pytorch 实现 textCNN
textCNN 模型
textCNN模型主要使用了一维卷积层和时序最大池化层。
一维卷积层相当于高为1的二维卷积层,多输入通道的一维互相关运算也与多输入通道的二维互相关运算类似:在每个通道上,将核与相应的输入做一维互相关运算,并将通道之间的结果相加得到输出结果。

时序最大池化(max-over-time pooling)层实际上对应一维全局最大池化层,特点是卷积窗口和输入数组的宽高对应相同,每个通道只输出一个元素。
假设输入的文本序列由 n n n个词组成,每个词用 d d d维的词向量表示。那么输入样本的宽为 n n n,高为1,输入通道数为 d d d。textCNN的计算主要分为以下几步。
- 定义多个一维卷积核,并使用这些卷积核对输入分别做卷积计算。宽度不同的卷积核可能会捕捉到不同个数的相邻词的相关性。
- 对输出的所有通道分别做时序最大池化,再将这些通道的池化输出值连结为向量。
- 通过全连接层将连结后的向量变换为有关各类别的输出。这一步可以使用丢弃层应对过拟合。
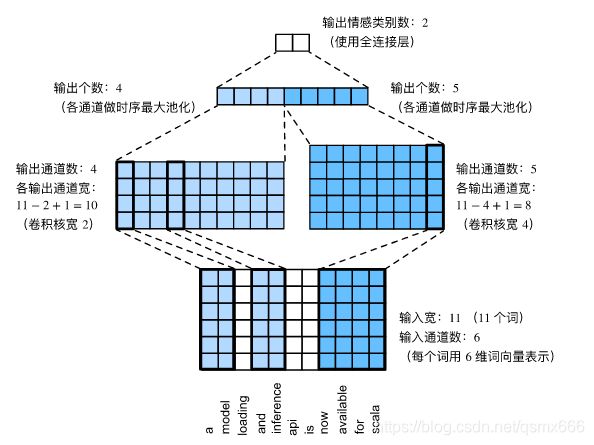
上图用一个例子解释了textCNN的设计。这里的输入是一个有11个词的句子,每个词用6维词向量表示。因此输入序列的宽为11,输入通道数为6。给定2个一维卷积核,核宽分别为2和4,输出通道数分别设为4和5。因此,一维卷积计算后,4个输出通道的宽为11−2+1=10,而其他5个通道的宽为11−4+1=8。尽管每个通道的宽不同,我们依然可以对各个通道做时序最大池化,并将9个通道的池化输出连结成一个9维向量。最终,使用全连接将9维向量变换为2维输出,即正面情感和负面情感的预测(概率)。
pytorch 实现
这部分代码主要参考:
文本分类系列(1):textcnn及其pytorch实现.
导入包
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
import jieba
import os
from torch.nn import init
from torchtext import data
from torchtext.vocab import Vectors
import time
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据预处理
这是一个汽车评论数据集,训练集和测试集是分开的,格式如下。

