OpenCV离散傅里叶变换(DFT前篇)
恍惚一年,很多东西没有整理,最近学弟又问道傅里叶变换的知识,说句实话,许久没接触,我也忘了很多,始有此文。
原理+Samples+函数解读的流程,dft的源码太多了,想研究的戳我

主要参考博客:
参考博客1:http://blog.csdn.net/chenjiazhou12/article/details/21240647
参考博客2:http://blog.csdn.net/autocyz/article/details/48803859
参考博客3:http://blog.csdn.net/ubunfans/article/details/24787569
1.原理
对一张图像使用傅立叶变换就是将它分解成正弦和余弦两部分。也就是将图像从空间域(spatial domain)转换到频域(frequency domain)。这一转换的理论基础来自于以下事实:任一函数都可以表示成无数个正弦和余弦函数的和的形式。傅立叶变换就是一个用来将函数分解的工具。 2维图像的傅立叶变换可以用以下数学公式表达:
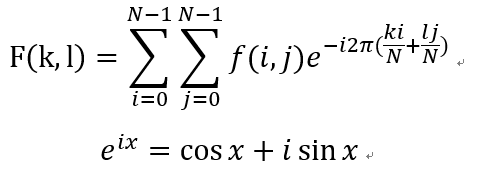
式中f是空间域(spatial domain)值, F则是频域(frequency domain)值。 转换之后的频域值是复数, 因此,显示傅立叶变换之后的结果需要使用实数图像(real image) 加虚数图像(complex image), 或者幅度图像(magitude image)加相位图像(phase image)。 在实际的图像处理过程中,仅仅使用了幅度图像,因为幅度图像包含了原图像的几乎所有我们需要的几何信息。然而,如果你想通过修改幅度图像或者相位图像的方法来间接修改原空间图像,你需要使用逆傅立叶变换得到修改后的空间图像,这样你就必须同时保留幅度图像和相位图像了。
在此示例中,我将展示如何计算以及显示傅立叶变换后的幅度图像。由于数字图像的离散性,像素值的取值范围也是有限的。比如在一张灰度图像中,像素灰度值一般在0到255之间。 因此,我们这里讨论的也仅仅是离散傅立叶变换(DFT)。 如果你需要得到图像中的几何结构信息,那你就要用到它了。
在频域里面,对于一幅图像,高频部分代表了图像的细节、纹理信息;低频部分代表了图像的轮廓信息。如果对一幅精细的图像使用低通滤波器,那么滤波后的结果就剩下了轮廓了。这与信号处理的基本思想是相通的。如果图像受到的噪声恰好位于某个特定的“频率”范围内,则可以通过滤波器来恢复原来的图像。傅里叶变换在图像处理中可以做到:图像增强与图像去噪,图像分割之边缘检测,图像特征提取,图像压缩等等。
2.Samples
还是用经典的lena图(关于这张图片的故事会在另一篇博客写出来)

#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
static void help()
{
printf("\nThis program demonstrated the use of the discrete Fourier transform (dft)\n"
"The dft of an image is taken and it's power spectrum is displayed.\n"
"Usage:\n"
"./dft [image_name -- default lena.jpg]\n");
}
int main()
{
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE),FOREGROUND_INTENSITY | FOREGROUND_GREEN);
help();
Mat src = imread("lena.jpg");
if(src.empty())
{
return -1;
}
Mat srcGray;
cvtColor(src,srcGray,CV_RGB2GRAY); //灰度图像做傅里叶变换
int m = getOptimalDFTSize(srcGray.rows); //2,3,5的倍数有更高效率的傅里叶变换
int n = getOptimalDFTSize(srcGray.cols);
Mat padded;
//把灰度图像放在左上角,在右边和下边扩展图像,扩展部分填充为0;
copyMakeBorder(srcGray, padded, 0, m - srcGray.rows,0, n - srcGray.cols, BORDER_CONSTANT, Scalar::all(0));
cout<(padded), Mat::zeros(padded.size(),CV_32F)};
