读《Which Training Methods for GANs do actually Converge?》
前言
我读完这篇论文,饱受震撼,深受启发。
我认为的这是非常不错的启蒙读物,于是萌生出写一写的念头。
大概19.2.25开始看,断断续续几天才有了个概念,后面学网课,做模型,刷OJ。
今天从杭州回来,才有时间着手开始写这篇文章(19.3.3)。
打算弄一些简单的翻译,然后写一些个人的注解,然后在实践层面理解这篇论文的引入的正则项。
由于目前的水平能力有限,对原理只能用抽象和比喻的方法来理解,示例图片均为自己制作,望海涵。
原文传送门:https://arxiv.org/abs/1801.04406v4
感谢作者:Lars Mescheder, Andreas Geiger, Sebastian Nowozin
一、简介部分
Introduction
Generative Adversarial Networks (GANs) (Goodfellow et al., 2014) are powerful latent variable models that can be
used to learn complex real-world distributions. Especially for images, GANs have emerged as one of the dominant approaches for generating new realistically looking samples after the model has been trained on some dataset.
生成式对抗网络(GANs)(Goodfellow等人在2014提出)是一种强大的潜变量(latent variable)模型,它能被用来学习真实世界里的许多复杂分布。尤其是在图像领域,只需要经过一定的数据集训练,GANs在生成以假乱真的图片方面就显示出支配性的强大。
However, while very powerful, GANs can be hard to train and in practice it is often observed that gradient descent based GAN optimization does not lead to convergence. As a result, a lot of recent research has focused on finding better training algorithms (Arjovsky et al., 2017; Gulrajani et al., 2017; Kodali et al., 2017; Sønderby et al., 2016; Roth et al., 2017) for GANs as well as gaining better theoretically understanding of their training dynamics (Arjovsky et al., 2017; Arjovsky & Bottou, 2017; Mescheder et al., 2017;Nagarajan & Kolter, 2017; Heusel et al., 2017).
尽管GANs十分强大,但在实践中,人们经常观察到GANs很难通过梯度下降的优化方式训练到收敛。所以近来许多研究者开始研究更好的算法来训练GAN(如Arjovsky等2017;Kodali等2017;Sønderby等2016;Roth等2017),也想从侧面加深对训练过程( training dynamics)的理解(如Arjovsky等2017;Arjovsky 与 Bottou 2017;Mescheder等2017;Nagarajan 与 Kolte 2017;Heusel 等2017)。
//备注,显而易见,这个叫Arjovsky的老哥非常活跃
这是GAN学届的扛把子人物,写了两篇论文,一篇分析了原始GAN存在的问题,一篇提出了新的WGAN模型来解决这个问题。
开启了一整个新时代。
下面这段很重要。
Despite practical advances, the training dynamics of GANs are still not completely understood.
Recently, Mescheder et al. (2017) and Nagarajan & Kolter (2017) showed that local convergence and stability properties of GAN training can be analyzed by examining the eigenvalues of the Jacobian of the the associated gradient vector field: if the Jacobian has only eigenvalues with negative real-part at the equilibrium point, GAN training converges locally for small enough learning rates. On the other hand, if the Jacobian has eigenvalues on the imaginary axis, it is generally not locally convergent.
