条件随机场CRF - 学习和预测
http://blog.csdn.net/pipisorry/article/details/78397567
CRF的学习
即CRF的参数估计问题。条件随机场模型实际上是定义在时序数据上的对数线性模型(LR模型同样是),其学习方法包括极大似然估计和正则化的极大似然估计。具体的优化实现算法有改进的迭代尺度法IIS、梯度下降法以及拟牛顿法。
改进的迭代尺度法(IIS)
已知训练数据集,由此可知经验概率分布 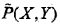 ,可以通过极大化训练数据的对数似然函数来求模型参数。
,可以通过极大化训练数据的对数似然函数来求模型参数。
训练数据的对数似然函数为(lz条件熵)
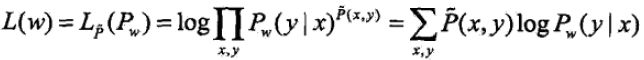
当Pw是条件随机场模型时

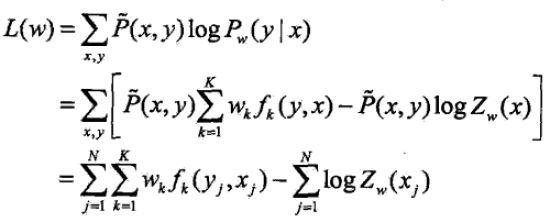
IIS通过迭代的方法不断优化对数似然函数改变量的下界,达到极大化对数似然函数的目的。
假设模型的当前参数向量为w=(w1,w2, ..., wK)T,向量的增量为δ=(δ1,δ2, ..., δK)T,更新参数向量为w +δ=(w1+δ1, w2 +δ2, ..., wk +δk)T。在每步迭代过程中,IIS通过一次求解下面的11.36和11.37,得到δ=(δ1,δ2, ..., δK)T。
关于转移特征tk的更新方程为:

关于状态特征sl的更新方程为:
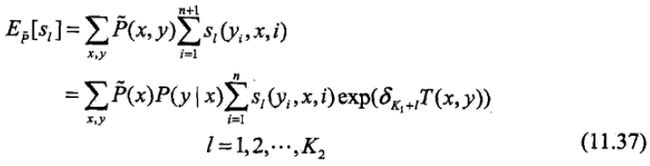
这里T(x, y)是在数据(x, y)中出现所有特征数的综合:

于是算法整理如下。
算法:条件随机场模型学习的改进的迭代尺度法
输入:特征函数t1,t2, ..., tK1,s1, s2, ..., sK2;经验分布
输出:参数估计值  ;模型
;模型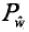 。
。
过程:

拟牛顿法
对于条件随机场模型

学习的优化目标函数是
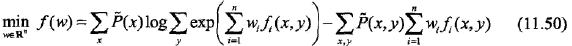
其梯度函数是
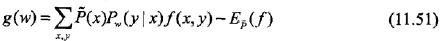
算法:条件随机场模型学习的BFGS算法(拟牛顿法)

前向后向算法
像隐马尔可夫模型那样,引进前向-后向向量,递归的计算以上概率及期望值。这样的算法称为前向-后向算法。
前向-后向算法
对每个指标i =0,1,...,n+1,定义前向向量ai(x):

递推公式为
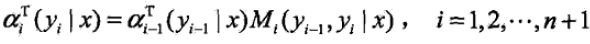
又可表示为

ai(yi|x)表示在位置i的标记是yi并且到位置i的前部分标记序列的非规范化概率,若yi可取的值有m个,那ai(x)就是m维的列向量。
同样,对每个指标i =0,1,...,n+1,定义后向向量βi(x):
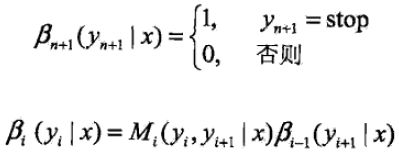
又可表示为

βi(yi|x)表示在位置i的标记为yi并且从i+1到n的后部分标记序列的非规范化的概率。
由前向-后向定义不难得到:
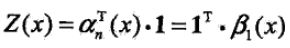
这里,若ai(x)是m维的列向量,那1就是元素均为1的m维列向量。
概率计算
按照前向-后向向量的定义,很容易计算标记序列在位置i是标记yi的条件概率和在位置i-1与i是标记yi-1和yi的条件概率:
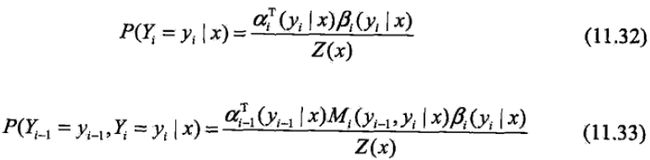
其中,
Z(x)= anT(x)·1
期望值计算
利用前向-后向向量,可以计算特征函数关于联合分布P(X, Y)和条件分布P(Y | X)的数学期望。
特征函数fk关于条件分布P(Y |X)的数学期望是
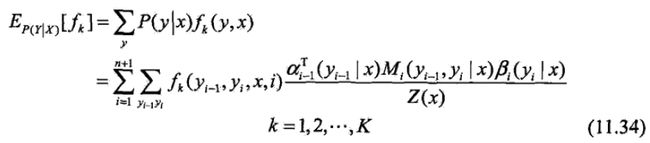
其中,
Z(x)= anT(x)·1
假设经验分布为
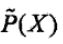
则特征函数fk关于联合分布P(X, Y)的数学期望是

其中,
Z(x)= anT(x)·1
式11.23和式11.35是特征函数数学期望的一般计算公式。对于转移贴纸tk(yi-1, yi, x, i),k=1,2,...,K1,可以将式中的fk换成tk;对于状态特征,可以将式中的fk换成si,表示sl(yi, x, i),k = K1 +1,l = 1,2,...,K2。
有了式11.32 ~11.35,对于给定的观测序列x和标记序列y,可以通过一次前向扫描计算ai及Z(x),通过一次后向扫描计算βi,从而计算所有的概率和特征的期望。
某小皮
CRF的预测算法
条件随机场的预测问题是给定义条件随机场P(Y|X)和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)y*,即对观测序列进行标注。条件随机场的预测算法是著名的维特比算法。
由
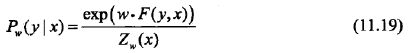
可得:

于是,条件随机场的预测问题成为求非规范化概率最大的最优路径问题。
算法:条件随机场预测的维特比算法

维特比算法建议看看HMM中的算法示例[HMM:隐马尔科夫模型 - 预测和解码 ],根据非规范化条件概率计算示例1
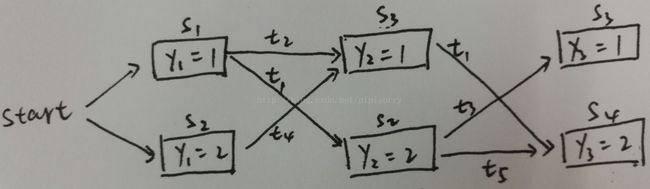
这样CRF中的维特比算法就是一样的了。
from: http://blog.csdn.net/pipisorry/article/details/78397567
ref: [统计学习方法]