scrapy框架之五大组件工作流程
文章目录
- 1. scrapy 五大核心组件的工作流程
- 1.1 五大组件简介:
- 2. scrapy组件作用
- 3. scrapy数据流图:
- 4. ☆组件工作流程:
- 5. 引擎作用:
- 管道 ITEM PIPELINE中方法
声明:
本文工作流程参考了:https://www.cnblogs.com/wszxdzd/p/10269222.html 并做了一些修改补充
工作流程请直接查看 第四条组件工作流程
1. scrapy 五大核心组件的工作流程
当执行爬虫文件时,5大核心组件就在工作了
1.1 五大组件简介:
spiders 引擎(Scrapy Engine)管道(item Pipeline)调度器(Scheduler)下载器(Downloader)
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):
它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):
它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):
你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2. scrapy组件作用
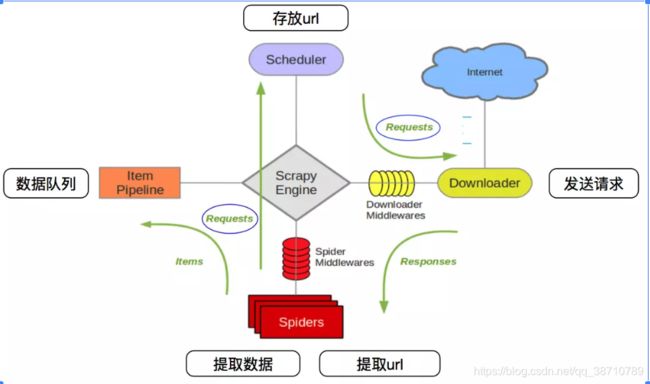
3. scrapy数据流图:
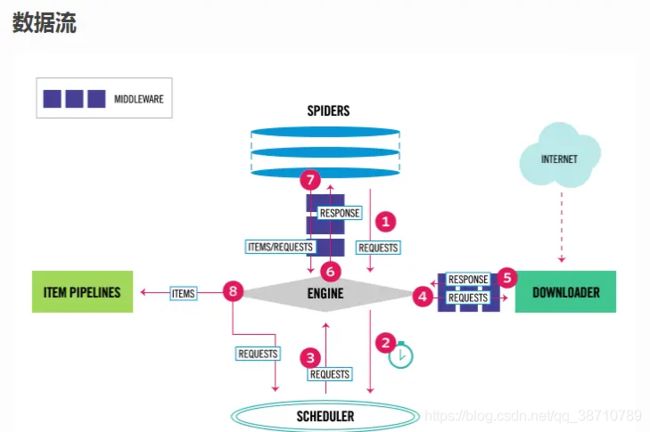
4. ☆组件工作流程:
根据架构图,首先执行爬虫文件spider,spider的作用是
(1)解析(2)发请求,原始的url存储在于spider中(start_urls)
1.1:当spider执行的时候,首先对起始的url发送请求,将起始url封装成请求对象
1.2:将封装后的请求对象(requests)传递给引擎(不经过爬虫中间件)
2:引擎将请求对象传递给调度器(内部含有队列和过滤器两个机制),调度器将请求存储在队列(先进先出)中
3:将请求传递给引擎:Engine根据当前并发请求数,从调度器队列中调度出相应的url请求对象
4.1:引擎将请求对象(requests)通过下载中间件发送给下载器
4.2:下载器拿到请求到互联网上去下载
4.3:互联网将下载好的数据封装到响应对象(response)给到下载器
5:下载器将响应对象(response)通过下载中间件发送给引擎
6:引擎将封装了数据的响应对象回传给spider类parse方法中的response对象(第一节课中讲的parse中的response参数接收封装后的response对象)
7.1:spider中的parse方法被调用,response就有了响应值
7.2:在spider的parse方法中进行爬虫功能,解析代码的编写;
(1)会解析出另外一批url,(2)会解析出相关的文本数据
7.3: 将解析拿到的数据封装到item中
7.items:item将封装的文本数据提交给引擎
8.items:引擎将数据提交给管道(item pipelines)进行持久化存储(一次完整的请求数据)
7.requests:如果parder方法中解析到的另外一批url想继续提交可以继续手动进行发请求
7.requests:spider将这批请求对象封装提交给引擎
8.requests:引擎将这批请求对象发配给调度器
2(队列和过滤器):这批url通过调度器中过滤器过滤掉重复的url存储在调度器的队列中
3调度器、并发:调度器再将这批请求对象进行请求的调度发送给引擎
5. 引擎作用:
1:处理流数据,数据传递,组件间的通讯 2:触发事物
引擎根据相互的数据流做判断,根据拿到的流数据进行下一步组件中方法的调用
中间件:
下载中间件: 位于引擎和下载器之间,可以拦截请求和响应对象;拦截到请求和响应对象后可以
篡改页面内容和请求和响应头信息。
爬虫中间件:位于spider和引擎之间,也可以拦截请求和响应对象,不常用。
管道 ITEM PIPELINE中方法
参考网上博客
Scrapy爬虫框架第七讲【ITEM PIPELINE用法】
待续