基于pytorch的CNN文本分类
20Newsgroups的部分数据集,一个四分类
model.py
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN_Text(nn.Module):
def __init__(self, args):
super(CNN_Text, self).__init__()
self.args = args
embed_num = args.embed_num
embed_dim = args.embed_dim
class_num = args.class_num
Ci = 1
kernel_num = args.kernel_num
kernel_sizes = args.kernel_sizes
self.embed = nn.Embedding(embed_num, embed_dim)
self.convs_list = nn.ModuleList(
[nn.Conv2d(Ci, kernel_num, (kernel_size, embed_dim)) for kernel_size in kernel_sizes])
self.dropout = nn.Dropout(args.dropout)
self.fc = nn.Linear(len(kernel_sizes) * kernel_num, class_num)
def forward(self, x):
x = self.embed(x)
x = x.unsqueeze(1)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs_list]
x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x]
x = torch.cat(x, 1)
x = self.dropout(x)
x = x.view(x.size(0), -1)
logit = self.fc(x)
return logit
mydataset.py
import os
import re
import tarfile
import urllib
from torchtext import data
class TarDataset(data.Dataset):
"""Defines a Dataset loaded from a downloadable tar archive.
Attributes:
url: URL where the tar archive can be downloaded.
filename: Filename of the downloaded tar archive.
dirname: Name of the top-level directory within the zip archive that
contains the data files.
"""
@classmethod
def download_or_unzip(cls, root):
path = os.path.join(root, cls.dirname)
if not os.path.isdir(path):
tpath = os.path.join(root, cls.filename)
if not os.path.isfile(tpath):
print('downloading')
urllib.request.urlretrieve(cls.url, tpath)
with tarfile.open(tpath, 'r') as tfile:
print('extracting')
tfile.extractall(root)
return os.path.join(path, '')
class NEWS_20(TarDataset):
url = 'http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz'
filename = 'data/20news-bydate-train'
dirname = ''
@staticmethod#以后重构类的时候不必要修改构造函数,只需要额外添加你要处理的函数,然后使用装饰符 @classmethod 就可以了
def sort_key(ex):
return len(ex.text)
def __init__(self, text_field, label_field, path=None, text_cnt=1000, examples=None, **kwargs):
"""Create an MR dataset instance given a path and fields.
Arguments:
text_field: The field that will be used for text data.
label_field: The field that will be used for label data.
path: Path to the data file.
examples: The examples contain all the data.
Remaining keyword arguments: Passed to the constructor of
data.Dataset.
"""
def clean_str(string):
"""
Tokenization/string cleaning for all datasets except for SST.
Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
"""
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip().lower()
text_field.preprocessing = data.Pipeline(clean_str)
fields = [('text', text_field), ('label', label_field)]
categories = ['alt.atheism', 'comp.graphics', 'sci.med', 'soc.religion.christian']#20Newsgroups新闻中的四组数据
if examples is None:
path = self.dirname if path is None else path
examples = []
for sub_path in categories:
sub_path_one = os.path.join(path, sub_path)
sub_paths_two = os.listdir(sub_path_one)
cnt = 0
for sub_path_two in sub_paths_two:
lines = ""
with open(os.path.join(sub_path_one, sub_path_two), encoding="utf8", errors='ignore') as f:
lines = f.read()
examples += [data.Example.fromlist([lines, sub_path], fields)]
cnt += 1
super(NEWS_20, self).__init__(examples, fields, **kwargs)
def splits(cls, text_field, label_field, root='./data',
train='20news-bydate-train', test='20news-bydate-test',
**kwargs):
"""Create dataset objects for splits of the 20news dataset.
Arguments:
text_field: The field that will be used for the sentence.
label_field: The field that will be used for label data.
train: The filename of the train data. Default: 'train.txt'.
Remaining keyword arguments: Passed to the splits method of
Dataset.
