机器学习 ---- 条件随机场
目录
- 1.什么是条件随机场
- 2.马尔科夫过程
- 3.隐马尔科夫算法
- 4.条件随机场(以线性链条件随机场为例)
- 4.1定义
- 4.2基本问题
- 4.3概率计算问题
- 4.4 前向-后向算法
- 5. BFGS 算法
- 6.预测问题
1.什么是条件随机场
条件随机场是一种无向图模型,且相对于深度网络有非常多的优势,因此现在很多研究者结合条件随机场(CRF)与深度网络获得更鲁棒和可解释的模型。
在介绍条件随机场之前,首先简单说明马尔科夫过程以及隐马尔科夫算法。
2.马尔科夫过程
定义:假设一个随机过程中, t n t_n tn 时刻的状态 x n x_n xn的条件发布,只与其前一状态 x n − 1 x_{n-1} xn−1 相关,即:
P ( x n ∣ x 1 , x 2 , . . . , x n − 1 ) = P ( x n ∣ x n − 1 ) P(x_n|x_1,x_2,...,x_{n-1}) = P(x_n|x_{n-1}) P(xn∣x1,x2,...,xn−1)=P(xn∣xn−1)
则将其称为 马尔可夫过程。

3.隐马尔科夫算法
定义:
隐马尔科夫算法是对含有未知参数(隐状态)的马尔可夫链进行建模的生成模型,如下图所示:

在隐马尔科夫模型中,包含隐状态 和 观察状态,隐状态 x i x_i xi 对于观察者而言是不可见的,而观察状态 y i y_i yi 对于观察者而言是可见的。隐状态间存在转移概率,隐状态 x i x_i xi到对应的观察状态 y i y_i yi 间存在输出概率。
假设:
- 假设隐状态 x i x_i xi 的状态满足马尔可夫过程,i时刻的状态 x i x_i xi 的条件分布,仅与其前一个状态 x i − 1 x_{i-1} xi−1相关,即:
P ( x i ∣ x 1 , x 2 , . . . , x i − 1 ) = P ( x i ∣ x i − 1 ) P(x_i|x_1,x_2,...,x_{i-1}) = P(x_i|x_{i-1}) P(xi∣x1,x2,...,xi−1)=P(xi∣xi−1)
- 假设观测序列中各个状态仅取决于它所对应的隐状态,即:
P ( y i ∣ x 1 , x 2 , . . . , x i − 1 , y 1 , y 2 , . . . , y i − 1 , y i + 1 , . . . ) = P ( y i ∣ x i ) P(y_i|x_1,x_2,...,x_{i-1},y_1,y_2,...,y_{i-1},y_{i+1},...) = P(y_i|x_{i}) P(yi∣x1,x2,...,xi−1,y1,y2,...,yi−1,yi+1,...)=P(yi∣xi)
存在问题:
在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还和观察序列的长度、上下文等信息相关。例如词性标注问题中,一个词被标注为动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的其他词。
4.条件随机场(以线性链条件随机场为例)
4.1定义
给定 X = ( x 1 , x 2 , . . . , x n ) X=(x_1,x_2,...,x_n) X=(x1,x2,...,xn) , Y = ( y 1 , y 2 , . . . , y n ) Y=(y_1,y_2,...,y_n) Y=(y1,y2,...,yn) 均为线性链表示的随机变量序列,若在给随机变量序列 X 的条件下,随机变量序列 Y 的条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 构成条件随机场,即满足马尔可夫性:
P ( y i ∣ x 1 , x 2 , . . . , x i − 1 , y 1 , y 2 , . . . , y i − 1 , y i + 1 ) = P ( y i ∣ x , y i − 1 , y i + 1 ) P(y_i|x_1,x_2,...,x_{i-1},y_1,y_2,...,y_{i-1},y_{i+1}) = P(y_i|x,y_{i-1},y_{i+1}) P(yi∣x1,x2,...,xi−1,y1,y2,...,yi−1,yi+1)=P(yi∣x,yi−1,yi+1)