Mat complexImg;
//将几个单通道的mat融合成一个多通道的mat,这里融合的complexImg既有实部又有虚部
merge(planes,2,complexImg);
//对上边合成的mat进行傅里叶变换,支持原地操作,傅里叶变换结果为复数.通道1存的是实部,通道二存的是虚部
dft(complexImg,complexImg);
//把变换后的结果分割到两个mat,一个实部,一个虚部,方便后续操作
split(complexImg,planes);
//这一部分是为了计算dft变换后的幅值,傅立叶变换的幅度值范围大到不适合在屏幕上显示。高值在屏幕上显示为白点,而低值为黑点,高低值的变化无法有效分辨。为了在屏幕上凸显出高低变化的连续性,我们可以用对数尺度来替换线性尺度,以便于显示幅值,计算公式如下:
//=> log(1 + sqrt(Re(DFT(I))^2 +Im(DFT(I))^2))
magnitude(planes[0],planes[1],planes[0]);
Mat mag = planes[0];
mag += Scalar::all(1);
log(mag, mag);
//crop the spectrum, if it has an odd number of rows or columns
//修剪频谱,如果图像的行或者列是奇数的话,那其频谱是不对称的,因此要修剪
//这里为什么要用 &-2这个操作,我会在代码后面的 注2 说明
mag = mag(Rect(0, 0, mag.cols & -2, mag.rows & -2));
Mat _magI = mag.clone();
//这一步的目的仍然是为了显示,但是幅度值仍然超过可显示范围[0,1],我们使用 normalize() 函数将幅度归一化到可显示范围。
normalize(_magI, _magI, 0, 1, CV_MINMAX);
imshow("before rearrange", _magI);
//rearrange the quadrants of Fourier image
//so that the origin is at the image center
//重新分配象限,使(0,0)移动到图像中心,
//在《数字图像处理》中,傅里叶变换之前要对源图像乘以(-1)^(x+y)进行中心化。
//这是是对傅里叶变换结果进行中心化
int cx = mag.cols/2;
int cy = mag.rows/2;
Mat tmp;
Mat q0(mag, Rect(0, 0, cx, cy)); //Top-Left - Create a ROI per quadrant
Mat q1(mag, Rect(cx, 0, cx, cy)); //Top-Right
Mat q2(mag, Rect(0, cy, cx, cy)); //Bottom-Left
Mat q3(mag, Rect(cx, cy, cx, cy)); //Bottom-Right
//swap quadrants(Top-Left with Bottom-Right)
q0.copyTo(tmp);
q3.copyTo(q0);
tmp.copyTo(q3);
// swap quadrant (Top-Rightwith Bottom-Left)
q1.copyTo(tmp);
q2.copyTo(q1);
tmp.copyTo(q2);
normalize(mag,mag, 0, 1, CV_MINMAX);
imshow("Input Image", srcGray);
imshow("spectrum magnitude",mag);
//傅里叶的逆变换
Mat ifft;
idft(complexImg,ifft,DFT_REAL_OUTPUT);
normalize(ifft,ifft,0,1,CV_MINMAX);
imshow("inverse fft",ifft);
waitKey();
return 0;
} 效果如下:

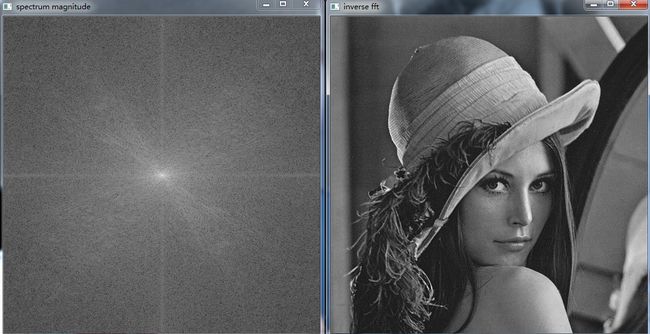
3.函数解读
注1:
OpenCV官方文档是这样说的:
the function supports arrays of arbitrary size. But only those arrays are
prime numbers (2, 3, and 5 in the current implementation). Such an efficient
DFT size can be calculated using the getOptimalDFTSize() method.