尽管实践上有所进步,人们对GANs的训练过程仍然一知半解。
直到近来,Mescheder et 等人(2017) ,以及 Nagarajan 与 Kolter二人 (2017) ,先后发现了GAN训练中的局部收敛和稳定性(stability properties)可以通过检查『联立梯度矢量场(gradient vector field)形成的雅可比矩阵(Jacobian)的特征值』来分析。
如果雅克比在平衡点的特征值仅有负实部,GAN的训练总能在一个很小的学习速率下局部收敛。
反之,如果雅克比矩阵的特征值有虚轴(imaginary axis)部分,那么一般不会局部收敛。
这段话里的知识超出了过往所学,但我们可以通过查询资料进行直观的理解。
首先定位到知识体系为 数学->数值分析。 就是说想进一步学习,去买任意一本数值分析的书来看。
参考百科
考虑线性方程组Ax = b时,对于由工程技术中产生的大型稀疏矩阵方程组(A的阶数很高,但零元素较多,例如求某些偏微分方程数值解所产生的线性方程组),利用迭代法求解此方程组就是合适的,在计算机内存和运算两方面,迭代法通常都可利用A中有大量零元素的特点。雅克比迭代法的计算公式简单,每迭代一次只需计算一次矩阵和向量的乘法,且计算过程中原始矩阵A始终不变,比较容易并行计算。
设Ax= b,其中A=D+L+U为非奇异矩阵,且对角阵D也非奇异,则当迭代矩阵J的谱半径ρ(J)<1时,雅克比迭代法收敛。
可以简单的理解为,雅克比迭代法就是我们用来更新loss的一种方法。
谱半径就是特征值模长的最大值,当谱半径小于1时,迭代法收敛,半径越小收敛越快。
再简化一点,便于我们直观理解,||λ||<1,则收敛;||λ||越趋近于0,则收敛越快。
而在GAN训练中,我们对loss function只考察一个方向,就是向下收敛,所以理论上要求实轴部分为负数。
那么只要learning rate足够小,我们龟速移动总能走到那个收敛点,很好理解。
所以说,可以通过分析『联立梯度矢量场(gradient vector field)形成的雅可比矩阵(Jacobian)的特征值』这个名字很长东西,来分析模型的收敛性。
这就是数学工具在GAN领域的应用迁移。
PS:如果你想具体知道何为梯度矢量场......
其实就是把对θ求梯度得到的列向量,和对φ求梯度得到的列向量,在垂直方向上上下连起来。
下图为原文内容

//Vaishnavh Nagarajan, J. Zico Kolter原文传送门:https://arxiv.org/abs/1706.04156
回到论文的翻译。
Moreover, Mescheder et al. (2017) showed that if there are eigenvalues close but not on the imaginary axis, the training algorithm can require intractably small learning rates to achieve convergence.
进一步的, Mescheder等人 (2017) 发现了,如果特征值很接近但并不在虚轴上,那么训练算法可以通过输入一个非常非常棘手的超级微小的学习速率来取得局部收敛。
可以通过公式证明,上面说的那个特征值λ呢,可以拆成实轴+虚轴的部分。(虚轴部分来自对一个固定项的开方,如果这项为负数就会开出一个虚轴i来。)
前面那位Nagarajan证明了,虚轴如果存在,必定存在一对共轭的λ(很好理解),那么模型就无法收敛。
写成公式就是,λ=a±bi
直观理解:如果λ表示收敛性,那么当λ不唯一时,这个模型的收敛性是在一对共轭复数λ之间摇摆的,自然就无法达成一致收敛。
而现在这位 Mescheder呢,进一步细化了Nagarajan的结论,他发现了,哪怕实轴部分是负数(Nagarajan的结论是只要实轴负数就可以用小速率抵达收敛),模型的训练还是会不稳定。
因为一旦“要开方的那一项”无限接近于0,那么就无限接近于要开出一个虚轴部分来,那么这时候就需要一个 intractably small learning rates 才能收敛 。
但我们一般训练模型不可能设置这么小的学习速率啊!