则称为 P(Y|X) 为线性链条件随机场。
通过去除了隐马尔科夫算法中的观测状态相互独立假设,使算法在计算当前隐状态 x i x_i xi时,会考虑整个观测序列,从而获得更高的表达能力,并进行全局归一化解决标注偏置问题。
参数化形式
p ( y ∣ x ) = 1 Z ( x ) ∏ i = 1 n exp ( ∑ i , k λ k t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ) p\left(y | x\right)=\frac{1}{Z\left(x\right)} \prod_{i=1}^{n} \exp \left(\sum_{i, k} \lambda_{k} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{i, l} \mu_{l} s_{l}\left(y_{i}, x, i\right)\right) p(y∣x)=Z(x)1i=1∏nexp⎝⎛i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i)⎠⎞
其中:
Z ( x ) Z(x) Z(x) 为归一化因子,是在全局范围进行归一化,枚举了整个隐状态序列 x 1 … n x_{1…n} x1…n的全部可能,从而解决了局部归一化带来的标注偏置问题。
Z ( x ) = ∑ y exp ( ∑ i , k λ x t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ) Z(x)=\sum_{y} \exp \left(\sum_{i, k} \lambda_{x} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{i, l} \mu_{l} s_{l}\left(y_{i}, x, i\right)\right) Z(x)=y∑exp⎝⎛i,k∑λxtk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i)⎠⎞
t k t_k tk 为定义在边上的特征函数,转移特征,依赖于前一个和当前位置
s 1 s_1 s1 为定义在节点上的特征函数,状态特征,依赖于当前位置。
简化形式
因为条件随机场中同一特征在各个位置都有定义,所以可以对同一个特征在各个位置求和,将局部特征函数转化为一个全局特征函数,这样就可以将条件随机场写成权值向量和特征向量的内积形式,即条件随机场的简化形式。
step 1
将转移特征和状态特征及其权值用统一的符号表示,设有k1个转移特征, k 2 k_2 k2个状态特征, K = k 1 + k 2 K=k_1+k_2 K=k1+k2,记
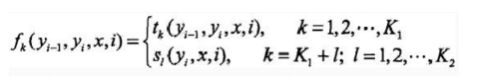
step 2
对转移与状态特征在各个位置i求和,记作
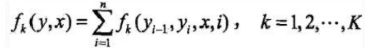
step 3
将 λ x \lambda_{x} λx 和 μ l \mu_{l} μl 用统一的权重表示,记作
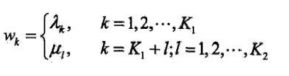
step 4
转化后的条件随机场可表示为:
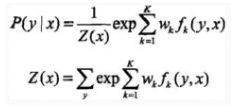
step 5
若 w w w 表示权重向量:
w = ( w 1 , w 2 , . . . , w K ) T w = (w_1,w_2,...,w_K)^T w=(w1,w2,...,wK)T
以 F ( y , x ) F(y,x) F(y,x) 表示特征向量,即
![]()
则,条件随机场写成内积形式为:

4.2基本问题
条件随机场包含概率计算问题、学习问题和预测问题三个问题。
- 概率计算问题:已知模型的所有参数,计算观测序列 Y Y Y 出现的概率,常用方法:前向和后向算法;
- 学习问题:已知观测序列 Y Y Y,求解使得该观测序列概率最大的模型参数,包括隐状态序列、隐状态间的转移概率分布和从隐状态到观测状态的概率分布,常用方法:Baum-Wehch 算法;
