)),其余4折作为小训练集X_train’(X_train’.shape=(96,4))来训练模型,从y_train的5份划分中随机选一份作为训练标签y_train’(y_train’.shape=(24,4))。每一轮验证中clf.fit(X_train’,y_train’),
new_predict1=clf.predict(X_test’);#验证集是交叉训练的测试集
new_predict2=clf.predict(X_test); #验证集是原来的X_test的测试集
将每一轮的结果存入相应的list中以备拼接或者取平均用即可。
2.1.详细代码
"""Stacking 思想的实现"""
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cross_validation import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble.gradient_boosting import GradientBoostingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
import warnings
from numpy import hstack,vstack,array,nan
warnings.filterwarnings('ignore')
from sklearn import datasets
iris=datasets.load_iris()
X=iris.data #训练特征
Y=iris.target #测试特诊
#4:1是为了方便做交叉验证
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=10)
#归一化处理
ss=StandardScaler()
X_train=ss.fit_transform(X_train)
X_test=ss.transform(X_test)
#clf1=LogisticRegression()
#clf1.fit(X_train,y_train)
#y_predict=clf1.predict(X_test)
"""1.1.获得新特征"""
new_feature=[] #装每个模型产生的新特征列
new_label_test=[]
#模型模块
clf1=LogisticRegression()
#clf1.fit(XXXtrain,YYYtrain)
#y_predict=clf1.predict(XXXtest)
clf2=KNeighborsClassifier()
clf3=GaussianNB()
clf4=RandomForestClassifier()
#将训练集划分成5份
set_Train=[]
set_Test=[]
#将X_train和y_train拆成5折以备后续做5折交叉验证使用
for k in range(5):
span=int(X_train.shape[0]/5)
i=k*span
j=(k+1)*span
#将X_train和y_train均划分成为5分被后续交叉验证使用
set_Train.append(X_train[i:j])
set_Test.append(y_train[i:j])
model=[clf1,clf2,clf3,clf4]
#clf1.__class__.__bases__ #基本函数族
for index,clf in enumerate(model):
#print(index,'======',clf)
model_list=[] #将每一轮交叉验证的预测label存入其中,再转为array做转置.
label_list=[] #总的测试集对应的预测标签
#k折交叉验证
for k in range(5):
##选择做交叉验证的测试集
XXtest=[]
XXtest.append(set_Train[k])
#选择做交叉验证训练的训练集
XXtrain=[]
YYtest=[]
for kk in range(5):
if kk==k:
continue
else:
XXtrain.append(set_Train[kk])
YYtest.append(set_Test[kk])
#模型的训练
XXXtrain=array(vstack((XXtrain[0],XXtrain[1],XXtrain[2],XXtrain[3])))
YYYtrain=array(hstack((YYtest[0],YYtest[1],YYtest[2],YYtest[3])))
XXXtest=array(vstack(XXtest)) #XXtest.shape=1*24*4,不是想要的96x4
clf.fit(XXXtrain,YYYtrain)
y_predict=clf.predict(XXXtest)
model_list.append(y_predict) #将第k折验证中第k折为测试集的预测标签存储起来
test_y_pred=clf.predict(X_test)
label_list.append(test_y_pred)
#拼接数据集时候是hstack还是vstack可以试试看
new_k_feature=array(hstack((model_list[0],model_list[1],model_list[2],model_list[3],model_list[4]))) #hstack() takes 1 positional argument,所以参数使用一个tuple来封装
new_feature.append(new_k_feature)
new_k_test=array(vstack((label_list[0],label_list[1],label_list[2],label_list[3],label_list[4]))).T #hstack() takes 1 positional argument,所以参数使用一个tuple来封装
new_label_test.append(array(list(map(int,list(map(round,new_k_test.mean(axis=1)))))))
#将5个基模型训练好的预分类标签组合成为新的特征供后续使用(X_train')
newfeature_from_train=array(vstack((new_feature[0],new_feature[1],new_feature[2],new_feature[3]))).T #拼接完成后做转置
#将交叉验证获得的label拼接起来(X_test')
predict_from_test_average=array(vstack((new_label_test[0],new_label_test[1],new_label_test[2],new_label_test[3]))).T
"""1.3.meta_classifier 模型"""
clf5=GradientBoostingClassifier()
clf5.fit(newfeature_from_train,y_train)
predict1=clf5.predict(predict_from_test_average)
predict1
Score=accuracy_score(y_test,predict1)
Score
#result1: predict1
predict1
Out[152]:
array([1, 2, 0, 1, 0, 1, 2, 1, 0, 1, 1, 2, 1, 0, 0, 2, 1, 0, 0, 0, 2, 2,
2, 0, 1, 0, 1, 1, 1, 2])
#result2: Score
Score=accuracy_score(y_test,predict1)
Score
Out[153]: 0.9666666666666667
雷锋网:https://www.leiphone.com/news/201709/zYIOJqMzR0mJARzj.html
刘建平博客(非常多sklearn的好文章):https://www.cnblogs.com/pinard/p/9032759.html