例如理论计算表明α=0.00000000001才能收敛,计算机精度都未必够用,我们不可能取到这么小的学习速率,这样也会很花时间。
直观理解:
如果学习速率不够小,小球就会飞过去,掉不下去的......但一般人想不到要用那么小的速率,或者想到了也做不到,所以带来了不稳定(training instability)。
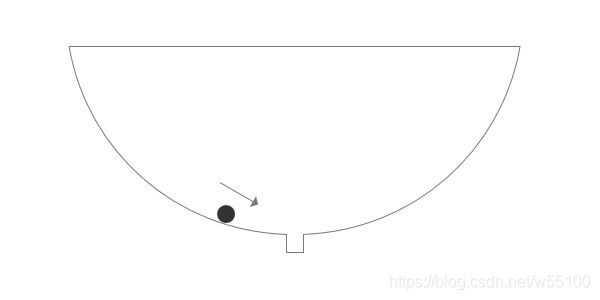
//Mescheder原文The numerics of gans.传送门: https://arxiv.org/abs/1705.10461
继续论文翻译。
While Mescheder et al. (2017) observed eigenvalues close to the imaginary axis in practice, this observation does not answer the question if eigenvalues close to the imaginary axis are a general phenomenon and if yes, whether they are indeed the root cause for the training
尽管 Mescheder 等人 (2017) 发现了实践中特征值经常靠近虚轴,但是他们也没能回答,是不是特征值靠近虚轴是个一般现象。如果是的话,『实践中特征值经常会靠近虚轴』这件事,是不是就是实践中人们观察到不稳定的最根本原因。
A partial answer to this question was given by Nagarajan & Kolter (2017), who showed that for absolutely continuous
data and generator distributions1 all eigenvalues of the Jacobian have negative real-part. As a result, GANs are locally
convergent for small enough learning rates in this case.However, the assumption of absolute continuity is not true for common use cases of GANs, where both distributions may lie on lower dimensional manifolds (Sønderby et al.,
2016; Arjovsky & Bottou, 2017).Nagarajan & Kolter (2017),给出了部分回答。
他们发现,对于绝对连续(absolutely continuous)的数据和生成器分布来说,雅克比矩阵的所有特征值都有负的实部。因此,这些GANs能够用一个很小的学习速率来局部收敛。
但是这个关于绝对连续的假设在日常实践中往往是不成立的,往往日常所用的数据分布和生成器分布都位于低维流形上。(意思是说低维流形一般不绝对连续)
怎么理解低维流型一般不绝对连续?
比如我们训练GAN的时候,从正态分布里弄出一个噪声Z(例如100维),然后经过一个神经网络,把它映射到65536维(256x256的图片)的高维空间中。
它的本质维度只有100维,显然填不满整个高维空间。
而我们只是需要生成特定的一种图片分布,比如猫的图片,狗的图片,花花草草的图片。
这种特定的分布就凑成了一个高维空间中的低维流形。
我们学习到的映射只是从源分布Z~Norm(0,1),到目标分布Y的一个映射关系。
而且经过100维->65536维的映射,很容易想象到数据被打散了,大概率也不连续了。
画图举例:
在2D平面上的一个连续的源分布Z,映射到高维空间后,变成离散的状态。
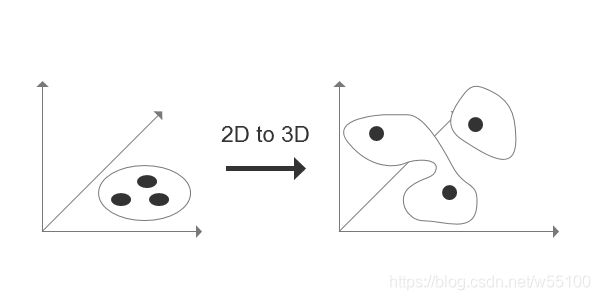
In this paper we show that this assumption is indeed necessary: by considering a simple yet prototypical example
of GAN training we analytically show that (unregularized) GAN training is not always locally convergent.而本论文证明了,上述关于绝对连续的假设,事实上是必要条件。
首先,通过构造一个反例,我们可以证明无正则的GAN训练并不总是收敛。
意思是说(骄傲地抬起头),我们证明了,“数据和生成器分布具备绝对连续性”是“GAN模型训练会局部收敛”的必要条件。
We also discuss how recent techniques for stabilizing GAN training affect local convergence on our example problem. Our
findings show that neither Wasserstein GANs (WGANs) (Arjovsky et al., 2017) nor Wasserstein GANs with Gradient Penalty (WGAN-GP) (Gulrajani et al., 2017) nor DRAGAN (Kodali et al., 2017) converge on this simple example for a
fixed number of discriminator updates per generator update.然后,我们也讨论了最近的一些试图稳定GAN的技术到底是如何对局部收敛施加影响的。
在我们构造的反例上,在保证每次生成器迭代时、鉴别器只迭代固定次数的条件下,无论是大名鼎鼎的WGAN,还是带正则形态的WGAN-GP,或者是DRAGAN,都不能收敛。
(依然能感觉到骄傲的语气......)