- 预测问题:一直模型所有参数和观测序列 Y Y Y ,计算最可能的隐状态序列 X X X,常用算法:维特比算法。
4.3概率计算问题
给定条件随机场 P ( Y ∣ X ) P(Y|X) P(Y∣X),输入序列 x x x 和 输出序列 y y y;
计算条件概率
P ( Y i = y i ∣ x ) , P ( Y i − 1 = y i − 1 , Y i = y i ∣ x ) P(Y_i=y_i|x), P(Y_{i-1} = y_{i-1},Y_i = y_i|x) P(Yi=yi∣x),P(Yi−1=yi−1,Yi=yi∣x)
计算相应的数学期望问题;
4.4 前向-后向算法
- step 1 前向计算
对观测序列 x x x 的每个位置 i = 1 , 2 , . . . , n + 1 i=1,2,...,n+1 i=1,2,...,n+1 ,定义一个 m m m 阶矩阵( m m m 为标记 Y i Y_i Yi取值的个数)
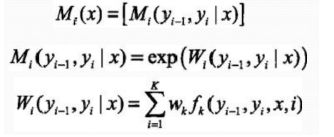
对每个指标 i = 0 , 1 , . . . , n + 1 i=0,1,...,n+1 i=0,1,...,n+1,定义前向向量 α i ( x ) \alpha_{i}(x) αi(x),则递推公式:
![]()
其中,

- step 2 后向计算
对每个指标 i = 0 , 1 , . . . , n + 1 i=0,1,...,n+1 i=0,1,...,n+1,定义前向向量 β i ( x ) \beta_{i}(x) βi(x),则递推公式:

- step 3
![]()
- step 4 概率计算
所以,标注序列在位置 i i i 是标注 y i y_i yi 的条件概率为:
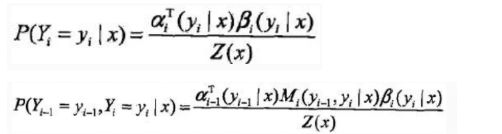
其中,
![]()
- step 5 期望值计算
通过利用前向-后向向量,计算特征函数关于联合概率分布 P ( X , Y ) P(X,Y) P(X,Y) 和 条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 的数学期望,即特征函数 f k f_k fk 关于条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 的数学期望:
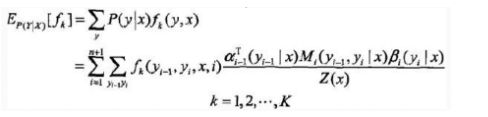
其中:

5. BFGS 算法
输入:特征函数 f 1 , f 2 , . . . , f n f_1,f_2,...,f_n f1,f2,...,fn:经验分布 P ~ ( X , Y ) \widetilde{P}(X,Y) P (X,Y);
输出:最优参数值 w ^ \widehat{w} w ,最优模型 P w ^ ( y ∣ x ) P_{\widehat{w}}(y|x) Pw (y∣x)。
- 选定初始点 w^{(0)}, 取 B 0 B_0 B0 为正定对称矩阵,k = 0;
- 计算 g k = g ( w ( k ) ) g_k = g(w^(k)) gk=g(w(k)),若 g k = 0 g_k = 0 gk=0 ,则停止计算,否则转 (3) ;
- 利用 B k p k = − g k B_k p_k = -g_k Bkpk=−gk 计算 p k p_k pk;
- 一维搜索:求 λ k \lambda_k λk使得
![]()
-
设 w ( k + 1 ) = w ( k ) + λ k ∗ p k w^{(k+1)} = w^{(k)} + \lambda_k * p_k w(k+1)=w(k)+λk∗pk
-
计算 g k + 1 g_{k+1} gk+1 = g(w^{(k+1)}),
若 g k = 0 g_k = 0 gk=0, 则停止计算;否则,利用下面公式计算 B k + 1 B_{k+1} Bk+1:
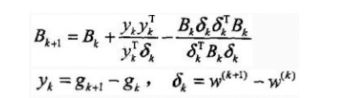
-
令 k = k + 1 k=k+1 k=k+1,转步骤(3);
6.预测问题
对于预测问题,常用的方法是维特比算法,其思路如下:
