吴恩达机器学习ex5
第一部分 正则化线性回归
实现线性回归,通过水位预测水量,调试学习算法,检查偏差的方差的影响。
1.数据可视化
x:水位的变化,y:流出的水量
数据集被分为三部分:
1)模型将学习的训练集:X,y
2)用于确定正则化参数的交叉验证集:Xval,yval
3)用于评估性能的测试集:Xtest,ytest
% Load Training Data
fprintf('Loading and Visualizing Data ...\n')
% Load from ex5data1:
% You will have X, y, Xval, yval, Xtest, ytest in your environment
load ('ex5data1.mat');
% m = Number of examples
m = size(X, 1);
% Plot training data
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
fprintf('Program paused. Press enter to continue.\n');
pause;

2.正则化线性回归代价函数
公式:

加入正则化项可以防止过拟合,theta_0不参与正则化(在octave/MATLAB中为theta(1))。
J = sum((X * theta - y) .^ 2) / (2*m) + lambda / (2*m) * sum(theta(2:end) .^ 2);
grad = X * (X * theta - y) / m;
grad(2:end) = grad(2:end) + lambda / m * theta(2:end);

3.正则化线性回归梯度
公式:

代码已在上一小节给出

4.拟合线性回归
训练函数使用了fmincg优化代价函数。
需要设置正则化参数λ为0,目前实现的线性回归拟合的是2维的θ,正则化对于低纬度的θ并不会有太大的帮助。

可以看到是一种高偏差,欠拟合的情况
第二部分 偏差-方差
机器学习中一个重要的概念是衡量偏差-方差。高偏差的模型欠拟合,而高方差的模型过拟合。
1.学习曲线
学习曲线绘制了训练和交叉验证误差的函数。为了绘制学习曲线,我们需要对不同的训练集大小进行训练和交叉验证集误差。要获得不同的训练集大小,应该使用原始训练集X的不同子集。( X(1:i, and y(1:i))
使用训练函数获得参数θ,参数lambda也需要作为参数传入。
训练误差公式:

训练误差不包含正则化项。使用现有的损失函数,通过设置lambda为0就可以计算训练误差和交叉验证误差。
计算训练误差是应用训练集的不同子集(如上所述)。
计算交叉验证误差应在整个交叉验证集上计算。

这反映了模型中有高偏差问题——线性回归模型太简单,无法很好地拟合数据。
第三部分 多项式回归
解决上述问题的一个方法是:增加更多特征。
修改假设函数为:

我们需要做的是将原始训练集X映射到更高的维度,假设原始的数据集大小为m×1,那么函数应该返回一个m×p的矩阵,这个矩阵中,第一列数据是原始数据X,第二列数据为X平方, …,X的p次方。
for i = 1:p
X_poly(:, i) = X .^ i
end
1.多项式回归学习
将数据映射到高次方后,如果直接使用这些数据在程序中运行,那么特征缩放的问题可能会很严重(特征直接相差的过大)。因此,映射后在学习参数θ之前还需要进行特征归一化。
多项式模型能够很好地拟合数据点,训练误差低。但是该多项式拟合得很复杂,并且在极端值下落,这说明这个多项式回归模型过拟合训练数据,并且泛化能力差。
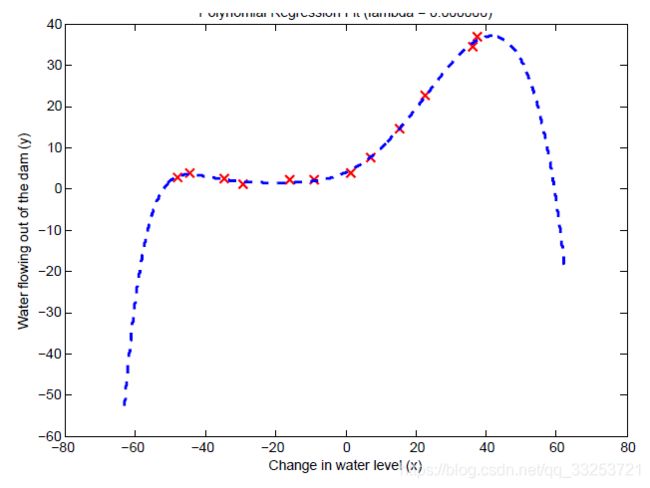
从学习曲线看出,训练误差一直很低,交叉验证误差较大,两者间的差值很大,说明了高方差问题。
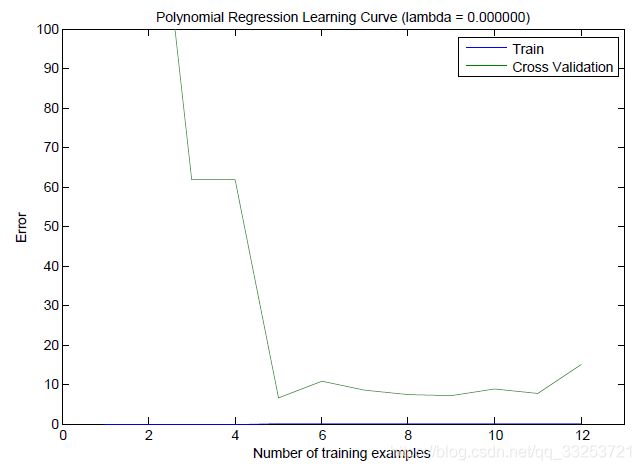
克服过拟合问题的一种方法是在模型中加入正则化项。
2.调节正则化参数
这一环节观察正则化参数如何影响正则化多项式回归的偏差-方差。
λ=1时:
多项式拟合得较好。

交叉验证误差和训练误差都收敛到一个相对较低的值。既没有高方差问题也没有高偏差问题。
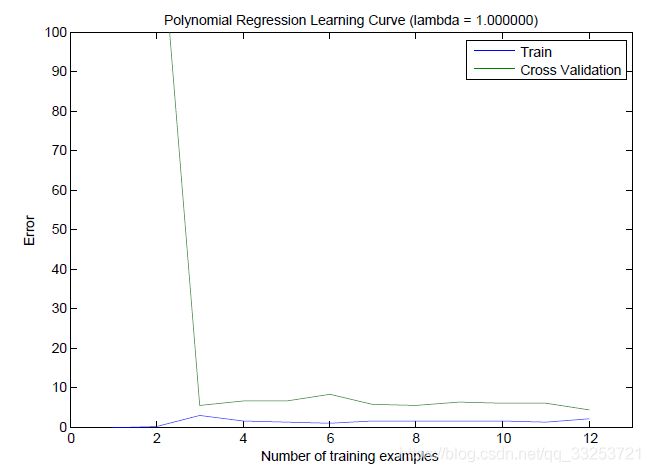
λ=100时:
正则化项过大也会是模型无法很好地拟合训练数据。

3.使用交叉验证集选择λ
这一环节实现一个自动化选择参数λ的方法。
代码给出了λ的选择范围,使用训练函数获得参数θ,之后计算训练集和交叉验证集的误差。
for i = 1:length(lambda_vec)
lambda = lambda_vec(i);
theta = trainLinearReg(X, y, lambda);
error_train(i) = linearRegCostFunction(X, y, theta, 0);
error_val(i) = linearRegCostFunction(Xval, yval, theta, 0);
end

看到最佳值在3附近。