这里是这样的,作者应该是自己构造了一个不绝对连续的分布,但是特征值依然有负的实部,也没有虚轴部分,然后用它来当input去训练不同的GAN,然后看别人的模型收不收敛。
然后结果证明了,在这个不绝对连续的分布上几个著名GAN都不能收敛。
说明要想收敛,满足前面说的雅克比矩阵的特征值的要求(负实轴+无虚轴)是不充分的,起码还要满足绝对连续。
On the other hand, we show that instance noise (Sønderby et al., 2016; Arjovsky & Bottou, 2017), zero-centered gradient penalties (Roth et al., 2017) and consensus optimization (Mescheder et al., 2017) lead to local convergence.
另一方面,我们展示了实例噪声(instance noise)(Sønderby等 2016;Arjovsky 与Bottou 2017),
零均值化的梯度惩罚(zero-centered gradient penalties)(Roth 等2017),
以及一致优化(consensus optimization) (Mescheder 等2017)能带来局部收敛。
这里介绍了GAN发展史上三个重要的tricky技巧。
1.实例噪声(instance noise)
我看了很久,然后通过后面的作者Arjovsky老哥,确定了这就是那个......很像模拟退火的方法。
上回我们说到,Arjovsky老哥惊为天人的写了两篇论文,第一篇指出了原始GAN哪里不好,第二篇把计算loss function的KL散度换成了Wasserstein散度,提出了WGAN模型。
那么在第一篇论文发表,第二篇WGAN还没提出的时候,人类要怎么解决原始GAN的那些缺点呢。
就是通过往data_real和data_fake里面都添加noise,让他们的分布具有『不可忽略的重叠部分』。
然后训练一段时间后,逐渐减小noise的比例,降到0的时候,就是原始GAN了。
这就是instance noise,向真实样例里面添加噪声。
//传送门:https://zhuanlan.zhihu.com/p/25071913 作者:郑华滨
2.零均值化的GP(zero-centered gradient penalties)
是指每batch算出来的batch_size个梯度,求个均值,然后每个梯度减去这个均值。
这个我还没搞懂为什么可以带来收敛。
//留坑等补作业
3.一致优化(consensus optimization)
Mescheder 提出来的。
我们前面不是联立了两个项建立了gradient vector field吗?
就是下图的,v(x)=v(Φ,θ)=(一个分块矩阵)

然后
我们希望v(x)=0,也就是两个梯度都等于0,这样lossfunction就达到均衡点了。
这个问题等价于求解minimize L(x)= 1/2 ||v(x)||^2。
等价于求解向量v(x)的2-范数的最小值。

而事实上我们不能在实践中求出L(x)的全局最小值,往往只会达到一些不稳定的点或者其他局部最小值点。
于是就换了个思路来逼近。
先设一个w(x)=v(x)-γ▽L(x)
其中▽L(x)=v'(x)^T *v(x)
这样做的改变,其实等价于在原来的f()和g()后面都加了一项-γ▽L(x)。
然后对f()和g()求梯度,再联立,得到的就是w(x)了。
(不加这项,那么对f和g求梯度再联立,得到的是传统的v(x)了)
图示:
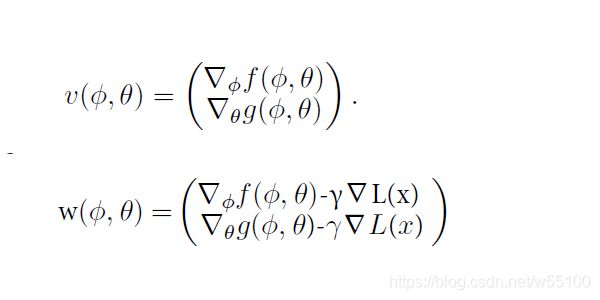
那么我们不断更新w(x)到0的过程中呢,相当于f()和g()达成了一个agreement,就是大家一起让L(x)最小化。
这就是这个方法名字的由来,叫一致优化(consensus optimization)。
直观理解:
通过添加公共优化目标minimize L(x),使得大家意见一致,无需争吵,有共同的立场,共同利益。
显然有共同利益的两个人更容易达成均衡(equilibrium)。
反应在模型上,就是更容易收敛。