输入:模型特征向量 F ( y , x ) F(y,x) F(y,x) 和权重向量 w w w,输入序列(观测序列) x = x 1 , x 2 , . . . , x n x={x_1,x_2,...,x_n} x=x1,x2,...,xn;
输出:条件概率最大的输出序列(标记序列) y ∗ = ( y 1 ∗ , y 2 ∗ , . . . , y n ∗ ) y^{*}= (y_1^*,y_2^*,...,y_n^*) y∗=(y1∗,y2∗,...,yn∗),也就是最优路径;
- 初始化
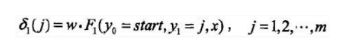
- 递推,对 i = 2 , 3 , . . . , n i=2,3,...,n i=2,3,...,n
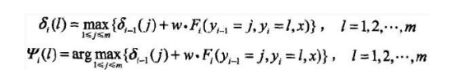
- 终止
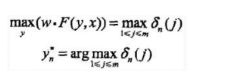
- 返回路径

求得最优路径 y ∗ = ( y 1 ∗ , y 2 ∗ , . . . , y n ∗ ) y^{*}= (y_1^*,y_2^*,...,y_n^*) y∗=(y1∗,y2∗,...,yn∗)
例子说明
利用维特比算法计算给定输入序列 x x x 对应的最优输出序列 y ∗ y^* y∗:
- 初始化
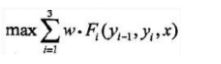
- 递推,对 i = 2 , 3 , . . . , n i=2,3,...,n i=2,3,...,n
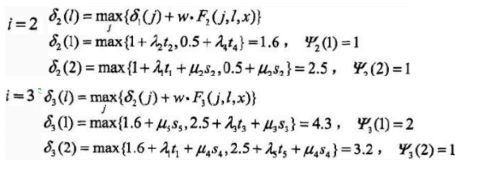
- 终止
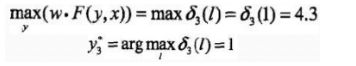
- 返回路径
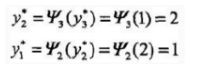
求得最优路径 y ∗ = ( y 1 ∗ , y 2 ∗ , . . . , y n ∗ ) = ( 1 , 2 , 1 ) y^{*}= (y_1^*,y_2^*,...,y_n^*) = (1,2,1) y∗=(y1∗,y2∗,...,yn∗)=(1,2,1)
import numpy as np
class CRF(object):
'''实现条件随机场预测问题的维特比算法
'''
def __init__(self, V, VW, E, EW):
'''
:param V:是定义在节点上的特征函数,称为状态特征
:param VW:是V对应的权值
:param E:是定义在边上的特征函数,称为转移特征
:param EW:是E对应的权值
'''
self.V = V #点分布表
self.VW = VW #点权值表
self.E = E #边分布表
self.EW = EW #边权值表
self.D = [] #Delta表,最大非规范化概率的局部状态路径概率
self.P = [] #Psi表,当前状态和最优前导状态的索引表s
self.BP = [] #BestPath,最优路径
return
def Viterbi(self):
'''
条件随机场预测问题的维特比算法,此算法一定要结合CRF参数化形式对应的状态路径图来理解,更容易理解.
'''
self.D = np.full(shape=(np.shape(self.V)), fill_value=.0)
self.P = np.full(shape=(np.shape(self.V)), fill_value=.0)
for i in range(np.shape(self.V)[0]):
#初始化
if 0 == i:
self.D[i] = np.multiply(self.V[i], self.VW[i])
self.P[i] = np.array([0, 0])
print('self.V[%d]='%i, self.V[i], 'self.VW[%d]='%i, self.VW[i], 'self.D[%d]='%i, self.D[i])
print('self.P:', self.P)
pass
#递推求解布局最优状态路径
else:
for y in range(np.shape(self.V)[1]): #delta[i][y=1,2...]
for l in range(np.shape(self.V)[1]): #V[i-1][l=1,2...]