就是说dft这个函数虽然对于输入mat的尺寸不做要求,但是如果其行数和列数可以分解为2、3、5的乘积,那么对于dft运算的速度会加快很多。
关于getOptimalDFTSize()这个函数:
DFT performance is not a monotonic function of a vector size. Therefore, when you calculate convolution of two arrays or perform the spectral
analysis of an array, it usually makes sense to pad the input data with zeros to get a bit larger array that can be transformed much faster than the
original one. Arrays whose size is a power-of-two (2, 4, 8, 16, 32, ...) are the fastest to process. Though, the arrays whose size is a product of 2’s,
3’s, and 5’s (for example, 300= 5*5*3*2*2) are also processed quite efficiently.
The function getOptimalDFTSize returns the minimum number N that is greater than or equal to vecsize so that theDFT of a vector of
size N can be processed efficiently. In the current implementation N = 2 p * 3 q * 5 r for some integerp, q, r.
上面这一段话是说,数组的大小是2的整数次幂的情况,dft变换的速度是最快的。当然,大部分情况下,数组的大小不会是2
次幂,但是如果其大小可以分解为2、3、5的累成也是能够提高dft的效率的。
DFT算法的原理对于输入信号的长度不做要求,但是为了可以使用快速傅里叶变换算法(FFT算法)进行加速。所以程序中使
copyMakeBorder填充0使横纵长度变为可以由2、3、5累乘的数,这里行和列的长度不一定是样的,只要都满足条件即可。
C++: intgetOptimalDFTSize(int vecsize)
int cv::getOptimalDFTSize( int size0 )
{
int a = 0, b = sizeof(optimalDFTSizeTab)/sizeof(optimalDFTSizeTab[0]) -1;
if( (unsigned)size0 >= (unsigned)optimalDFTSizeTab[b] )
return -1;
while( a < b )//二分查找合适的size
{
int c = (a + b) >> 1;
if( size0 <= optimalDFTSizeTab[c] )
b = c;
else
a = c+1;
}
returnoptimalDFTSizeTab[b];
} ptimalDFTSizeTab定义在namespace cv中,里边的数值为2^x*3^y*5^z
static const int optimalDFTSizeTab[] = {1,2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16,…, 2123366400, 2125764000};
copyMakeBorder
C++: void copyMakeBorder(InputArraysrc, OutputArray dst, int top, int bottom, int left,int right, int borderType, const Scalar& value=Scalar())
src: 源图像
dst: 目标图像,和源图像有相同的类型,dst.cols=src.cols+left+right; dst.rows=src.rows+dst.top+dst.bottom
top:
bottom:
left:
right: 以上四个参数指定了在src图像周围附加的像素个数。
borderType: 边框类型
copyMakeBorder详细介绍:点我,开始跳转
value: 当borderType==BORDER_CONSTANT时需要指定该值。
split函数详解
将一个多通道数组分离成几个单通道数组。
这个split函数的C++版本有两个原型,他们分别是:
C++: void split(const Mat& src, Mat*mvbegin);
C++: void split(InputArray m,OutputArrayOfArrays mv);
第一个参数,InputArray类型的m或者const Mat&类型的src,填我们需要进行分离的多通道数组。
第二个参数,OutputArrayOfArrays类型的mv,填函数的输出数组或者输出的vector容器。
<2>merge函数详解
merge()函数的功能是split()函数的逆向操作,将多个数组组合合并成一个多通道的数组。
它通过组合一些给定的单通道数组,将这些孤立的单通道数组合并成一个多通道的数组,从而创建出一个由多个单通道阵列组成的多通道阵列。它有两个基于C++的函数原型:
C++: void merge(const Mat* mv, size_tcount, OutputArray dst)
C++: void merge(InputArrayOfArrays mv,OutputArray dst)第二个参数,count,当mv为一个空白的C数组时,代表输入矩阵的个数,这个参数显然必须大于1.