介绍到这里,Introduction部分也基本结束了。
Based on our analysis, we give a new explanation for the instabilities commonly observed when training GANs based
on discriminator gradients orthogonal to the tangent space of the data manifold.基于我们的分析,我们对,使用『正交于数据流型的正切空间的』鉴别器梯度( discriminator gradients)来训练GAN时,常见的不稳定现象,给出了新的解释。
//这段看不懂,等补作业
//啥是数据流型的正切空间啊......
We also introduce simplified gradient penalties for which we prove local convergence. We find
that these gradient penalties work well in practice, allowing us to learn high-resolution image based generative models
for a variety of datasets with little hyperparameter tuning.
我们也得出了新的,简化版的梯度惩罚项。
我们发现实践中这个惩罚项效果很好,甚至能用来搞1024*1024的高分辨率图片生成,而几乎不需要调超参数。
然后我们就很好奇,到底是什么梯度惩罚项这么神奇呢,被作者吹成这样。
二、梯度惩罚项
先来看一下前面说的那个雅克比矩阵的特征值。
给定目标函数:

我们取f(t) = -log(1 + exp(-t))
然后作者引入了他自己的Dirac-GAN模型,承载上文说到的那个反例。
然后经过一串数学证明,可以得到这个反例里面的特征值。
Lemma 3.3. The eigenvalues of the Jacobian of the gradient vector field for the gradient-regularized Dirac-GAN at
the equilibrium point are given by
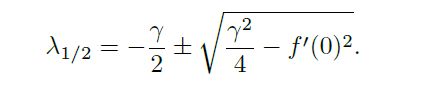
In particular, for > 0 all eigenvalues have negative real part. Hence, simultaneous and alternating gradient descent
are both locally convergent for small enough learning rates.
这个特征值里面,γ(gamma)是一个超参数。
且我们默认f'(x)任意位置都存在定义且不为0。 (不然反向传播就中断了)
显然,只要我们取γ>0,那么特征值就会满足实部为负的条件。
那么只要给的learning rates足够小,模型中联立的、交替的G和D的梯度下降过程,就会一起收敛。
(讲这句话应该是默认了我们调节γ使得后面那个开方项不会开出虚部来)
充分理解了模型的收敛性关系后,作者给出了他的简化版正则项。

//这个正则项是Roth等人2017给出的正则项的改进版本。
//Roth原文传送门:https://arxiv.org/abs/1705.09367
注意ψ是鉴别器D的参数。
这个正则项的简化之处就在于,我们只需要计算对于真实样本Pd(x)来说,E(||▽Dψ(x)||^2),即里面这项的期望值是多少。
1.不需要考虑Generator的参数θ,只关注D。
2.不需要考虑D在x_fake上的表现。
相当于,我们只带D一个人玩,把G丢一个边不管了。
由于只用考虑单目标,单分布(真实图像的分布),运算上确实简便了不少。
更惊为天人的是,如此神奇又简便的正则项,作者一下子发现了俩!

R2和R1的区别就在于,把分布从Pd(x)换成了Pθ(x)。
相当于只惩罚G在x_fake分布上的梯度。
然后......实验证明R1和R2的效果是差不多的!
