本文来自OPPO互联网技术团队,如需要转载,请注明出处及作者。欢迎关注我们的公众号:OPPO_tech
在多数中寻找少数异常样本,这在实际工业生产中是非常常见的一种诉求,因为特殊的判别需求总是体现在少数部分里头。以广告为例,在众多广告实际点击,表单提交中如何判别异常点击异常案例,也是非常常见的案例。
文本从业务场景出发,阐述实际广告以及生活中的这种场景诉求,然后分别从Smote过采样,PU学习以及CostSensitive Classification等几个维度进行深度的剖析。
所谓异常检测,即在正常的流程中,你需要识别出来潜在的异常,而一般情况下,异常则意味着风险,所以,在实际的场景中,这类诉求是非常常见的。
1. 实际生活中的异常检测场景
我们的大主题是广告,所以还是先以广告为例,在实际的广告投放中,什么场景下会有类似的异常检测的诉求呢?
广告投放的核心目标是给流量投放广告,然后最终期望用户点击广告带来转化,这种所谓的转化有可能是直接的点击(常规CPC广告),也有可能是APP的下载(常规的APP应用下载投放),还有可能是咨询沟通(在线咨询),也有可能是表单收集(常见的H5类型投放,表单收集)。
每产生一个Click,每产生一个下载,每产生一次表单提交,这都意味着需要扣广告主的钱,如果说点击/下载/表单填写都是假的呢?这个职责谁来承担,反正广告主钱是已经扣了。
以表单提交为例,H5的投放,大部分对于广告主来说还有后续的一些其他操作,诸如拿着表单信息进行离线的电话沟通等,一方面推广费用已经扣除,另一方面收集过来很大一部分是无效表单,联系不上,恶意辱骂,信息错位等等,其离线的进一步营销也是需要成本的。这就造成了无效成本的进一步增大。
那么,会有这么多错误点击和错乱表单的存在吗?真的是有的,有一些习惯性无聊的,看到广告就瞎点;有一些是竞品玩家,纯粹故意恶心你来的;还有一些人性本恶的,估计进来骂人以及找骂的;还有一些机器人等等。
针对这些人这些情况,我们如果能提前一步识别出来,避免将广告投放给他,如果能够控制召回和准确率,岂不妙哉;退一步讲,就算提前预测不出来,点击之后,产生表单之后再进行识别,这样也可以避免给广告主造成经济损失,也是可以的。
但是,这毕竟少数人,如果是大规模的情况,那意味着你大广告投放环境实在太糟糕了,建议不要做广告了。
这种抓“坏人”的情况除了广告领域,其他领域也大有存在,比如网站或者平台上的恶意流量识别,电商里找撸羊毛的羊毛党,贷款领域里的潜在贷款风险人的识别等。
各行各业,都有类似的诉求,是的,找“坏人”。
2. 异常检测与分类
可以看到,我们核心目标就是找“坏人”。这不是典型的分类问题吗?你是好人,或者你是坏人,二选一,没得挑,二值分类问题。
但这真的不是典型的分类问题。
还是以广告为例,一次广告投放以100万的曝光量计算,你觉得会遇到多少“坏人”,会有10万?如果你的平台高达10%的坏人比例,那你的平台估计早得关门大吉了。
所以,这种情况,永远都是小比例事件。100万的曝光,以1%的点击率来算,进来的人1万个,1万个里有近百个捣乱的已经够你喝一壶的了。
所以,实际比例可能是99.99万比100,如果是典型的分类问题,五五分是正常的,三七开也算是过得去,但没怎么见9999比1这么悬殊比例的典型分类问题。
所以,异常检测从来都不是典型的分类问题,是典型的非典型分类问题。他具有以下几个特点:
- 第一,一定是茫茫人海里找到少数特殊的存在,严格意义上还是分类。
- 第二,但对于这些人来说,找到他们非常重要,因为他们的有害性很高,这意味着在某种合适平衡的情况下,我们需要尽可能的提升召回率。
- 第三,在很多情况下,我们并不能很好的找到很多那些有问题的正样本,然后负样本中极有可能会包含正样本,而正负样本量是属于极度失衡的状态。
这三点应该比较好理解,所以针对几类问题,我们需要找到优化的方法,不能一板一眼的通过常规分类手段实现预测模型的构建。
3. PU-Learning
所谓PU-Learning,即P代表的是Positive,U代表的是Unlabel,就是上述中第三点,负样本实际上是泛样本。我们可以确保异常的正样本中没有“好人”,但不能保证负样本中没有“坏人”。
实际上,很多时候根本就没有啥负样本,就是在大池子捞一批人出来,所以才有Unlabel的说法,因为没法区分,量太大了,能显性找出来的,都已经丢到正样本里头去了。
所以这个时候,实际上这是一个半监督分类的问题。我们首先要解决的问题是,在未标记的样本中找到可靠的负样本。
当然,在通常这种正样本与负样本在实际环境中比例异常悬殊,所以,就算不做额外处理,把unlabel的样本当成负样本使用,然后直接训练一个标准的分类器,然后做预测,也是可以解决的。此处参考文献【01】,虽然直白,但是我们暂时不发散,太简单了,没意思。
