MySQL中表的数据的增删改查(CRUD)
一、插入数据
单条插入
方法一:
insert into 表名(列名1,列名2,列名3) values(值1,值2,值3);例:
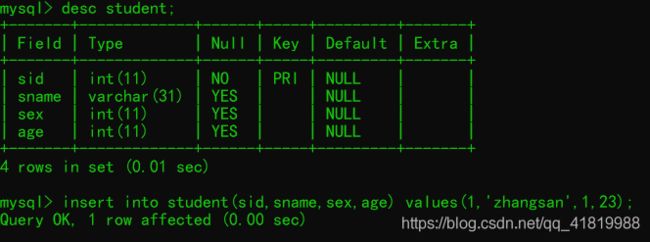
方法二(简单写法):
insert into 表名 values(值1,值2,值3);例:

方式三(部分插入):
insert into 表名(列名1,列名3) values(值1,值3);例:

注意:
1,如果插入的是全列名的数据,后面的列名可以省略,。
2,如果插入的是部分列名的的数据,后面的列名不可以省略。
批量插入
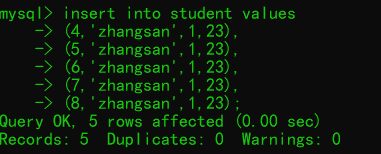
方式一(批量插入):
insert into 表名 values
(值1,值2,值3),
(值1,值2,值3),
(值1,值2,值3),
(值1,值2,值3),
(值1,值2,值3);例:
批量插入与单条插入的效率:
1,批量插入的效率优于单条插入
2,如果批量插入中有一条出现问题,整个插入都失败
二、删除数据
方法一(删除单条数据):
delete from 表名 where条件例:

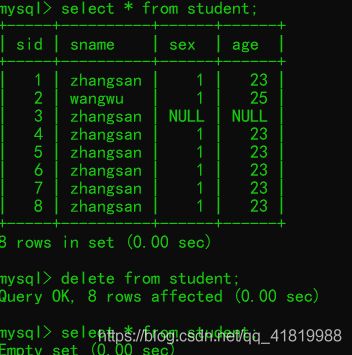
方式二(删除全部数据):
delete from 表名;例:
delete 删除数据 和 truncate 删除数据有什么区别?
delete(DML): 一条一条删除表中的数据,如果数据比较少,delete比较高效
truncate(DDL): 先删除表,在重建表,如果数据比较多,truncate比较高效
三、更新表记录
方式一(更新单列数据):
update 表名 set 列名=列的值,列名2=列的值 where条件例:

方式二(修改多列数据)
update 表名 set 列名=列的值,列名2=列的值2例:

四、查询表记录
方式:
select [distinct] [*] [列名,列名2] from 表名 [where 条件];例1:
--商品分类:手机数码,鞋靴箱包
1,分类的ID
2,分类名称
3,分类描述
步骤一(创建表):
create table category(
cid int primary key auto_increment,//auto_increment自动增长
cname varchar(10),
cdesc varchar(31)
);
步骤二(插入数据):
insert into category values(null,'手机数码','电子产品');
insert into category values(null,'鞋靴箱包','江南皮革厂倾情打造');
insert into category values(null,'香烟酒水','黄鹤楼,茅台,二锅头');
insert into category values(null,'酸奶饼干','娃哈哈,蒙牛酸酸乳');
insert into category values(null,'馋嘴零食','瓜子花生,八宝粥,辣条');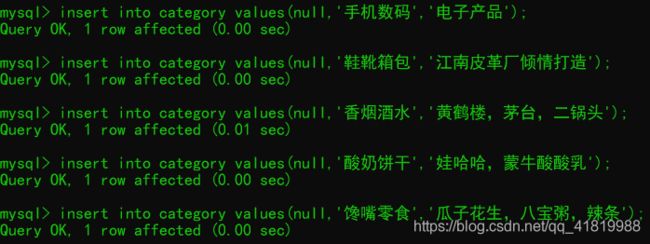
全部内容查询:

部分内容查询:

例2:
--所有商品
1,商品ID
2,商品名称
3,商品的价格
4,生产日期
5,商品分类ID
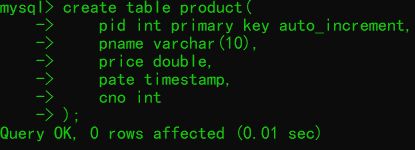
步骤一(创建表):
create table product(
pid int primary key auto_increment,
pname varchar(10),
price double,
pdate timestamp,
cno int
);
步骤二(插入数据):
insert into product values(null,'小米mix4',998,null,1);
insert into product values(null,'锤子',2888,null,1);
insert into product values(null,'阿迪王',99,null,2);
insert into product values(null,'老村长',88,null,3);
insert into product values(null,'劲酒',35,null,3);
insert into product values(null,'小熊饼干',1,null,4);
insert into product values(null,'卫龙辣条',1,null,5);
insert into product values(null,'旺旺大饼',1,null,5);
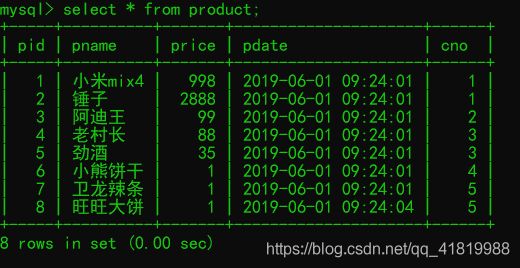
查询全部数据;
--简单查询
--查询所有商品
select * from product;
--查询商品名称和商品价格:
select pname,price from product;
xvt--别名查询,as关键字,as关键字可以省略
--起表别名:
select p.name,p.price from product as p;(主要用于多表查询)
--列别名:
select pname as 商品名称,price as 商品价格 from product;
--去掉重复的值
--去除商品价格中重复的值
select distinct price from product;
--select运算查询(仅仅在查询结果上做了运算,原数据表结构不变,+、-、*、/)
select *,price*15 as 折后价 from product;
--条件查询 [where关键字]
指定条件,确定要操作的记录
--查询商品价格>60元的所有商品信息
select * from product where price > 60;
--where 后的条件写法
--关系运算符:>、>=、<、<=、=、!=、<>
<>(不等于):标准SQL语法
!=(不等于):非标准SQL语法
--查询商品价格在10~100之间
select * from product where price >10 and price <100;select * from product where price between 10 and 100;
--查询出商品价格 小于100或者商品价格 大于900
select * from product where price <100 or >900;--like:模糊查询
_ :代表的是一个字符
%:代表的是多个字符
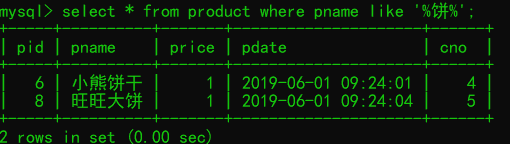
--查询出名字带有饼的所有商品
select * from product where pname like '%饼%';
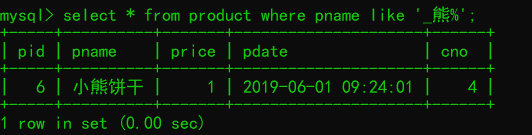
--查询第二个名字是熊的所有商品'_熊%'
select * from product where pname like '_熊%';
--in 在某个范围中获得值
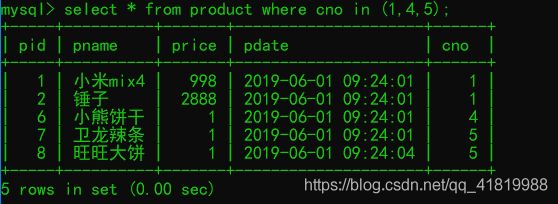
--查询出商品分类ID在 1,4,5里面的所有商品
select * from product where cno in (1,4,5);








--排序查询:order by 关键字
asc : ascend 升序
desc:descend 降序
1,查询所有商品,按照价格进行排序
select * from product order by price;
2,查询所有商品,按价格进行降序排序
select * from product order by price desc;
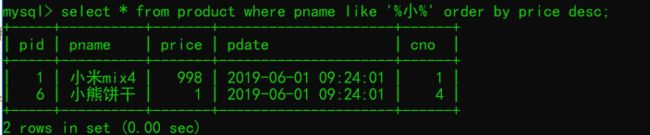
3,查询名称有 小 的商品,按价格降序排序
select * from product where pname like '%小%' order by price desc;


--聚合函数
sum():求和 avg():求平均值 count():统计数量 max():求最大值 min():求最小值
1,获得所有商品价格的总和
select sum(price) from product;
2,获得所有商品的平均数
select avg(price) from product;
3,获得所有商品的个数
select count(pname) from product;



注意:where 条件后面不能接聚合函数
--分组:group by
1,根据cno字段分组,分组后统计商品的个数
select cno,count(*) from product group by cno;
2,根据cno分组,分组统计每组商品的平均价格,并且商品的平均价格 >60
select cno,avg(price) from product group by cno having avg(price) > 60;


having 关键字 可以接聚合函数的 出现在分组之后
where 关键字 不可以接聚合函数 出现在分组之前
编写顺序
S..F..W..G..H..()
select .. from .. where .. group by.. having .. order by
执行顺序
F..W..G..H..S..O
from .. where .. group by .. having ..select ..order by