delta = 0.0
delta += self.D[i-1, l] #前导状态的最优状态路径的概率
delta += self.E[i-1][l,y]*self.EW[i-1][l,y] #前导状态到当前状体的转移概率
delta += self.V[i,y]*self.VW[i,y] #当前状态的概率
print('(x%d,y=%d)-->(x%d,y=%d):%.2f + %.2f + %.2f='%(i-1, l, i, y, \
self.D[i-1, l], \
self.E[i-1][l,y]*self.EW[i-1][l,y], \
self.V[i,y]*self.VW[i,y]), delta)
if 0 == l or delta > self.D[i, y]:
self.D[i, y] = delta
self.P[i, y] = l
print('self.D[x%d,y=%d]=%.2f\n'%(i, y, self.D[i,y]))
print('self.Delta:\n', self.D)
print('self.Psi:\n', self.P)
#返回,得到所有的最优前导状态
N = np.shape(self.V)[0]
self.BP = np.full(shape=(N,), fill_value=0.0)
t_range = -1 * np.array(sorted(-1*np.arange(N)))
for t in t_range:
if N-1 == t:#得到最优状态
self.BP[t] = np.argmax(self.D[-1])
else: #得到最优前导状态
self.BP[t] = self.P[t+1, int(self.BP[t+1])]
#最优状态路径表现在存储的是状态的下标,我们执行存储值+1转换成示例中的状态值
#也可以不用转换,只要你能理解,self.BP中存储的0是状态1就可以~~~~
self.BP += 1
print('最优状态路径为:', self.BP)
return self.BP
def CRF_manual():
S = np.array([[1,1], #X1:S(Y1=1), S(Y1=2)
[1,1], #X2:S(Y2=1), S(Y2=2)
[1,1]]) #X3:S(Y3=1), S(Y3=1)
SW = np.array([[1.0, 0.5], #X1:SW(Y1=1), SW(Y1=2)
[0.8, 0.5], #X2:SW(Y2=1), SW(Y2=2)
[0.8, 0.5]])#X3:SW(Y3=1), SW(Y3=1)
E = np.array([[[1, 1], #Edge:Y1=1--->(Y2=1, Y2=2)
[1, 0]], #Edge:Y1=2--->(Y2=1, Y2=2)
[[0, 1], #Edge:Y2=1--->(Y3=1, Y3=2)
[1, 1]]])#Edge:Y2=2--->(Y3=1, Y3=2)
EW= np.array([[[0.6, 1], #EdgeW:Y1=1--->(Y2=1, Y2=2)
[1, 0.0]], #EdgeW:Y1=2--->(Y2=1, Y2=2)
[[0.0, 1], #EdgeW:Y2=1--->(Y3=1, Y3=2)
[1, 0.2]]])#EdgeW:Y2=2--->(Y3=1, Y3=2)
crf = CRF(S, SW, E, EW)
ret = crf.Viterbi()
print('最优状态路径为:', ret)
return
if __name__=='__main__':
CRF_manual()
self.V[0]= [1 1] self.VW[0]= [1. 0.5] self.D[0]= [1. 0.5]
self.P: [[0. 0.]
[0. 0.]
[0. 0.]]
(x0,y=0)-->(x1,y=0):1.00 + 0.60 + 0.80= 2.4000000000000004
(x0,y=1)-->(x1,y=0):0.50 + 1.00 + 0.80= 2.3
self.D[x1,y=0]=2.40
(x0,y=0)-->(x1,y=1):1.00 + 1.00 + 0.50= 2.5
(x0,y=1)-->(x1,y=1):0.50 + 0.00 + 0.50= 1.0
self.D[x1,y=1]=2.50
(x1,y=0)-->(x2,y=0):2.40 + 0.00 + 0.80= 3.2
(x1,y=1)-->(x2,y=0):2.50 + 1.00 + 0.80= 4.3
self.D[x2,y=0]=4.30
(x1,y=0)-->(x2,y=1):2.40 + 1.00 + 0.50= 3.9000000000000004
(x1,y=1)-->(x2,y=1):2.50 + 0.20 + 0.50= 3.2
self.D[x2,y=1]=3.90
self.Delta:
[[1. 0.5]
[2.4 2.5]
[4.3 3.9]]
self.Psi:
[[0. 0.]
[0. 0.]
[1. 0.]]
最优状态路径为: [1. 2. 1.]
最优状态路径为: [1. 2. 1.]