datawhale组队学习——pandas基础下——文本数据
学习资源链接:pandas文本数据
一、总览
二、正则表达式
正则表达式详情请看这里正则表达式
这篇正则表达式下面有一个内容是要你输入一个正则表达式,然后看你的是否与上面给的一系列字符匹配。如下图:

并附上正则表达式手册
现在这里列出一些符号的含义吧
\d 对于Unicode(str类型)模式:匹配任何一个数字,包括[0-9]和其他数字字符;
如果开启了re.ASCII,只匹配 [0-9]对于8位(bytes类型)模式:匹配[0-9]中任何一个数字\D与\d相反,如果开启了re.ASCII,只匹配 [^0-9]
\D 匹配一个非数字字符。等价于[^0-9]
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字 等价于 ‘[A-Za-z0-9_]’。
问:[a-zA-Z0-9]和[0-9a-zA-Z]有什么不同?
答:没有不同,与顺序无关,都是表示了小写字母、大写字母、整数数字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$匹配字符串的结束
+表示重复一次或者多次
*表示重复零次或者多次
具体见下图
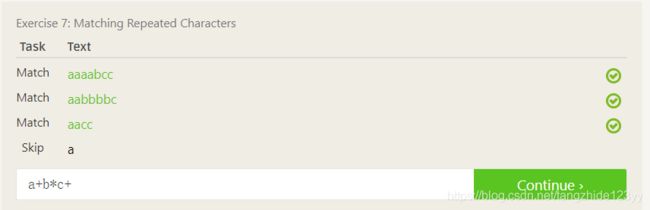
{n,m} 表示n 到 m 次
\w能不能匹配汉字要视你的操作系统和你的应用环境而定
the pattern [abc] will only match a single a, b, or c letter and nothing else.这句话的意思是只要需要匹配的那个字符里面含有abc其中一个字符就好了,就是匹配的
the pattern [^abc] will match any single character except for the letters a, b, or c.这句话的意思是除了abc这三个字符之外会匹配任何一个字符。
the pattern [0-6] will only match any single digit character from zero to six, and nothing else. And likewise, [^n-p] will only match any single character except for letters n to p.
这里与上面那个一样,只是把字母换成了数字
? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。
(?:pattern) 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
For example, the pattern ab?c will match either the strings “abc” or “ac” because the b is considered optional.这句话的意思就是说b可选可不选,可以匹配abc和ac两种
Similar to the dot metacharacter, the question mark is a special character and you will have to escape it using a slash ? to match a plain question mark character in a string.这句话的意思就是如果要匹配问号,得在前面加一个\来匹配问号。见下图:
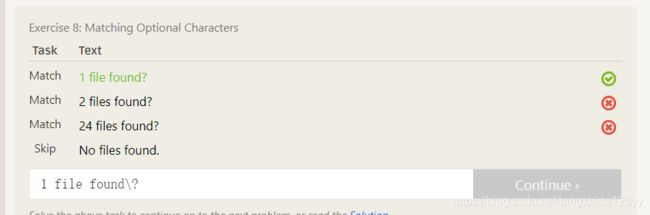
\f 匹配一个换页符。等价于\x0c和\cL。
\n 匹配一个换行符。等价于\x0a和\cJ。
\r 匹配一个回车符。等价于\x0d和\cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于\x09和\cI。
\v 匹配一个垂直制表符。等价于\x0b和\cK。
三、思考题
【问题一】 str对象方法和df/Series对象方法有什么区别?