"""
path = cls.download_or_unzip(root)
train_data = None if train is None else cls(
text_field, label_field, os.path.join(path, train), 2000, **kwargs)
dev_ratio = 0.1
dev_index = -1 * int(dev_ratio * len(train_data))
return (cls(text_field, label_field, examples=train_data[:dev_index]),
cls(text_field, label_field, examples=train_data[dev_index:]))
text_classification.py
import argparse
import random
import model
import mydatasets
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchtext.data as data
# import torch.nn.init.xavier_uniform_ as xavier
# random_state = 11892 #92%
random_state = 11117 # 20 94.22%
torch.manual_seed(random_state)
torch.cuda.manual_seed(random_state)
torch.cuda.manual_seed_all(random_state)
np.random.seed(random_state)
random.seed(random_state)
# lr = 0.001 , 17 ,95.11%
# 13 , 96.88%
parser = argparse.ArgumentParser(description='CNN text classificer')
# learning
parser.add_argument('-lr', type=float, default=0.001, help='initial learning rate [default: 0.001]')
parser.add_argument('-epochs', type=int, default=20, help='number of epochs for train [default: 20]')
parser.add_argument('-batch-size', type=int, default=64, help='batch size for training [default: 64]')
# data
parser.add_argument('-shuffle', action='store_true', default=False, help='shuffle the data every epoch')
# model
parser.add_argument('-dropout', type=float, default=0.2, help='the probability for dropout [default: 0.5]')
parser.add_argument('-embed-dim', type=int, default=100, help='number of embedding dimension [default: 128]')
parser.add_argument('-kernel-num', type=int, default=128, help='number of each kind of kernel, 100')
parser.add_argument('-kernel-sizes', type=str, default='3,5,7',
help='comma-separated kernel size to use for convolution')
parser.add_argument('-static', action='store_true', default=False, help='fix the embedding')
# device
parser.add_argument('-device', type=int, default=-1, help='device to use for iterate data, -1 mean cpu [default: -1]')
parser.add_argument('-no-cuda', action='store_true', default=False, help='disable the gpu')
args = parser.parse_args()
# load 20new dataset
def new_20(text_field, label_field, **kargs):
train_data, dev_data = mydatasets.NEWS_20.splits(text_field, label_field)
max_document_length = max([len(x.text) for x in train_data.examples])
print('train max_document_length', max_document_length)#train max_document_length 9168train max_document_length 9168
max_document_length = max([len(x.text) for x in dev_data])
print('dev max_document_length', max_document_length)#dev max_document_length 2533
text_field.build_vocab(train_data, dev_data)
text_field.vocab.load_vectors('glove.6B.100d')
label_field.build_vocab(train_data, dev_data)
train_iter, dev_iter = data.Iterator.splits(
(train_data, dev_data),
batch_sizes=(args.batch_size, len(dev_data)),
**kargs)
return train_iter, dev_iter, text_field
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv2d') != -1:
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
nn.init.xavier_normal_(m.weight.data)
m.bias.data.fill_(0)
elif classname.find('Linear') != -1:
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
# load data
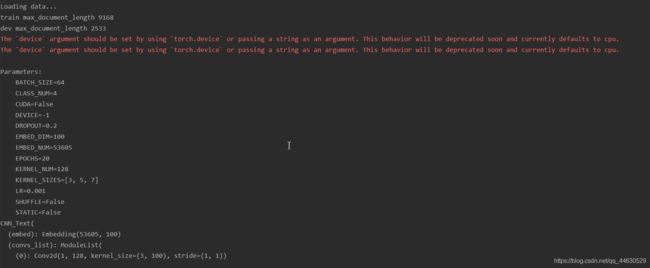
print("\nLoading data...")