三、实验效果分析
下面是文章开头的实验数据。a.c. case 代表absolutely continuous case。

1.显然在不一致连续的general case上,经典GAN,WGAN,WGAN-GP,DRA-GAN都不能收敛。
2.哪怕在a.c. case上,WGAN 和 WGAN-GP也不能收敛。
3.带上R1或R2后,这几个模型全收敛了(最后两行)。
我会特别提一下第二句话。
2.哪怕在a.c. case上,WGAN 和 WGAN-GP也不能收敛。
这句话似乎直觉上与我之前了解到的“WGAN乃神人也”矛盾。
然而并不是,这篇文章也解释了我的疑惑。
WGAN的确改进了经典GAN在初期训练的缺点(和下图a比好了很多),最终模型的训练效果也相当好,但是它的“相当好”是一种不稳定的相当好。
文中给了另外一张训练动态图。
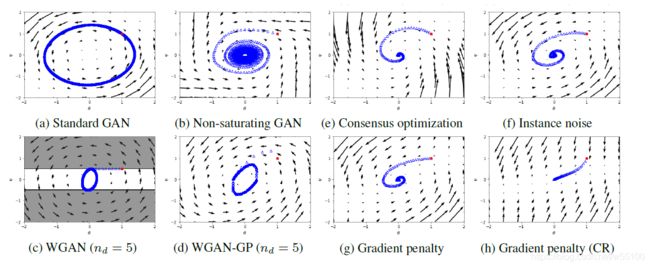
这张图是梯度下降的俯视图。
我们观察c和d就能知道,WGAN和WGAN-GP本质上是围绕着均衡点绕圈圈呢。
所以它的“效果不错”是指“在离均衡点足够近的地方转圈圈”,这样虽然不是locally best,但好歹还good enough。
而g和h是加了R1和R2之后的效果。
CR指的是Critical Regularization,字面意思是最严厉的惩罚。
还记得我们那个可以调节的超参数gamma么?
Like for instance noise, there is a critical regularization parameter
γ_critical = 2|f'(0)| that results in a locally rotation free vector field.
显然在gamma_critical点,令γ=2|f'(0)|,那么雅克比矩阵的特征值,后一项就变成0了。
作者说这样会导致rotation free(不旋转)。
于是我们看到了h图像,真的是不旋转了,一条线走到均衡点。
这可以帮助我们加深对这个特征值的理解。
我们现在已知
1. ||lambda||<1才收敛,越小收敛越快
2.在实际运用中要求lambda有负的实部,这样才会向下收敛,所以我们的超参数gamma>0
3.第二项有更神奇的作用。
->当第二项里面为负数时,开出虚轴来,就不收敛。
->当第二项里面为正数时,模型会收敛,但是会旋转!
->当第二项里面趋向于0正,即整个lambda趋向于贴近虚轴,所需要的达成收敛的学习速率超级超级小。
->当第二项里面恰好等于0,整个模型还是收敛(因为没开出虚轴来),而且不会旋转!
综上呢,我个人觉得可以把第二项命名为旋转项。(当然命名权归功于发现者......)
显然第二项越小,整个lambda会倾向于接近第一项,那么旋转的程度就越低(为0时彻底不旋转)。
而第二项为虚数时,因为虚轴是碰不到的,我们对参数的更新步骤只计算实轴部分,于是模型永远朝着一个错误的方向前进(永远会缺少虚数部分所描述的''方向''信息),所以就开始瞎鸡儿旋转,导致不收敛。
另外非常非常神奇的是!
作者特意提到了R1和R2的任意组合效果都是一样的!!!

就是说,假设你原来的loss function是 J(),
那么你现在把它改成J()+R1,或者是J()+R2,甚至是J()+R1+R2,都没有什么本质区别!!!
甚至可以是J()+αR1+βR2,α与β可以为任意实数,α,β不同时为0!
而且!