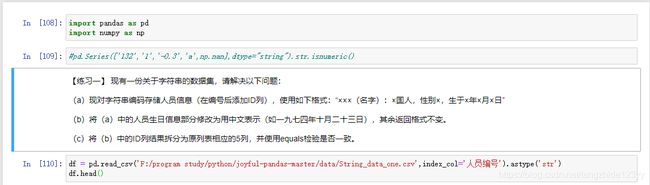
【问题二】 给出一列string类型,如何判断单元格是否是数值型数据?
pd.Series(['1.2','1','-0.3','a',np.nan],dtype="string").str.isnumeric()
【问题三】 rsplit方法的作用是什么?它在什么场合下适用?
split()正分割列; rsplit逆序分割列
s = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'], dtype="string")
s
s.str.split('_')
rsplit()是逆序分割,当我们最后面有几列需要单独分割出来,而且由于数列比较多从正着数不知道第几列或者每一行列数不一样而我们只需要最后一列,在这种情况下是需要用到rsplit()的
【问题四】 在本章的第二到第四节分别介绍了字符串类型的5类操作,请思考它们各自应用于什么场景?
- str.split方法
根据某一个元素分割,默认为空格 - str.cat方法
对于单个Series而言,就是指所有的元素进行字符合并为一个字符串
对于两个Series合并而言,是对应索引的元素进行合并 - str.replace
str.replace针对的是object类型或string类型,默认是以正则表达式为操作,目前暂时不支持DataFrame上使用 - str.extract方法(子串匹配与提取)
利用?正则标记选择部分提取 - str.extractall方法
与extract只匹配第一个符合条件的表达式不同,extractall会找出所有符合条件的字符串,并建立多级索引(即使只找到一个) - str.contains和str.match