这里我们要用到pytorch中的文本处理工具包torchtext。
torchtext预处理流程:
- 定义Field:声明如何处理数据。
- 定义Dataset:得到数据集,此时数据集里每一个样本是一个经过 Field声明的预处理后的 wordlist。
- 建立vocab:在这一步建立词汇表,词向量(word embeddings)。
- 构造迭代器:构造迭代器,用来分批次训练模型
首先定义分词和去停用词的函数。
# 分词
def tokenizer(text):
return [word for word in jieba.lcut(text) if word not in stop_words]
# 去停用词
def get_stop_words():
file_object = open('data/stopwords.txt',encoding='utf-8')
stop_words = []
for line in file_object.readlines():
line = line[:-1]
line = line.strip()
stop_words.append(line)
return stop_words
定义field
stop_words = get_stop_words() # 加载停用词表
text = data.Field(sequential=True,
lower=True,
tokenize=tokenizer,
stop_words=stop_words)
label = data.Field(sequential=False)
定义Dataset
Torchtext有大量内置的Datasets去处理各种数据格式。对于csv/tsv类型的文件,我们选TabularDataset来生成Dataset。
train, val = data.TabularDataset.splits(
path='data/',
skip_header=True,
train='train.tsv',
validation='validation.tsv',
format='tsv',
fields=[('index', None), ('label', label), ('text', text)],
)
注意这里传入的(name, field)必须与列的顺序相同,由于我们不需要index列, 所以给相应的field传递 None。
可以查看train的元素。
print(train[0].text)
![]()
建立vocab
text.build_vocab(train, val, vectors=Vectors(name='data/myvector.vector'))#加入测试集的vertor
label.build_vocab(train, val)
embedding_dim = text.vocab.vectors.size()[-1]
vectors = text.vocab.vectors
这里的词向量是我用训练集和测试集的文本训练的,也可以用其他训练好的词向量。
构造迭代器
batch_size=128
train_iter, val_iter = data.Iterator.splits(
(train, val),
sort_key=lambda x: len(x.text),
batch_sizes=(batch_size, len(val)), # 训练集设置batch_size,验证集整个集合用于测试
)
vocab_size = len(text.vocab)
label_num = len(label.vocab)
模型
由于PyTorch没有自带全局的最大池化层,所以我们可以通过普通的池化来实现全局池化。
class GlobalMaxPool1d(nn.Module):
def __init__(self):
super(GlobalMaxPool1d, self).__init__()
def forward(self, x):
# x shape: (batch_size, channel, seq_len)
return F.max_pool1d(x, kernel_size=x.shape[2]) # shape: (batch_size, channel, 1)
模型结构如下:
class TextCNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, kernel_sizes, num_channels):
super(TextCNN, self).__init__()
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim) # embedding之后的shape: torch.Size([200, 8, 300])
self.word_embeddings = self.word_embeddings.from_pretrained(vectors, freeze=False)
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Linear(sum(num_channels), 2)
# 时序最大池化层没有权重,所以可以共用一个实例
self.pool = GlobalMaxPool1d()
self.convs = nn.ModuleList() # 创建多个一维卷积层
for c, k in zip(num_channels, kernel_sizes):
self.convs.append(nn.Conv1d(in_channels = embedding_dim,
out_channels = c,
kernel_size = k))
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
embeds = embeds.permute(0, 2, 1)
# 对于每个一维卷积层,在时序最大池化后会得到一个形状为(批量大小, 通道大小, 1)的
# Tensor。使用flatten函数去掉最后一维,然后在通道维上连结
encoding = torch.cat([self.pool(F.relu(conv(embeds))).squeeze(-1) for conv in self.convs], dim=1)
# 应用丢弃法后使用全连接层得到输出
outputs = self.decoder(self.dropout(encoding))
return outputs
训练
初始化TextCNN实例。
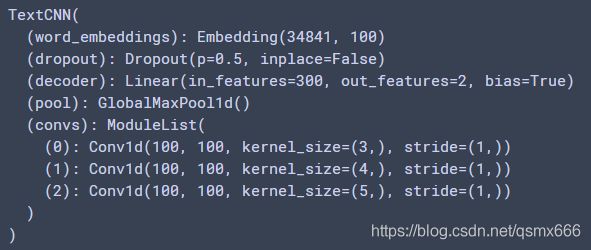
embedding_dim, kernel_sizes, num_channels = 100, [3, 4, 5], [100, 100, 100]
net = TextCNN(vocab_size, embedding_dim, kernel_sizes, num_channels)
print(net)
训练过程:
def train(train_iter, test_iter, net, loss, optimizer, num_epochs):
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for batch_idx, batch in enumerate(train_iter):
X, y = batch.text, batch.label
X = X.permute(1, 0)
y.data.sub_(1) #X转置 y为啥要减1
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print(
'epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n,
test_acc, time.time() - start))
y.data.sub_(1)这句代码我没明白,如果删掉会出现“out of bound”的错误,再看吧。
计算准确率:
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
with torch.no_grad():
for batch_idx, batch in enumerate(data_iter):
X, y = batch.text, batch.label
X = X.permute(1, 0)
y.data.sub_(1) #X转置 y为啥要减1
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else: # 自定义的模型, 3.13节之后不会用到, 不考虑GPU
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
训练。
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
train(train_iter, val_iter, net, loss, optimizer, num_epochs)
输出结果

https://github.com/WHLYA/text-classification.