为了避免unlabel样本中的潜在正样本带来的分类偏差,我们可以通过类似boostrap的方式来降低潜在正样本带来的分类偏差。
过程可以理解为:
- 随机抽取一部分未标记的样本作为负样本,训练分类器
- 然后测试部分的数据进行预测,拿到预测概率
- 继续重复从全量未标记样本中随机抽取数据,重复一二步骤
- 最终我们拿到了N次的预测结果,取平均作为最终的预测概率
这类方式也非常好理解,通过多次随机打乱数据,最终取平均的方式来降低未标记样本中的潜在正样本带来的分类错误。这种方式,详情可以参考文献【02】。
还有第三种方式,更为流行且被认可的方式,即two-stage strategy两步法。我们先用正样本和未标记样本训练一个分类器,然后对未标记样本进行预测,取高概率的部分作为“真·负样本”,然后把这部分“真·负样本”丢回输入数据中,更新分类器,然后再重复迭代,直到认为我们的分类模型可使用为止。两步法的具体论文参考文献【03】。
我们可以发现,其实基本上这类PU Learning的解决方案都是偏工程手法,具体在分类模型的选择上并没有特殊的要求,可以自行选择和调试,但是鉴于大多会遇到重复迭代的问题,所以尽量选择高效的分类模型来做中间分类器的训练,比如XGboot,比如LR等。
4. 解决样本不均衡的问题Smote算法
我们暂且抛开所谓“未标记”的问题,正如上一章所说,在实际情况中,未标记样本大概率是负样本,就算不是也有一些方式可以探测出来,尽量的把负样本给摘取出来。
但是,另外一个问题却非常致命,即,往往我们只有100个正样本,但是负样本却有上万个,哪怕随机挑一批也远远多于正样本。
所以,问题很明显,就是典型样本极度不均衡的情况。而我们所说的异常检测问题,就属于这种典型样本不均衡的问题。
针对于样本不均衡的问题,常规解决方式就是,对于量大的样本进行欠采样,即只采一部分当成对应类型样本;对于量小的样本进行过采样,所谓过采样就是想尽一切办法来增加样本。
而我们要聊的Smote算法就是一切办法中的增加样本的一种算法。当然,简单的欠采样,可以直接随机抽取部分比例,而暴力的过采样则可以直接随机选择部分样本进行批量复制。
更科学点的欠采样,可以使用对样本进行举类,然后选取中心点位置,从而达到样本缩小的目的,对于升级版的过采样,Smote算法算是典型的解决方案了。
参考SMOTE的论文文献【04】,其伪代码过程如下:

其论文名称转换成中文就是“合成少数类过采样技术”,伪代码的逻辑是:随机选取一个中心点,然后计算它的近邻,假设中心点是a,选择的近邻是b,则在ab连线上随机选择一个点作为新的样本。
图解如下:
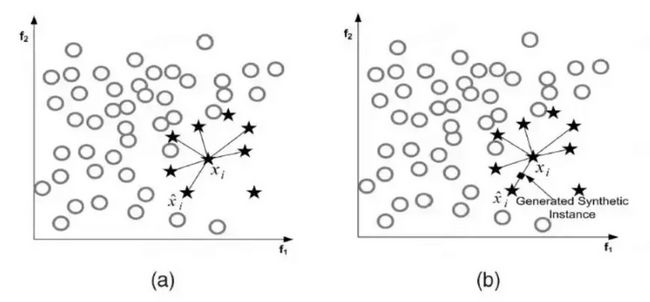
算法原理巨简单,看上面的伪代码或者图解基本上就能理解了,他抛弃了简单的复制过采样的方法,以一种更加合理的方式进行少数样本扩增。
从逻辑上我们发现,其实还是有些问题需要待确认的,比如到底应该选取多少个中心点,然后选择近邻的时候选择多个个数,通过选定的近邻和中心点构造新样本点,是不是一定要在两个点之间随机。
中心点的个数决定了你需要扩增的量级,近邻的范围决定了你的过采样新构造的点是否足够分散,越聚拢则越容易形成过拟合,越分散则模型的泛化能力越好,但过度分散又会导致预测准确率下降等等。
所以如上,基于原有的论文,随机点不单纯可以在ab之间,甚至可以超出ab的直线范围,也可以在ab直线的中心轴上做偏移。
对于算法的实现来说,基于上面的逻辑,其实自己写一个代码出来也非常容易,或者谷歌一下,有无数的开源实现,当然,最好的方式当然是引入学习库了。这里推荐imblearn.over_sampling import SMOTE的实现,具体用法很简单,查看官网CASE即可(文献【05】),且其实现了各种不同的SMOTE变种。
5. CostSensitiveClassification代价敏感分类
Csot Sensitive这个单词组应该认识,不认识查查字典也应该认识,所谓CostSensitiveClassification即代价敏感的分类。
什么叫代价敏感,就是分错了后果很严重。又回到了我们的开头,所有异常检测的业务场景都是“宁可错杀一百,不可放过一个”的例子。
当然,这样说有点严重了,但是基本上只要召回不够高,带来的业务损失是很大的,所以,一般情况下,只要保证一定程度上的precision,是要尽可能地提升recall指标的。
既然对于少数类分错了后果如此严重,我们如何让模型认识到分错了是一件非常严肃的事情呢?