前者的作用为检测是否包含某种正则模式,并且可选参数为na,此时如果是na参会返回true。
str.match与其区别在于,match依赖于python的re.match,检测内容为是否从头开始包含该正则模式
四、练习题
【练习一】 现有一份关于字符串的数据集,请解决以下问题:
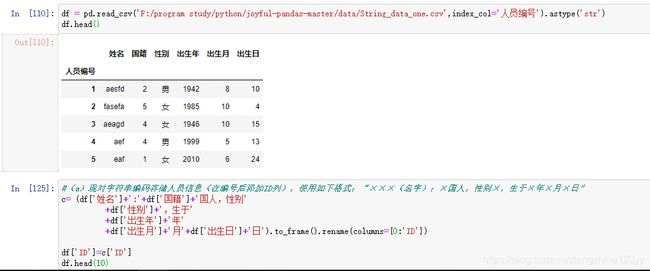
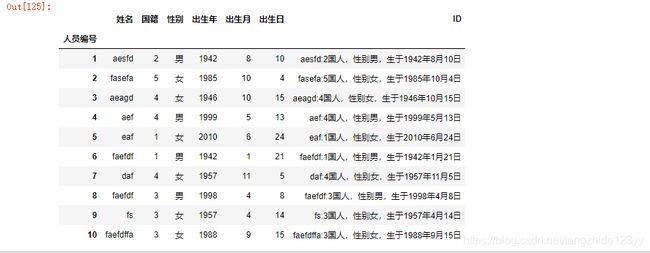
(a)现对字符串编码存储人员信息(在编号后添加ID列),使用如下格式:“×××(名字):×国人,性别×,生于×年×月×日”
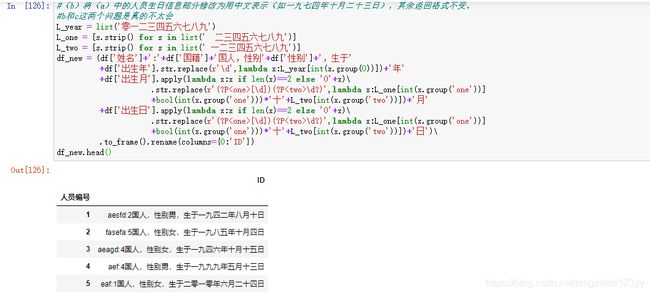
(b)将(a)中的人员生日信息部分修改为用中文表示(如一九七四年十月二十三日),其余返回格式不变。
(c)将(b)中的ID列结果拆分为原列表相应的5列,并使用equals检验是否一致。
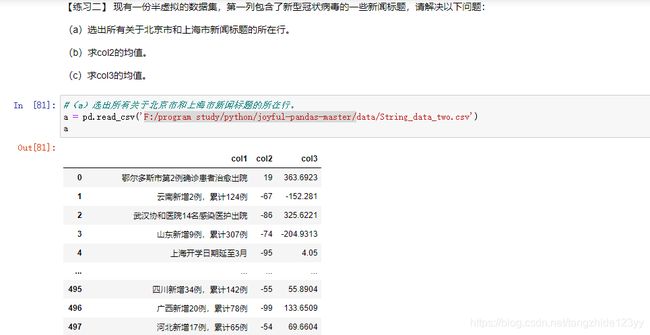
【练习二】 现有一份半虚拟的数据集,第一列包含了新型冠状病毒的一些新闻标题,请解决以下问题:
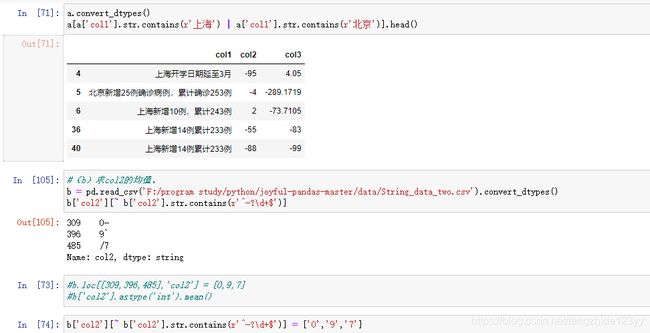
(a)选出所有关于北京市和上海市新闻标题的所在行。
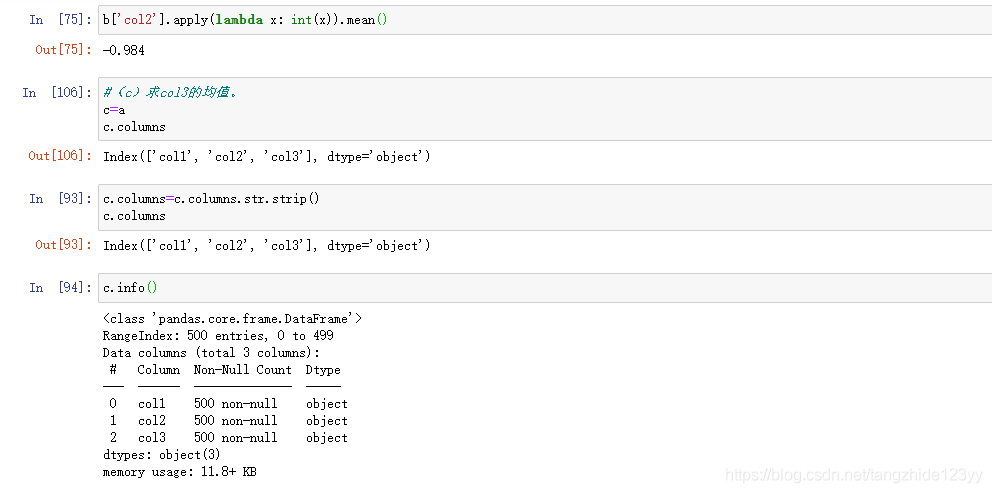
(b)求col2的均值。
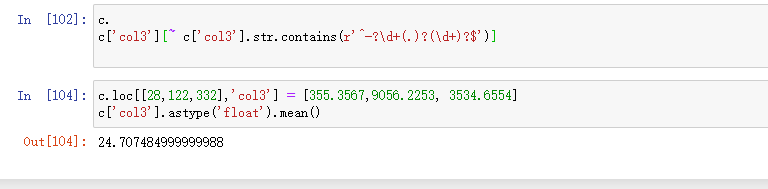
(c)求col3的均值。
五、程序代码及相关注释
因暂时不清楚如何将jupyter上写的导入到这个里面来,就暂时截图,把图片放上来。