虽然上图的g和h是在作者的反例DRA-GAN上做的,
但是作者把结果推向了其他general GANs。
证明了R1和R2这两个惩罚项,可以在Nagarajan的收敛条件之上,进一步扩展到更一般的情形。
即R1和R2,对那些不绝对连续的general distributions具备普适性!

太神奇了!
为什么只需要对鉴别器做惩罚就可以了!
为什么在鉴别器在真实样本和虚假样本上的惩罚效果是一样的!
我尝试做个人的理解。
对真实样本惩罚的时候,是对x的偏导惩罚的。
就是要求我们最终训练出来的参数w,对于Pdata这个分布,导数越小越好。
这个可以理解,我们希望在Pdata上取出来的x任意改变,D给出的打分都是1。
而同理,对Pg上任意取出的x,我们也希望这个x无论向哪边移动,D给出来都是0。
偏导变化越小越好。
这就是惩罚项的内涵。
图示:
没有梯度惩罚时,为了让D(x)与1的平均平方差越接近越好。
是可以采用这种形式的,围绕着目标得分,大幅度改变x的梯度,这样也能达到总和很小的地步。
但是我们不允许存在这种,在Pdata上,随着x的改变得分的梯度这么大的情况。
(后来出现的一些论文,也采取了梯度修剪的思想,不知道是不是这个原理。)
四、正则项的具体计算(代码)
理论再好也要实践,以下代码基于pytorch。(可以跳过研究代码的过程,直接下拉到结果)
先把R1公式摘抄下来,记住φ是D的参数。
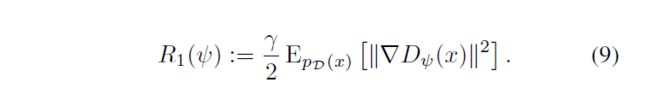
我们把regularization命名为reg
#假设已有(batch_size,1)的打分结果d_real,
#(batch_size,image_dim)的样本束x_real
#基于pytorch
reg = self.reg_param * compute_grad2(d_real, x_real).mean()
return reg.item()
def compute_grad2(d_out, x_in):
batch_size = x_in.size(0)
grad_dout = autograd.grad(
outputs=d_out.sum(), inputs=x_in,
create_graph=True, retain_graph=True, only_inputs=True
)[0]
grad_dout2 = grad_dout.pow(2)
assert(grad_dout2.size() == x_in.size())
reg = grad_dout2.view(batch_size, -1).sum(1)
return reg
//这篇文章介绍了这个autograd.grad()函数https://blog.csdn.net/u010165147/article/details/83994631
autograd.grad()函数是torch内置函数,本意是用来帮你算二阶导的。
你可以输入一个grad_outputs,这个项表示∂(Loss)/∂(outputs),意思是outputs的梯度。
那么程序根据链式求导法则,先算出∂(outputs)/∂(inputs)。
那么return的inputs的梯度∂(Loss)/∂(inputs)=[∂(Loss)/∂(outputs)]*[∂(outputs)/∂(inputs)]
而且这个梯度不会被更新到input.grad中
但是也可以通过指定grad_outputs=None来算一阶导(不指定的情况下默认值也是None)。
这样相当于只计算∂(outputs)/∂(inputs)。
但是一旦grad_outputs==None了,那么outputs就只能是标量了。
grad_dout = autograd.grad(
outputs=d_out.sum(), inputs=x_in,
create_graph=True, retain_graph=True, only_inputs=True
)[0]所以这一句当中,在输入d_out之前,我们要用d_out.sum()把它合成一个标量。sum()也是内置函数,backforward的过程中会自适应求导的,不影响结果。
#grad()函数的返回值是tuple类型,类似下面
(tensor([ 3., 3., 3.]),)所以取[0],这样grad_out就变成一个tensor了,包含对inputs中每一个元素的梯度。
#因为inputs=(batch_size,image_dim)
#所以返回的grad_dout=(1,batch_size x image_dim)
#grad_batch1_x1,grad_batch1_x2,.....,grad_batchm_xn-1,grad_batchm_xn
#对这些梯度求平方
grad_dout2 = grad_dout.pow(2)
#grad_batch1_x1^2,grad_batch2_x2^2,.....,grad_batchm_xn^2
#.view()函数相当于reshape()
#重新变成batch行,每行相当一个sample,含有image_dim个梯度的平方
#grad_x1^2,grad_x2^2,......,grad_xn^2
reg = grad_dout2.view(batch_size, -1).sum(1)
#.sum(1)函数是指按照每行的方向求和
#相当于
#第1行:grad_x1^2+grad_x2^2+......+grad_xn^2
#...
