练习7: 文件和数据格式化
练习7: 文件和数据格式化
1.1 文件行数
描述
打印输出附件文件的有效行数,注意:空行不计算为有效行数。
| 输入 | 输出 |
|---|---|
| 无 | 共100行 |
【参考代码】
f = open("latex.log")
s = 0
for line in f:
line = line.strip('\n')
if len(line) == 0:
continue
s += 1
print("共{}行".format(s))
需要注意:for line in
f方式获得的每行内容(在变量line中)包含换行符,所以,要通过strip()函数去掉换行符后再进行统计。这里,空行指没有字符的行。
1.2 文件字符分布
描述
统计附件文件的小写字母a-z的字符分布,即出现a-z字符的数量,并输出结果。
同时请输出文件一共包含的字符数量。
注意输出格式,各元素之间用英文逗号(,)分隔。
答案可能包含a-z共26个字符的分布,如果某个字符没有出现,则不显示,输出顺序a-z顺序。
| 输入 | 输出 |
|---|---|
| 无 | 共999字符,a:11,b:22,c:33,d:44,e:55 |
【参考代码】
f = open("latex.log")
cc = 0
d = {}
for i in range(26):
d[chr(ord('a')+i)] = 0
for line in f:
for c in line:
d[c] = d.get(c, 0) + 1
cc += 1
print("共{}字符".format(cc), end="")
for i in range(26):
if d[chr(ord('a')+i)] != 0:
print(",{}:{}".format(chr(ord('a')+i), d[chr(ord('a')+i)]), end="")
使用 ord(‘a’)+i 配合 range()函数 可以遍历一个连续的字符表。
1.3 文件独特行数
描述
统计附件文件中与其他任何其他行都不同的行的数量,即独特行的数量。
| 输入 | 输出 |
|---|---|
| 无 | 共99独特行 |
【参考代码】
f = open("latex.log")
ls = f.readlines()
s = set(ls)
for i in s:
ls.remove(i)
t = set(ls)
print("共{}独特行".format(len(s)-len(t)))
记住:如果需要"去重"功能,请使用集合类型。
ls.remove()可以去掉某一个元素,如果该行是独特行,去掉该元素后将不在集合t中出现。
1.4 CSV格式列变换
描述
附件是一个CSV文件,请将每行按照列逆序排列后输出,不改变各元素格式(如周围空格布局等)。
输入输出示例
这是一个格式示例,不是正确结果。

【参考代码】
f = open("data.csv")
for line in f:
line = line.strip("\n")
ls = line.split(",")
ls = ls[::-1]
print(",".join(ls))
f.close()
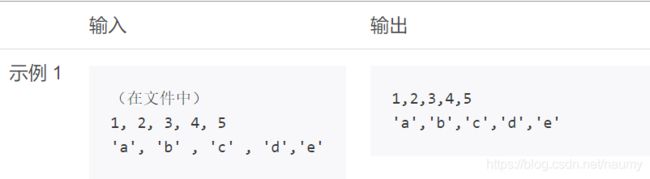
1.5 CSV格式数据清洗
描述
附件是一个CSV文件,其中每个数据前后存在空格,请对其进行清洗,要求如下:
(1)去掉每个数据前后空格,即数据之间仅用逗号(,)分割;
(2)清洗后打印输出。
【参考代码】
f = open("data.csv")
s = f.read()
s = s.replace(" ","")
print(s)
f.close()
该CSV文件的每个数据中不包含空格,因此,可以通过替换空格方式来清洗。如果数据中包含空格,该方法则不适用。