sklearn数据预处理(preprocessing)系列——类别以及特征的编码(Encoder)

一、特征编码
1 类别的独热编码(One-Hot Encoder)
关于什么是独热编码以及为什么要进行独热编码,这里就不详细介绍了,本文只介绍“具体实践方式”,原理一笔带过。
第一步:先对离散的数字、离散的文本、离散的类别进行编号,使用 LabelEncoder,LabelEncoder会根据取值的种类进行标注。
import sklearn.preprocessing as pre_processing
import numpy as np
label=pre_processing.LabelEncoder()
labels=label.fit_transform(['中国','美国','法国','德国'])
print(labels)
labels的结果为:[0,3,2,1]
第二步:然后进行独热编码,使用OneHotEncoder
labels=np.array(labels).reshape(len(labels),1) #先将X组织成(sample,feature)的格式
onehot=pre_processing.OneHotEncoder()
onehot_label=onehot.fit_transform(labels)
print(onehot_label.toarray()) #这里一定要进行toarray()
结果为:
[[1. 0. 0. 0.]
[0. 0. 0. 1.]
[0. 0. 1. 0.]
[0. 1. 0. 0.]]
注意,上面的第二步也可以使用LabelBinarizer进行替代
onehot_label=pre_processing.LabelBinarizer().fit_transform(labels)
这里的参数labels就是【0,3,2,1】,不需要组织成(samples,features)的形式。
2、对“特征”进行编码
上面讲的是对分类的类别进行编码,有时候也需要对特征进行编码,为什么呢?比如有下面的一些样本
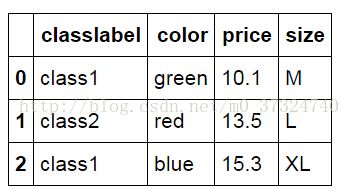
一共有3个特征,color price size 。 classlabel对应于类别,类别的独热编码上面已经进行了讲解,但是特征为什么也需要进行独热编码呢,单纯的进行数字化难道不行吗?比如用1表示green,2表示red,3表示blue。这显然不行,因为对于模型而言,color特征的每一个取值是 ”地位平等“的,也就是说所说的”无序性“如果单纯的用1、2、3进行数值化,岂不是就说告诉模型,red是green的2倍,blue是green的3倍吗?这显然不合理,凭什么你就是我的3倍,我们都是颜色啊。
那么什么样的特征需要独热编码呢?
“无序的离散特征”我们一般需要进行独热编码。但有一些不需要,比如人的身高,体重,这其实是有序的,连续的。
独热编码会为每个离散值创建一个哑特征(dummy feature)。什么是哑特征呢?举例来说,对于‘颜色’这一特征中的‘蓝色’,我们将其编码为[蓝色=1,绿色=0,红色=0],同理,对于‘绿色’,我们将其编码为[蓝色=0,绿色=1,红色=0],特点就是向量只有一个1,其余均为0,故称之为one-hot。这么做的目的是为了保证每一个离散取值的“无序性、公平性、彼此正交性”。
X=[[1,10.1,1],[2,13.5,2],[3,15.3,3]]
onehot=pre_processing.OneHotEncoder()
features=onehot.fit_transform(X)
print(features.toarray()) #一定要toarray()
上面的原始数据为:
| color | price | size | |
| 1 | 1 | 10.1 | 1 |
| 2 | 2 | 13.5 | 2 |
| 3 | 3 | 15.3 | 3 |
先使用了LabelEncoder对color这一列,size这一列进行的“标签编码",参见上面。
运行结果为:
[[1. 0. 0. 1. 0. 0. 1. 0. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 0.]
[0. 0. 1. 0. 0. 1. 0. 0. 1.]]
即下面的结果:
| color_1 | color_2 | color_3 | price_1 | price_2 | price_3 | size_1 | size_2 | size_3 | |
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
3、OneHotEncoder类的详解
下面列出在使用它的时候要注意的一些问题:
(1)给fit_transform传递的X一定要是 2D的,即(samples,features),否则会报错
(2)要查看fit_transform返回的结果,一定要使用toarray()函数进一步转化,方便查看
(3)在没有缺失数据的时候,每一个离散特征的取值种类是自动计算的,但是如果有某个特征值丢失了,则需要自己手动指定,如下:
enc = preprocessing.OneHotEncoder(n_values=[2, 3, 4]) ,
## 2 表示的是 X1有两个离散值,3 表示的是X2有三个离散值, 4 表示的是X4有4个离散值。