之前我们做过采样,其实无形中也增加了这类样本的特征,也算是解决cost sensitive问题的一种“曲线救国”的方式。还有诸如,直接在模型上加大这类样本的权重,很大一部分模型是支持这类操作的,告诉模型这类样本比较重要(这类方式标准的称呼为rescaling方法)。
还有一种方式,是直接穿透底层的方案,那就是自定义损失函数,从损失函数里体现这类样本的重要性,即一旦分错之后,会带来额外的损失,这就是有偏损失,所以核心评估的是损失量,而非直观误判损失(此类方法称之为reweighted方法)。
针对于Cost Sensitive的更全面性的描述,可以参考论文文献【06】,论文里通过对比常规分类的评估和银行借贷评估以及恶性疾病诊断等案例对比,来阐述Cost Sensitive的需求场景。
在文献【07】论文中,提出了一种基于AdaBoost分类算法改进的Cost Sensitive算法--AdaCost。
AdaBoost的核心思想是通过反复修改数据的权重,从而使一系列的弱分类器集成一个强分类器,具体逻辑如下:
- 权值调整,提升被分错误分类的样本权重,降低正确分类的权重。
- 基于分类器组合,采用加权多数表决算法,加大分类错误率较小的弱分类器的权重,从而减小误差。
而AdaBoost的弱分类器通常又使用回归树进行构建。AdaCost基于AdaBoost的改进而来,并且也是通过reweighted方式实现的。其过程同样是使用弱分类器集成强分类器,只不过在权值评估的时候,AdaBoost侧重于评估分类的准确性,而AdaCost引入了Cost的元素,即代价损失,且不同类别其误判Cost是不同的,从而在权值划分中引入了Cost的考量。
具体的逻辑以及伪代码如下:

如上逻辑中,重点关注函数β,这是评价分类结果的cost性能引入,从而使得分类符合Cost Sensitive的要求。
具体相关其他代价函数的手工设计等,暂时不在能力范围内,更多是依赖于开源解决方案,来解决实际的应用问题,一个比较有用的开源实现,参考文献【08】,里面集成了众多的Cost Sensitive分类模型。

6. 总结
在实际的应用场景中,我们会经常遇到这种少类对多类的场景,且少类恰巧是更为重要的类型,识别错误的代价往往很高。
我们可以通过多种方式来解决这个问题,最简单的无非是平衡样本查,通过欠采样抽样多样本,通过采样进行少类样本扩充,而Smote又是一种典型可行的过采样方式。
我们也可以通过PU学习的解决方案,通过工程探测的一些逻辑,从海量实际数据里捕捉少类样本,加大少类样本的量,以及提升分类模型的准确性。
最后,我们还可以通过Cost Sensitive分类算法解决思路来看待这类问题,通过优化评估函数,或者损失函数,引入Cost的权重重新划分的方式,将少类样本的重要性告诉Model,从而提升模型对于少类样本的分类“谨慎度”。
当然,我们在工业解决上,除非做研究,所以核心还是解决问题为主,哪种方案成本低,且能够满足你的业务模型要求,那就OK。所以,多看看行业的开源解决方案,那是一个快速应用落地的思路。
7. 参考文献
- Learning classifiers from only positive and unlabeled data
- A bagging SVM to learn from positive and unlabeled examples
- An Evaluation of Two-Step Techniques for Positive-Unlabeled Learning in Text Classification
- SMOTE: synthetic minority over sampling technique
- imbalanced-learn.org/en/stable/g…
- Cost-Sensitive分类算法——综述和实验
- Asymmetric Boosting
- albahnsen.github.io/CostSensiti…