#第batch_size行:...
然后 return reg现在我们知道了,返回值是一个(batch_size ,1)的矩阵。
第i行=第i个sample算出来的梯度平方的和。
#然后根据compute_grad2的返回值,我们mean()一下
reg = self.reg_param * compute_grad2(d_real, x_real).mean()这一步相当于用样本的均值,来估算原分布的期望值。
得到的结果为 Epd(x)[Σ(▽D(x))^2]
写成公式就是下图,从真实图片分布PD(x)中随机提取一个样本x,则该x由image_dim个数值组成。
例如,64x64的RGB图像有64x64x3=12288个数值,对应xi,i∈[1,12288]。
然后计算这些D(x)对xi的梯度,求平方的均值。
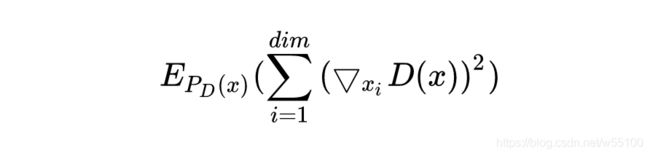
算出来期望之后,乘以self.reg_param,这个其实就是我们设定的超参数gamma/2
我们再来看一眼原公式,哦原来你这个绝对值平方是这个意思啊!!!
......然后我就觉得我很蠢。
以下为结果:
如果把▽D(x)看成一个求梯度后得到的一维向量w=(grad_x1,grad_x2,grad_x3,......)。
那么||▽D(x)||=||w|| = sqrt( grad_x1^2 + grad_x2^2+......+grad_xn^2)
那么||▽D(x)||^2 = grad_x1^2 + grad_x2^2+......+grad_xn^2
这正是我们写出来的公式......
打扰了......
好了,R2的求法完全同理,不再赘述。
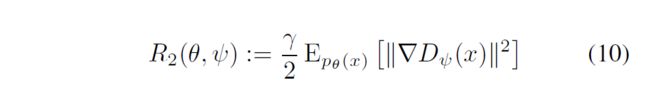
reg = self.reg_param * compute_grad2(d_fake, x_fake).mean()
return reg.item()
def compute_grad2(d_out, x_in):
batch_size = x_in.size(0)
grad_dout = autograd.grad(
outputs=d_out.sum(), inputs=x_in,
create_graph=True, retain_graph=True, only_inputs=True
)[0]
grad_dout2 = grad_dout.pow(2)
assert(grad_dout2.size() == x_in.size())
reg = grad_dout2.view(batch_size, -1).sum(1)
return reg
五、结语
GAN还是个很年轻的模型,14年Goodfellow第一次提出,17、18年逐渐改善了训练的稳定性等问题才开始爆发。
可以说翻译Introduction的时候对GAN领域内16~17年前人如何一步步探寻收敛条件的过程有了基本了解。
这篇论文对几个主流GAN模型都有讨论(basicGAN,WGAN,...),对主流的几个帮助训练的方法也有介绍(instance noise,......),可以说是很好的科普读物。
限制于数学基础,对方法的原理还有待深入理解。
值得注意的是,这篇论文收录于18年1月。
众所周知的是19年出来了一个大力出奇迹的BigGAN。
在BigGAN之前还有SAGAN。
也就是说中间大概一年的时间GAN领域的新内容是这篇论文无法涵盖的,这也是我之后要去了解的。
如果有机会能看到其他覆盖性广的好论文,再做分享。
19.03.03