text_field = data.Field(lower=True)
label_field = data.Field(sequential=False)
train_iter, dev_iter, text_field = new_20(text_field, label_field, device=-1, repeat=False)
# update args and print
args.embed_num = len(text_field.vocab)
args.class_num = len(label_field.vocab) - 1
args.cuda = (not args.no_cuda) and torch.cuda.is_available();
del args.no_cuda
args.kernel_sizes = [int(k) for k in args.kernel_sizes.split(',')]
print("\nParameters:")
for attr, value in sorted(args.__dict__.items()):
print("\t{}={}".format(attr.upper(), value))
# model
cnn = model.CNN_Text(args)
# load pre-training glove model
cnn.embed.weight.data = text_field.vocab.vectors
# weight init
cnn.apply(weights_init) #
# print net
print(cnn)
'''
CNN_Text(
(embed): Embedding(53605, 100)
(convs_list): ModuleList(
(0): Conv2d (1, 128, kernel_size=(3, 100), stride=(1, 1))
(1): Conv2d (1, 128, kernel_size=(5, 100), stride=(1, 1))
(2): Conv2d (1, 128, kernel_size=(7, 100), stride=(1, 1))
)
(dropout): Dropout(p=0.2)
(fc): Linear(in_features=384, out_features=4)
)
'''
if args.cuda:
torch.cuda.set_device(args.device)
cnn = cnn.cuda()
optimizer = torch.optim.Adam(cnn.parameters(), lr=args.lr, weight_decay=0.01)
# train
cnn.train()
for epoch in range(1, args.epochs + 1):
corrects, avg_loss = 0, 0
for batch in train_iter:
feature, target = batch.text, batch.label
feature.t_(), target.sub_(1) # batch first, index align
if args.cuda:
feature, target = feature.cuda(), target.cuda()
optimizer.zero_grad()
logit = cnn(feature)
loss = F.cross_entropy(logit, target)
loss.backward()
optimizer.step()
avg_loss += loss.item()
corrects += (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()
size = len(train_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects / size
print('epoch[{}] Traning - loss: {:.6f} acc: {:.4f}%({}/{})'.format(epoch,
avg_loss,
accuracy,
corrects,
size))
# test
cnn.eval()
corrects, avg_loss = 0, 0
for batch in dev_iter:
feature, target = batch.text, batch.label
feature.t_(), target.sub_(1) # batch first, index align
if args.cuda:
feature, target = feature.cuda(), target.cuda()
logit = cnn(feature)
loss = F.cross_entropy(logit, target, size_average=False)
avg_loss += loss.item()
corrects += (torch.max(logit, 1)
[1].view(target.size()).data == target.data).sum()
size = len(dev_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects / size
print('Evaluation - loss: {:.6f} acc: {:.4f}%({}/{}) '.format(avg_loss,
accuracy,
corrects,
size))
结果
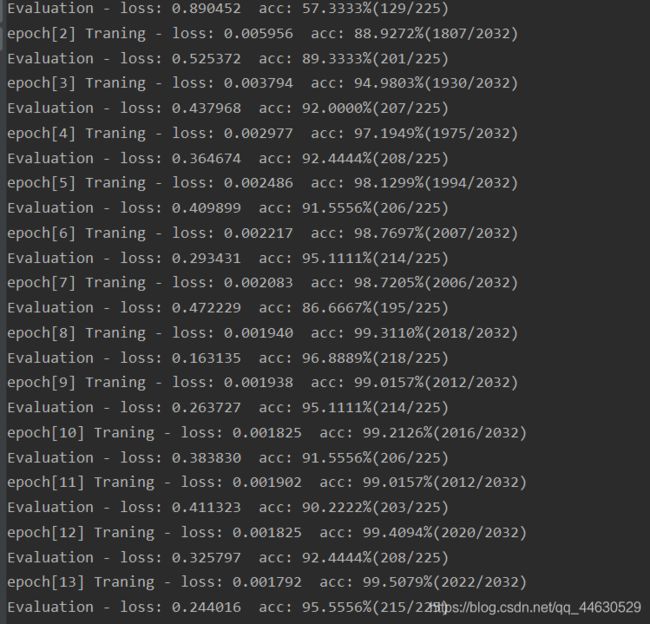
仅仅记录,新手,代码都放了,数据地址上面也有,有问题行解决,不接受留言。