第三个参数,dst,即输出矩阵,和mv[0]拥有一样的尺寸和深度,并且通道的数量是矩阵阵列中的通道的总数。
补充说明:
看过OpenCV源代码的朋友,肯定都知道很多函数的接口都是InputArray或者OutputArray型的,这个接口类还是很强大的,今个就来说说它们的那些事。
注:OutputArrayOfArrays、InputOutputArray、InputOutputArrayOfArrays都是OutputArray的别名而已 详细参见:点我开始跳转
InputArray这个接口类可以是Mat、Mat_
有时候InputArray输入的矩阵是个空参数,你只需要用cv::noArray()作为参数即可,或者很多代码里都用cv::Mat()作为空参。
这个类只能作为函数的形参参数使用,不要试图声明一个InputArray类型的变量
如果在你自己编写的函数中形参也想用InputArray,可以传递多类型的参数,在函数的内部可以使用_InputArray::getMat()函数将传入的参数转换为Mat的结构,方便你函数内的操作;必要的时候,可能还需要_InputArray::kind()用来区分Mat结构或者vector<>结构,但通常是不需要的。
merge:
功能:合并多个单通道图像到一个多通道图像
结构:
void merge(const Mat*mv, size_t count, OutputArray dst)count:被合并图像的数目
dst:输出图像,图像的size和depth和mv[0]相同,通道数为被合并图像通道数的总和
dft:
功能:进行傅里叶变换
结构:
void merge(const Mat*mv, size_t count, OutputArray dst)dst:输出图像
关于dft的介绍在帮助文档中有很详细的介绍
magnitude:
功能:计算幅度
结构:
void magnitude(InputArray x, InputArray y, OutputArray magnitude)y:虚部,size和x一样
magnitude:输出图像,和x有同样的size和type
原理如下:
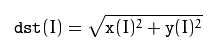
log:
功能:对数组的每一个元素取自然对数
结构:
void log(InputArraysrc, OutputArray dst)dst:输出图像
原理如下:
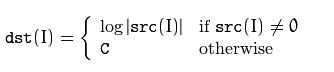
C是一个很大的负数
normalize:
功能:矩阵归一化
结构:
void normalize(InputArray src, OutputArraydst, double alpha=0, double beta=1, int norm_type=NORM_L2, int dtype=-1,InputArray mask=noArray() )dst:输出矩阵
alpha:归一化后的最小值
beta:归一化后的最大值
norm_type:归一化类型,有NORM_INF, NORM_L1, NORM_L2和NORM_MINMAX
详解如下:点我开始跳转
备注2:
我们知道x&-2代表x与-2按位相与,而-2的二进制形式是2的二进制取反加一的结果(这是补码的问题)。2 的二进制结果是(假设
8位表示,实际整型是32位,但是描述方式是一样的,为便于描述,用8位表示)0000 0010,则-2的二进制形式为:1111 1110,
x与-2按位相与后,不管x是奇数还是偶数,最后x都会变成一个偶数。
备注3:
我相信很多人,包括我自己都会很疑惑,为什么要对傅里叶变换的结果进行坐标转换,才能看到那种中间亮,周围暗的频率图。我也研究了很久,后来发现,这是因为对于正常的傅里叶变换,其变换的结果都是在0~2*pi之间的,如果将其转换为-pi~pi之间,实质上是没有变化的,但是为了方便人观察,才将结果转换到-pi~pi中。实际上如果拿四张一模一样的没有经过坐标变换的图拼在一起,会发现拼接处的图形模样与坐标变换后是一样的。
附加问题:
经过转换后的矩阵数值应该都在0-1之间,但是图片显示为什么不是全黑,而且有些亮度还挺亮的,做了一个对比,定义一个Mat矩阵,赋值为0.5,显示一片乌黑,这又是为什么呢?
解释如下:
imshow 函数缩放图像,取决于图像的深度:
- 如果载入的图像是8位无符号类型(8-bit unsigned),就显示图像本来的样子。
- 如果图像是16位无符号类型(16-bit unsigned)或32位整型(32-bit integer),便用像素值除以256。也就是说,值的范围是[0,255 x 256]映射到[0,255]。
- 如果图像是32位浮点型(32-bit floating-point),像素值便要乘以255。也就是说,该值的范围是[0,1]映射到[0,255]。
关于快速傅里叶变换FFT后面会更新,很长时间没弄了,以前没想到弄博客,还需要整理一下
Any Problem 欢迎留言讨论交流!